import os
import pprint
import numpy as np
from math import inf
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torch.utils.data import random_split
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from spotpython.utils.file import (load_experiment, load_result, get_experiment_filename, load_and_run_spot_python_experiment)
from spotpython.spot import Spot
from spotpython.utils.init import (
fun_control_init,
design_control_init,
surrogate_control_init,
optimizer_control_init)
from spotpython.fun.objectivefunctions import Analytical
from spotpython.hyperparameters.values import get_tuned_hyperparameters
from spotpython.data.diabetes import Diabetes
from spotpython.hyperdict.light_hyper_dict import LightHyperDict
from spotpython.fun.hyperlight import HyperLight
from spotpython.utils.eda import print_exp_table
from spotpython.hyperparameters.values import set_hyperparameter, get_tuned_architecture
from spotpython.light.testmodel import test_model
from spotpython.light.loadmodel import load_light_from_checkpoint
from spotpython.utils.device import getDevice
from spotpython.utils.classes import get_removed_attributes_and_base_net
from spotpython.hyperparameters.optimizer import optimizer_handler57 Saving and Loading
This tutorial shows how to save and load objects in spotpython. It is split into the following parts:
- Section 57.3 shows how to save and load objects in
spotpython, ifspotpythonis used as an optimizer. - Section 57.4 shows how to save and load hyperparameter tuning experiments.
- Section 57.5 shows how to save and load
PyTorch Lightningmodels. - Section 57.6 shows how to convert a
PyTorch Lightningmodel to a plainPyTorchmodel.
57.1 Required Python Packages
And we will suppress warnings in this notebook.
57.2 Quick Overview of spotpython Save and Load Functions
Because the most common use case is to save and load hyperparameter tuning experiments, the save_experiment and load_experiment functions are explained first. In the real- world setting, users specify an experiment on their local machine and then run the experiment on a remote machine. Then, the result file is copied back to the local machine and loaded for further analysis. So, the main steps can be summarized as follows:
- Generate an experiment configuration on the local machine, say
42_exp.pkl. To generate the configuration, thefun_controldictionary has to be initialized withsave_experiment=True. - Copy the configuration file to the remote machine.
- Run the experiment on the remote machine. The run on the remote machine is started with the command
load_and_run_spot_python_experiment(filename="42_exp.pkl"). This generates a result file, say42_res.pkl. - Copy the result file back to the local machine. Analyze the results on the local machine as shown below.
As can be seen from these step, we will distinguish between experiment/design/configuration files (with _exp in the filename) and result files (with _res in the filename).
Example 57.1 (Save and Load Hyperparameter Tuning Experiment)
- Generate an experiment configuration on the local machine, say
42_exp.pklas follows:
PREFIX = "42"
data_set = Diabetes()
fun_control = fun_control_init(
save_experiment=True,
PREFIX=PREFIX,
fun_evals=inf,
max_time=1,
data_set = data_set,
core_model_name="light.regression.NNLinearRegressor",
hyperdict=LightHyperDict,
_L_in=10,
_L_out=1)
fun = HyperLight().fun
set_hyperparameter(fun_control, "optimizer", [ "Adadelta", "Adam", "Adamax"])
set_hyperparameter(fun_control, "l1", [3,4])
set_hyperparameter(fun_control, "epochs", [3,5])
set_hyperparameter(fun_control, "batch_size", [4,11])
set_hyperparameter(fun_control, "dropout_prob", [0.0, 0.025])
set_hyperparameter(fun_control, "patience", [2,3])
design_control = design_control_init(init_size=10)
print_exp_table(fun_control)
S = Spot(fun=fun,fun_control=fun_control, design_control=design_control)module_name: light
submodule_name: regression
model_name: NNLinearRegressor
| name | type | default | lower | upper | transform |
|----------------|--------|-----------|---------|---------|-----------------------|
| l1 | int | 3 | 3 | 4 | transform_power_2_int |
| epochs | int | 4 | 3 | 5 | transform_power_2_int |
| batch_size | int | 4 | 4 | 11 | transform_power_2_int |
| act_fn | factor | ReLU | 0 | 5 | None |
| optimizer | factor | SGD | 0 | 2 | None |
| dropout_prob | float | 0.01 | 0 | 0.025 | None |
| lr_mult | float | 1.0 | 0.1 | 10 | None |
| patience | int | 2 | 2 | 3 | transform_power_2_int |
| batch_norm | factor | 0 | 0 | 1 | None |
| initialization | factor | Default | 0 | 4 | None |
Experiment saved to 42_exp.pklAs the output shows, the configuration is saved as a pickle-file that contains the full information. In our example, the filename is 42_exp.pkl.
Copy the configuration file to the remote machine. This can be done with the
scpcommand, see below, but is omitted here for brevity.Run the experiment on the remote machine. This step is simulated on the local machine for demonstration purposes. This generates a result file, say
42_res.pkl. This can be done with the following code:
# S_res = S.run() is NOT used here, because we want to simulate the remote run
# Instead, we use the load_and_run_spot_python_experiment function:
S_remote = load_and_run_spot_python_experiment(filename="42_exp.pkl")Loaded experiment from 42_exp.pkl┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 23075.09765625, 'hp_metric': 23075.09765625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 3850.81201171875, 'hp_metric': 3850.81201171875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 6251.13916015625, 'hp_metric': 6251.13916015625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 24093.25390625, 'hp_metric': 24093.25390625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 23622.310546875, 'hp_metric': 23622.310546875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3700.771728515625, 'hp_metric': 3700.771728515625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 20202.96875, 'hp_metric': 20202.96875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 14795.3359375, 'hp_metric': 14795.3359375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 13.1 M
train_model result: {'val_loss': 21675.736328125, 'hp_metric': 21675.736328125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 413 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 413 M
train_model result: {'val_loss': 23792.47265625, 'hp_metric': 23792.47265625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 23473.31640625, 'hp_metric': 23473.31640625}
spotpython tuning: 3700.771728515625 [----------] 3.09%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 21453.419921875, 'hp_metric': 21453.419921875}
spotpython tuning: 3700.771728515625 [#---------] 5.34%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 16605.611328125, 'hp_metric': 16605.611328125}
spotpython tuning: 3700.771728515625 [#---------] 6.42%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 4418.7109375, 'hp_metric': 4418.7109375}
spotpython tuning: 3700.771728515625 [#---------] 7.86%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 19324.853515625, 'hp_metric': 19324.853515625}
spotpython tuning: 3700.771728515625 [#---------] 8.99%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 23236.640625, 'hp_metric': 23236.640625}
spotpython tuning: 3700.771728515625 [#---------] 10.29%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 23883.439453125, 'hp_metric': 23883.439453125}
spotpython tuning: 3700.771728515625 [#---------] 12.89%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 12952.9296875, 'hp_metric': 12952.9296875}
spotpython tuning: 3700.771728515625 [##--------] 15.36%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 23691.73046875, 'hp_metric': 23691.73046875}
spotpython tuning: 3700.771728515625 [##--------] 16.51%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 5191.41650390625, 'hp_metric': 5191.41650390625}
spotpython tuning: 3700.771728515625 [##--------] 19.15%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 15954.0634765625, 'hp_metric': 15954.0634765625}
spotpython tuning: 3700.771728515625 [##--------] 20.78%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 23493.109375, 'hp_metric': 23493.109375}
spotpython tuning: 3700.771728515625 [##--------] 22.95%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 23837.33984375, 'hp_metric': 23837.33984375}
spotpython tuning: 3700.771728515625 [##--------] 24.30%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': 17594.4921875, 'hp_metric': 17594.4921875}
spotpython tuning: 3700.771728515625 [###-------] 25.40%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 13.1 M
train_model result: {'val_loss': 23908.48828125, 'hp_metric': 23908.48828125}
spotpython tuning: 3700.771728515625 [###-------] 26.72%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 24016.99609375, 'hp_metric': 24016.99609375}
spotpython tuning: 3700.771728515625 [###-------] 27.78%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 24098.27734375, 'hp_metric': 24098.27734375}
spotpython tuning: 3700.771728515625 [###-------] 28.72%. Success rate: 0.00% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 23996.900390625, 'hp_metric': 23996.900390625}
spotpython tuning: 3700.771728515625 [###-------] 30.01%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 10241.0615234375, 'hp_metric': 10241.0615234375}
spotpython tuning: 3700.771728515625 [###-------] 32.49%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 19619.40625, 'hp_metric': 19619.40625}
spotpython tuning: 3700.771728515625 [###-------] 33.82%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 20175.65234375, 'hp_metric': 20175.65234375}
spotpython tuning: 3700.771728515625 [####------] 35.39%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 12377.2626953125, 'hp_metric': 12377.2626953125}
spotpython tuning: 3700.771728515625 [####------] 39.05%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 22732.955078125, 'hp_metric': 22732.955078125}
spotpython tuning: 3700.771728515625 [####------] 40.67%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 23719.169921875, 'hp_metric': 23719.169921875}
spotpython tuning: 3700.771728515625 [#####-----] 45.01%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 17149.6484375, 'hp_metric': 17149.6484375}
spotpython tuning: 3700.771728515625 [#####-----] 46.35%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 16395.931640625, 'hp_metric': 16395.931640625}
spotpython tuning: 3700.771728515625 [#####-----] 47.55%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 23803.443359375, 'hp_metric': 23803.443359375}
spotpython tuning: 3700.771728515625 [#####-----] 49.12%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 23311.802734375, 'hp_metric': 23311.802734375}
spotpython tuning: 3700.771728515625 [#####-----] 52.21%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 23695.421875, 'hp_metric': 23695.421875}
spotpython tuning: 3700.771728515625 [#####-----] 54.21%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': 23479.724609375, 'hp_metric': 23479.724609375}
spotpython tuning: 3700.771728515625 [######----] 56.01%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 19671.98046875, 'hp_metric': 19671.98046875}
spotpython tuning: 3700.771728515625 [######----] 57.41%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 23461.787109375, 'hp_metric': 23461.787109375}
spotpython tuning: 3700.771728515625 [######----] 59.15%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 16165.0400390625, 'hp_metric': 16165.0400390625}
spotpython tuning: 3700.771728515625 [######----] 61.04%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 8532.5380859375, 'hp_metric': 8532.5380859375}
spotpython tuning: 3700.771728515625 [######----] 62.40%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [######----] 63.50%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [######----] 64.51%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 65.53%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 66.55%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 67.53%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 68.62%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 69.61%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 70.66%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 71.71%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 72.72%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 73.81%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 74.82%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 75.81%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 76.80%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 77.82%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 78.83%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 79.84%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 80.85%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 81.92%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 83.00%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 84.01%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 85.01%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 86.06%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 87.04%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 88.05%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 89.12%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 90.14%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 91.17%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 92.16%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 93.22%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 94.29%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 95.29%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 96.28%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 97.34%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 98.33%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 99.39%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 100.00%. Success rate: 0.00% Done...
Experiment saved to 42_res.pklA result file with the name 42_res.pkl is stored in the current directory.
- Copy the result file back to the local machine. This can be done with the
scpcommand, see below, but is omitted here for brevity. The result file can be loaded with the following code:
S_res = load_result(PREFIX="42")Loaded experiment from 42_res.pklS_res.plot_progress(log_y=True)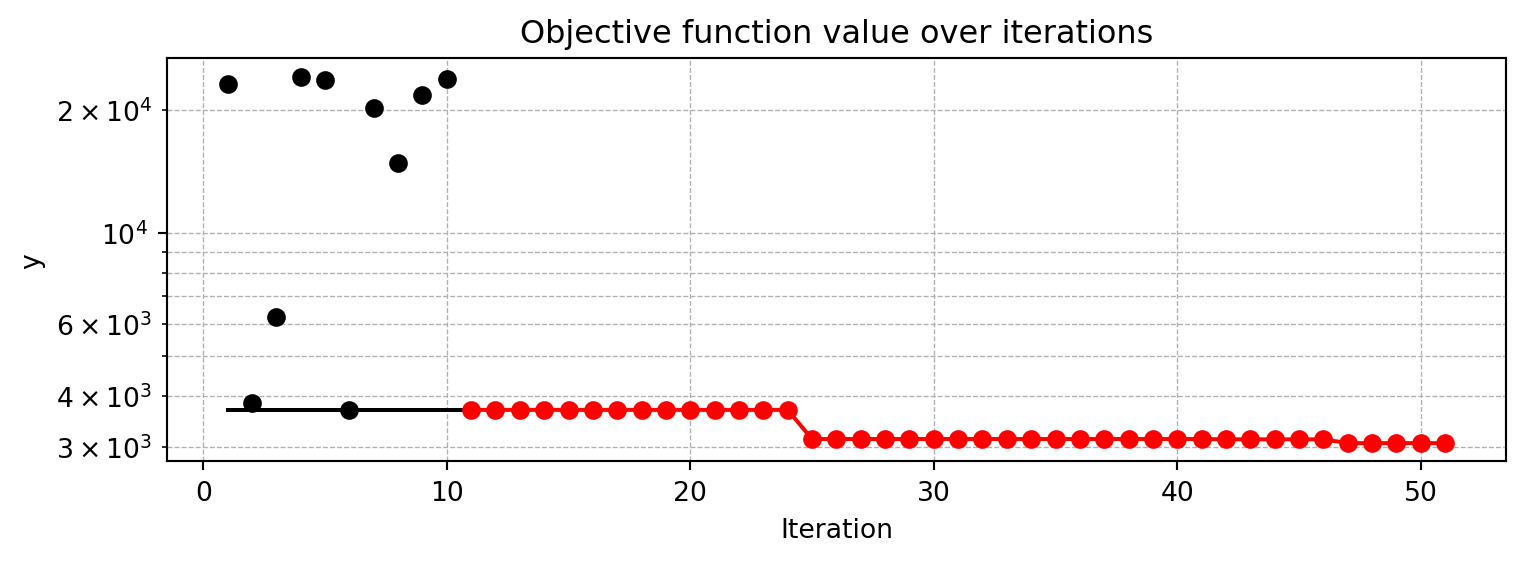
S_res.print_results()min y: 3700.771728515625
l1: 4.0
epochs: 4.0
batch_size: 5.0
act_fn: 3.0
optimizer: 2.0
dropout_prob: 0.023931753071792624
lr_mult: 1.2532486761645163
patience: 3.0
batch_norm: 0.0
initialization: 4.0[['l1', np.float64(4.0)],
['epochs', np.float64(4.0)],
['batch_size', np.float64(5.0)],
['act_fn', np.float64(3.0)],
['optimizer', np.float64(2.0)],
['dropout_prob', np.float64(0.023931753071792624)],
['lr_mult', np.float64(1.2532486761645163)],
['patience', np.float64(3.0)],
['batch_norm', np.float64(0.0)],
['initialization', np.float64(4.0)]]If you add fun_control=S_res.fun_control as an argument to the get_tuned_hyperparameters function, the names of the hyperparameters are used as keys in the dictionary.
get_tuned_hyperparameters(S_res, fun_control=S_res.fun_control){'l1': np.float64(4.0),
'epochs': np.float64(4.0),
'batch_size': np.float64(5.0),
'act_fn': 'LeakyReLU',
'optimizer': 'Adamax',
'dropout_prob': np.float64(0.023931753071792624),
'lr_mult': np.float64(1.2532486761645163),
'patience': np.float64(3.0),
'batch_norm': 0,
'initialization': 'xavier_normal'}Get the transformed hyperparameters that can be passed to the model.
config = get_tuned_architecture(S_res)
pprint.pprint(config){'act_fn': LeakyReLU(),
'batch_norm': False,
'batch_size': 32,
'dropout_prob': 0.023931753071792624,
'epochs': 16,
'initialization': 'xavier_normal',
'l1': 16,
'lr_mult': 1.2532486761645163,
'optimizer': 'Adamax',
'patience': 8}After getting the tuned architecture, the model can be created and tested with the following code.
test_model(config, S_res.fun_control)┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ hp_metric │ 4980.21484375 │ │ val_loss │ 4980.21484375 │ └───────────────────────────┴───────────────────────────┘
test_model result: {'val_loss': 4980.21484375, 'hp_metric': 4980.21484375}(4980.21484375, 4980.21484375)S_res.plot_important_hyperparameter_contour(max_imp=3)l1: 0.001
epochs: 0.001
batch_size: 0.001
act_fn: 100.0
optimizer: 50.92590151644171
dropout_prob: 0.001
lr_mult: 0.12004514691831451
patience: 0.001
batch_norm: 0.001
initialization: 0.3107636463812971
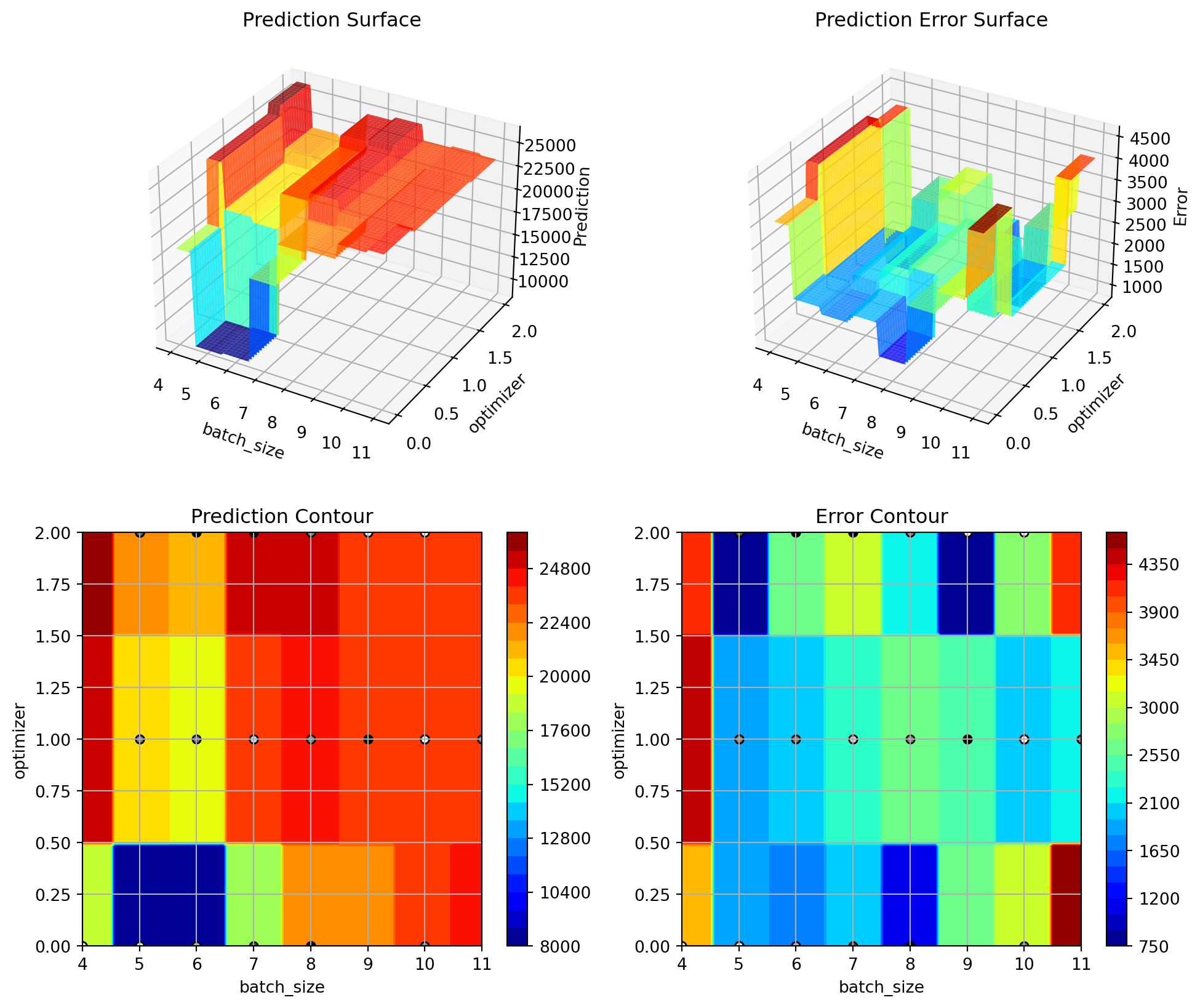
S_res.plot_importance()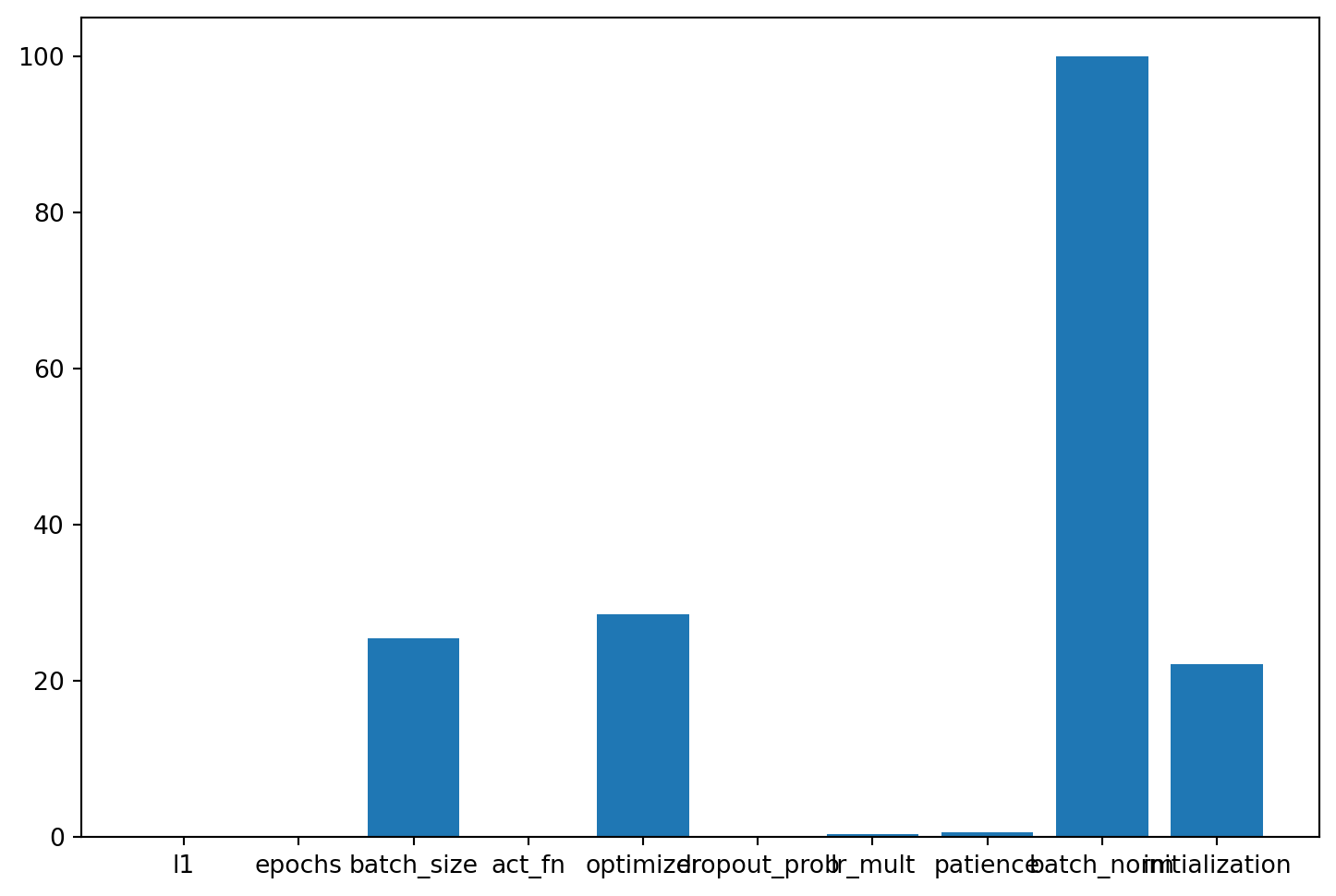
57.3 spotpython: Saving and Loading Optimization Experiments
In this section, we will show how results from spotpython can be saved and reloaded. Here, spotpython can be used as an optimizer. If spotpython is used as an optimizer, no dictionary of hyperparameters has be specified. The fun_control dictionary is sufficient.
PREFIX="branin"
fun = Analytical().fun_branin
fun_control = fun_control_init(
PREFIX=PREFIX,
lower = np.array([0, 0]),
upper = np.array([10, 10]),
fun_evals=8,
fun_repeats=1,
max_time=inf,
noise=False,
tolerance_x=0,
ocba_delta=0,
var_type=["num", "num"],
infill_criterion="ei",
n_points=1,
seed=123,
log_level=20,
show_models=False,
save_experiment=True,
show_progress=True)
design_control = design_control_init(
init_size=5,
repeats=1)
surrogate_control = surrogate_control_init(
model_fun_evals=10000,
min_theta=-3,
max_theta=3,
theta_init_zero=True,
n_p=1,
optim_p=False,
var_type=["num", "num"],
seed=124)
optimizer_control = optimizer_control_init(
max_iter=1000,
seed=125)
S = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control,
surrogate_control=surrogate_control,
optimizer_control=optimizer_control)
S.run()Experiment saved to branin_exp.pkl
spotpython tuning: 4.7932399644479124 [########--] 75.00%. Success rate: 0.00%
spotpython tuning: 2.124848972105818 [#########-] 87.50%. Success rate: 50.00%
spotpython tuning: 2.124848972105818 [##########] 100.00%. Success rate: 33.33% Done...
Experiment saved to branin_res.pkl<spotpython.spot.spot.Spot at 0x31e2dac10>S_exp = load_experiment(PREFIX=PREFIX)Loaded experiment from branin_exp.pklS_res = load_result(PREFIX=PREFIX)Loaded experiment from branin_res.pklThe progress of the original experiment is shown in Figure 57.1 and the reloaded experiment in Figure 57.2.
S.plot_progress(log_y=True)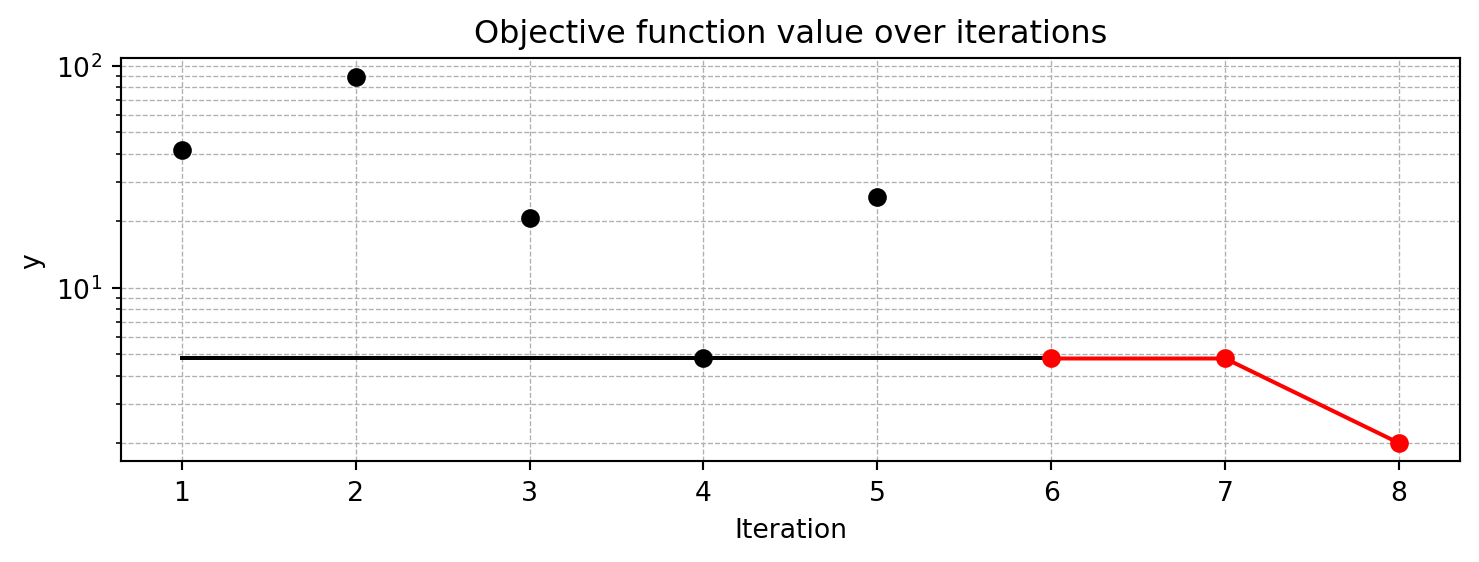
S_res.plot_progress(log_y=True)
The results from the original experiment are shown in Table 57.1 and the reloaded experiment in Table 57.2.
S.print_results()min y: 2.124848972105818
x0: 10.0
x1: 2.576684029008911[['x0', np.float64(10.0)], ['x1', np.float64(2.576684029008911)]]S_res.print_results()min y: 2.124848972105818
x0: 10.0
x1: 2.576684029008911[['x0', np.float64(10.0)], ['x1', np.float64(2.576684029008911)]]57.3.1 Getting the Tuned Hyperparameters
The tuned hyperparameters can be obtained as a dictionary with the following code. Since spotpython is used as an optimizer, the numerical levels of the hyperparameters are identical to the optimized values of the underlying optimization problem, here: the Branin function.
get_tuned_hyperparameters(spot_tuner=S_res){'x0': np.float64(10.0), 'x1': np.float64(2.576684029008911)}
NoteSummary: Saving and Loading Optimization Experiments
- If
spotpythonis used as an optimizer (without an hyperparameter dictionary), experiments can be saved and reloaded with thesave_experimentandload_experimentfunctions. - The tuned hyperparameters can be obtained with the
get_tuned_hyperparametersfunction.
57.4 spotpython as a Hyperparameter Tuner
If spotpython is used as a hyperparameter tuner, in addition to the fun_control dictionary a core_model dictionary has to be specified. Furthermore, a data set has to be selected and added to the fun_control dictionary. Here, we will use the Diabetes data set.
57.4.1 The Diabetes Data Set
The hyperparameter tuning of a PyTorch Lightning network on the Diabetes data set is used as an example. The Diabetes data set is a PyTorch Dataset for regression, which originates from the scikit-learn package, see https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html#sklearn.datasets.load_diabetes.
Ten baseline variables, age, sex, body mass index, average blood pressure, and six blood serum measurements were obtained for each of n = 442 diabetes patients, as well as the response of interest, a quantitative measure of disease progression one year after baseline. The Diabetes data set is has the following properties:
- Samples total: 442
- Dimensionality: 10
- Features: real, \(-.2 < x < .2\)
- Targets: integer \(25 - 346\)
data_set = Diabetes()PREFIX="604"
fun_control = fun_control_init(
save_experiment=True,
PREFIX=PREFIX,
fun_evals=inf,
max_time=1,
data_set = data_set,
core_model_name="light.regression.NNLinearRegressor",
hyperdict=LightHyperDict,
_L_in=10,
_L_out=1)
fun = HyperLight().fun
set_hyperparameter(fun_control, "optimizer", [ "Adadelta", "Adam", "Adamax"])
set_hyperparameter(fun_control, "l1", [3,4])
set_hyperparameter(fun_control, "epochs", [3,5])
set_hyperparameter(fun_control, "batch_size", [4,11])
set_hyperparameter(fun_control, "dropout_prob", [0.0, 0.025])
set_hyperparameter(fun_control, "patience", [2,3])
design_control = design_control_init(init_size=10)
print_exp_table(fun_control)module_name: light
submodule_name: regression
model_name: NNLinearRegressor
| name | type | default | lower | upper | transform |
|----------------|--------|-----------|---------|---------|-----------------------|
| l1 | int | 3 | 3 | 4 | transform_power_2_int |
| epochs | int | 4 | 3 | 5 | transform_power_2_int |
| batch_size | int | 4 | 4 | 11 | transform_power_2_int |
| act_fn | factor | ReLU | 0 | 5 | None |
| optimizer | factor | SGD | 0 | 2 | None |
| dropout_prob | float | 0.01 | 0 | 0.025 | None |
| lr_mult | float | 1.0 | 0.1 | 10 | None |
| patience | int | 2 | 2 | 3 | transform_power_2_int |
| batch_norm | factor | 0 | 0 | 1 | None |
| initialization | factor | Default | 0 | 4 | None |In contrast to the default setting, where save_experiment is set to False, here the fun_control dictionary is initialized save_experiment=True. Alternatively, an existing fun_control dictionary can be updated with {"save_experiment": True} as shown in the following code.
fun_control.update({"save_experiment": True})If save_experiment is set to True, the results of the hyperparameter tuning experiment are stored in a pickle file with the name PREFIX after the tuning is finished in the current directory.
Alternatively, the spot object and the corresponding dictionaries can be saved with the save_experiment method, which is part of the spot object. Therefore, the spot object has to be created as shown in the following code.
S_diabetes = Spot(fun=fun,fun_control=fun_control, design_control=design_control)
S_diabetes.save_experiment(path="userExperiment", overwrite=False)Experiment saved to 604_exp.pkl
Error: File userExperiment/604_exp.pkl already exists. Use overwrite=True to overwrite the file.Here, we have added a path argument to specify the directory where the experiment is saved. The resulting pickle file can be copied to another directory or computer and reloaded with the load_experiment function. It can also be used for performing the tuning run. Here, we will execute the tuning run on the local machine, which can be done with the following code.
S_diabetes_res = S_diabetes.run()┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 23075.09765625, 'hp_metric': 23075.09765625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 3850.81201171875, 'hp_metric': 3850.81201171875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 6251.13916015625, 'hp_metric': 6251.13916015625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 24093.25390625, 'hp_metric': 24093.25390625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 23622.310546875, 'hp_metric': 23622.310546875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3700.771728515625, 'hp_metric': 3700.771728515625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 20202.96875, 'hp_metric': 20202.96875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 14795.3359375, 'hp_metric': 14795.3359375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 13.1 M
train_model result: {'val_loss': 21675.736328125, 'hp_metric': 21675.736328125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 413 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 413 M
train_model result: {'val_loss': 23792.47265625, 'hp_metric': 23792.47265625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 23473.31640625, 'hp_metric': 23473.31640625}
spotpython tuning: 3700.771728515625 [----------] 3.09%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 21453.419921875, 'hp_metric': 21453.419921875}
spotpython tuning: 3700.771728515625 [#---------] 5.32%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 16605.611328125, 'hp_metric': 16605.611328125}
spotpython tuning: 3700.771728515625 [#---------] 6.25%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 4418.7109375, 'hp_metric': 4418.7109375}
spotpython tuning: 3700.771728515625 [#---------] 7.65%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 19324.853515625, 'hp_metric': 19324.853515625}
spotpython tuning: 3700.771728515625 [#---------] 8.76%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 23236.640625, 'hp_metric': 23236.640625}
spotpython tuning: 3700.771728515625 [#---------] 10.03%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 23883.439453125, 'hp_metric': 23883.439453125}
spotpython tuning: 3700.771728515625 [#---------] 12.50%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 12952.9296875, 'hp_metric': 12952.9296875}
spotpython tuning: 3700.771728515625 [#---------] 14.92%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 23691.73046875, 'hp_metric': 23691.73046875}
spotpython tuning: 3700.771728515625 [##--------] 16.05%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 5191.41650390625, 'hp_metric': 5191.41650390625}
spotpython tuning: 3700.771728515625 [##--------] 18.69%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 15954.0634765625, 'hp_metric': 15954.0634765625}
spotpython tuning: 3700.771728515625 [##--------] 20.32%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 23493.109375, 'hp_metric': 23493.109375}
spotpython tuning: 3700.771728515625 [##--------] 22.48%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 23837.33984375, 'hp_metric': 23837.33984375}
spotpython tuning: 3700.771728515625 [##--------] 23.80%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': 17594.4921875, 'hp_metric': 17594.4921875}
spotpython tuning: 3700.771728515625 [##--------] 24.88%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 13.1 M
train_model result: {'val_loss': 23908.48828125, 'hp_metric': 23908.48828125}
spotpython tuning: 3700.771728515625 [###-------] 26.17%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 24016.99609375, 'hp_metric': 24016.99609375}
spotpython tuning: 3700.771728515625 [###-------] 27.23%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 24098.27734375, 'hp_metric': 24098.27734375}
spotpython tuning: 3700.771728515625 [###-------] 28.17%. Success rate: 0.00% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 23996.900390625, 'hp_metric': 23996.900390625}
spotpython tuning: 3700.771728515625 [###-------] 29.48%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 10241.0615234375, 'hp_metric': 10241.0615234375}
spotpython tuning: 3700.771728515625 [###-------] 31.94%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 19619.40625, 'hp_metric': 19619.40625}
spotpython tuning: 3700.771728515625 [###-------] 33.27%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 20175.65234375, 'hp_metric': 20175.65234375}
spotpython tuning: 3700.771728515625 [###-------] 34.69%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 12377.2626953125, 'hp_metric': 12377.2626953125}
spotpython tuning: 3700.771728515625 [####------] 38.32%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 22732.955078125, 'hp_metric': 22732.955078125}
spotpython tuning: 3700.771728515625 [####------] 39.93%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 23719.169921875, 'hp_metric': 23719.169921875}
spotpython tuning: 3700.771728515625 [####------] 44.26%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 17149.6484375, 'hp_metric': 17149.6484375}
spotpython tuning: 3700.771728515625 [#####-----] 45.57%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 16395.931640625, 'hp_metric': 16395.931640625}
spotpython tuning: 3700.771728515625 [#####-----] 46.78%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 23803.443359375, 'hp_metric': 23803.443359375}
spotpython tuning: 3700.771728515625 [#####-----] 48.34%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 23311.802734375, 'hp_metric': 23311.802734375}
spotpython tuning: 3700.771728515625 [#####-----] 51.47%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 23695.421875, 'hp_metric': 23695.421875}
spotpython tuning: 3700.771728515625 [#####-----] 53.48%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': 23479.724609375, 'hp_metric': 23479.724609375}
spotpython tuning: 3700.771728515625 [######----] 55.26%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 19671.98046875, 'hp_metric': 19671.98046875}
spotpython tuning: 3700.771728515625 [######----] 56.62%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 23461.787109375, 'hp_metric': 23461.787109375}
spotpython tuning: 3700.771728515625 [######----] 58.32%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 16165.0400390625, 'hp_metric': 16165.0400390625}
spotpython tuning: 3700.771728515625 [######----] 60.17%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 8532.5380859375, 'hp_metric': 8532.5380859375}
spotpython tuning: 3700.771728515625 [######----] 61.52%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [######----] 62.57%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [######----] 63.56%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [######----] 64.54%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 65.53%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 66.52%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 67.61%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 68.59%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 69.64%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 70.69%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 71.69%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 72.74%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 73.72%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#######---] 74.71%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 75.69%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 76.72%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 77.70%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 78.68%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 79.68%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 80.72%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 81.77%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 82.75%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 83.73%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [########--] 84.78%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 85.77%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 86.76%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 87.81%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 88.79%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 89.78%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 90.76%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 91.81%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 92.86%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 93.85%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [#########-] 94.83%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 95.88%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 96.86%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 97.89%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 98.95%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 99.99%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 3700.771728515625 [##########] 100.00%. Success rate: 0.00% Done...
Experiment saved to 604_res.pklAfter the tuning run is finished, a pickle file with the name spot_604_experiment.pickle is stored in the local directory. This is a result of setting the save_experiment argument to True in the fun_control dictionary. We can load the experiment with the following code. Here, we have specified the PREFIX as an argument to the load_experiment function. Alternatively, the filename (filename) can be used as an argument.
S_diabetes_load_exp = load_experiment(PREFIX=PREFIX)
S_diabetes_load_res = load_result(PREFIX=PREFIX)Loaded experiment from 604_exp.pkl
Loaded experiment from 604_res.pklFor comparison, the tuned hyperparameters of the original experiment are shown first:
get_tuned_hyperparameters(S_diabetes, fun_control){'l1': np.float64(4.0),
'epochs': np.float64(4.0),
'batch_size': np.float64(5.0),
'act_fn': 'LeakyReLU',
'optimizer': 'Adamax',
'dropout_prob': np.float64(0.023931753071792624),
'lr_mult': np.float64(1.2532486761645163),
'patience': np.float64(3.0),
'batch_norm': 0,
'initialization': 'xavier_normal'}Second, the tuned hyperparameters of the reloaded experiment are shown:
get_tuned_hyperparameters(S_diabetes_load_res){'l1': np.float64(4.0),
'epochs': np.float64(4.0),
'batch_size': np.float64(5.0),
'act_fn': np.float64(3.0),
'optimizer': np.float64(2.0),
'dropout_prob': np.float64(0.023931753071792624),
'lr_mult': np.float64(1.2532486761645163),
'patience': np.float64(3.0),
'batch_norm': np.float64(0.0),
'initialization': np.float64(4.0)}Note: The numerical levels of the hyperparameters are used as keys in the dictionary. If the fun_control dictionary is used, the names of the hyperparameters are used as keys in the dictionary.
get_tuned_hyperparameters(S_diabetes_load_res, fun_control=S_diabetes_load_exp.fun_control){'l1': np.float64(4.0),
'epochs': np.float64(4.0),
'batch_size': np.float64(5.0),
'act_fn': 'LeakyReLU',
'optimizer': 'Adamax',
'dropout_prob': np.float64(0.023931753071792624),
'lr_mult': np.float64(1.2532486761645163),
'patience': np.float64(3.0),
'batch_norm': 0,
'initialization': 'xavier_normal'}Plot the progress of the original experiment are identical to the reloaded experiment.
S_diabetes.plot_progress()
S_diabetes_load_res.plot_progress()
NoteSummary: Saving and Loading Hyperparameter-Tuning Experiments
- If
spotpythonis used as an hyperparameter tuner (with an hyperparameter dictionary), experiments can be saved and reloaded with thesave_experimentandload_experimentfunctions. - The tuned hyperparameters can be obtained with the
get_tuned_hyperparametersfunction.
57.5 Saving and Loading PyTorch Lightning Models
Section 57.3 and Section 57.4 explained how to save and load optimization and hyperparameter tuning experiments and how to get the tuned hyperparameters as a dictionary. This section shows how to save and load PyTorch Lightning models.
57.5.1 Get the Tuned Architecture
In contrast to the function get_tuned_hyperparameters, the function get_tuned_architecture returns the tuned architecture of the model as a dictionary. Here, the transformations are already applied to the numerical levels of the hyperparameters and the encoding (and types) are the original types of the hyperparameters used by the model. Important: The config dictionary from get_tuned_architecture can be passed to the model without any modifications.
config = get_tuned_architecture(S_diabetes)
pprint.pprint(config){'act_fn': LeakyReLU(),
'batch_norm': False,
'batch_size': 32,
'dropout_prob': 0.023931753071792624,
'epochs': 16,
'initialization': 'xavier_normal',
'l1': 16,
'lr_mult': 1.2532486761645163,
'optimizer': 'Adamax',
'patience': 8}After getting the tuned architecture, the model can be created and tested with the following code.
test_model(config, fun_control)┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ hp_metric │ 4937.83935546875 │ │ val_loss │ 4937.83935546875 │ └───────────────────────────┴───────────────────────────┘
test_model result: {'val_loss': 4937.83935546875, 'hp_metric': 4937.83935546875}(4937.83935546875, 4937.83935546875)57.5.2 Load a Model from Checkpoint
The method load_light_from_checkpoint loads a model from a checkpoint file. Important: The model has to be trained before the checkpoint is loaded. As shown here, loading a model with trained weights is possible, but requires two steps:
- The model weights have to be learned using
test_model. Thetest_modelmethod writes a checkpoint file. - The model has to be loaded from the checkpoint file.
57.5.2.1 Details About the load_light_from_checkpoint Method
- The
test_modelmethod saves the last checkpoint to a file using the following code:
ModelCheckpoint(
dirpath=os.path.join(fun_control["CHECKPOINT_PATH"], config_id), save_last=True
), The filename of the last checkpoint has a specific structure:
- A
config_idis generated from theconfigdictionary. It does not use a timestamp. This differs from the config id generated in cvmodel.py and trainmodel.py, which provide time information for the TensorBoard logging. - Furthermore, the postfix
_TESTis added to theconfig_idto indicate that the model is tested. - For example:
runs/saved_models/16_16_64_LeakyReLU_Adadelta_0.0014_8.5895_8_False_kaiming_uniform_TEST/last.ckpt
model_loaded = load_light_from_checkpoint(config, fun_control)config: {'l1': 16, 'epochs': 16, 'batch_size': 32, 'act_fn': LeakyReLU(), 'optimizer': 'Adamax', 'dropout_prob': 0.023931753071792624, 'lr_mult': 1.2532486761645163, 'patience': 8, 'batch_norm': False, 'initialization': 'xavier_normal'}
Loading model with 16_16_32_LeakyReLU_Adamax_0.0239_1.2532_8_False_xavier_normal_TEST from runs/saved_models/16_16_32_LeakyReLU_Adamax_0.0239_1.2532_8_False_xavier_normal_TEST/last.ckpt
Model: NNLinearRegressor(
(layers): Sequential(
(0): Linear(in_features=10, out_features=320, bias=True)
(1): LeakyReLU()
(2): Dropout(p=0.023931753071792624, inplace=False)
(3): Linear(in_features=320, out_features=160, bias=True)
(4): LeakyReLU()
(5): Dropout(p=0.023931753071792624, inplace=False)
(6): Linear(in_features=160, out_features=320, bias=True)
(7): LeakyReLU()
(8): Dropout(p=0.023931753071792624, inplace=False)
(9): Linear(in_features=320, out_features=160, bias=True)
(10): LeakyReLU()
(11): Dropout(p=0.023931753071792624, inplace=False)
(12): Linear(in_features=160, out_features=160, bias=True)
(13): LeakyReLU()
(14): Dropout(p=0.023931753071792624, inplace=False)
(15): Linear(in_features=160, out_features=80, bias=True)
(16): LeakyReLU()
(17): Dropout(p=0.023931753071792624, inplace=False)
(18): Linear(in_features=80, out_features=80, bias=True)
(19): LeakyReLU()
(20): Dropout(p=0.023931753071792624, inplace=False)
(21): Linear(in_features=80, out_features=1, bias=True)
)
)vars(model_loaded){'training': False,
'_parameters': {},
'_buffers': {},
'_non_persistent_buffers_set': set(),
'_backward_pre_hooks': OrderedDict(),
'_backward_hooks': OrderedDict(),
'_is_full_backward_hook': None,
'_forward_hooks': OrderedDict(),
'_forward_hooks_with_kwargs': OrderedDict(),
'_forward_hooks_always_called': OrderedDict(),
'_forward_pre_hooks': OrderedDict(),
'_forward_pre_hooks_with_kwargs': OrderedDict(),
'_state_dict_hooks': OrderedDict(),
'_state_dict_pre_hooks': OrderedDict(),
'_load_state_dict_pre_hooks': OrderedDict(),
'_load_state_dict_post_hooks': OrderedDict(),
'_modules': {'layers': Sequential(
(0): Linear(in_features=10, out_features=320, bias=True)
(1): LeakyReLU()
(2): Dropout(p=0.023931753071792624, inplace=False)
(3): Linear(in_features=320, out_features=160, bias=True)
(4): LeakyReLU()
(5): Dropout(p=0.023931753071792624, inplace=False)
(6): Linear(in_features=160, out_features=320, bias=True)
(7): LeakyReLU()
(8): Dropout(p=0.023931753071792624, inplace=False)
(9): Linear(in_features=320, out_features=160, bias=True)
(10): LeakyReLU()
(11): Dropout(p=0.023931753071792624, inplace=False)
(12): Linear(in_features=160, out_features=160, bias=True)
(13): LeakyReLU()
(14): Dropout(p=0.023931753071792624, inplace=False)
(15): Linear(in_features=160, out_features=80, bias=True)
(16): LeakyReLU()
(17): Dropout(p=0.023931753071792624, inplace=False)
(18): Linear(in_features=80, out_features=80, bias=True)
(19): LeakyReLU()
(20): Dropout(p=0.023931753071792624, inplace=False)
(21): Linear(in_features=80, out_features=1, bias=True)
)},
'prepare_data_per_node': True,
'allow_zero_length_dataloader_with_multiple_devices': False,
'_log_hyperparams': True,
'_dtype': torch.float32,
'_device': device(type='mps', index=0),
'_trainer': None,
'_example_input_array': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]),
'_automatic_optimization': True,
'_strict_loading': None,
'_current_fx_name': None,
'_param_requires_grad_state': {},
'_metric_attributes': None,
'_compiler_ctx': None,
'_fabric': None,
'_fabric_optimizers': [],
'_device_mesh': None,
'_L_in': 10,
'_L_out': 1,
'_torchmetric': 'mean_squared_error',
'metric': <function torchmetrics.functional.regression.mse.mean_squared_error(preds: torch.Tensor, target: torch.Tensor, squared: bool = True, num_outputs: int = 1) -> torch.Tensor>,
'_hparams_name': 'kwargs',
'_hparams': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8,
'_hparams_initial': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8}torch.save(model_loaded, "model.pt")Note the following warning: In PyTorch 2.6, the default value of the weights_only argument in torch.load was changed from False to True. Re-running torch.load with weights_only set to False will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
mymodel = torch.load("model.pt", weights_only=False)Show all attributes of the model:
vars(mymodel){'training': False,
'_parameters': {},
'_buffers': {},
'_non_persistent_buffers_set': set(),
'_backward_pre_hooks': OrderedDict(),
'_backward_hooks': OrderedDict(),
'_is_full_backward_hook': None,
'_forward_hooks': OrderedDict(),
'_forward_hooks_with_kwargs': OrderedDict(),
'_forward_hooks_always_called': OrderedDict(),
'_forward_pre_hooks': OrderedDict(),
'_forward_pre_hooks_with_kwargs': OrderedDict(),
'_state_dict_hooks': OrderedDict(),
'_state_dict_pre_hooks': OrderedDict(),
'_load_state_dict_pre_hooks': OrderedDict(),
'_load_state_dict_post_hooks': OrderedDict(),
'_modules': {'layers': Sequential(
(0): Linear(in_features=10, out_features=320, bias=True)
(1): LeakyReLU()
(2): Dropout(p=0.023931753071792624, inplace=False)
(3): Linear(in_features=320, out_features=160, bias=True)
(4): LeakyReLU()
(5): Dropout(p=0.023931753071792624, inplace=False)
(6): Linear(in_features=160, out_features=320, bias=True)
(7): LeakyReLU()
(8): Dropout(p=0.023931753071792624, inplace=False)
(9): Linear(in_features=320, out_features=160, bias=True)
(10): LeakyReLU()
(11): Dropout(p=0.023931753071792624, inplace=False)
(12): Linear(in_features=160, out_features=160, bias=True)
(13): LeakyReLU()
(14): Dropout(p=0.023931753071792624, inplace=False)
(15): Linear(in_features=160, out_features=80, bias=True)
(16): LeakyReLU()
(17): Dropout(p=0.023931753071792624, inplace=False)
(18): Linear(in_features=80, out_features=80, bias=True)
(19): LeakyReLU()
(20): Dropout(p=0.023931753071792624, inplace=False)
(21): Linear(in_features=80, out_features=1, bias=True)
)},
'prepare_data_per_node': True,
'allow_zero_length_dataloader_with_multiple_devices': False,
'_log_hyperparams': True,
'_dtype': torch.float32,
'_device': device(type='mps', index=0),
'_trainer': None,
'_example_input_array': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]),
'_automatic_optimization': True,
'_strict_loading': None,
'_current_fx_name': None,
'_param_requires_grad_state': {},
'_metric_attributes': None,
'_compiler_ctx': None,
'_fabric': None,
'_fabric_optimizers': [],
'_device_mesh': None,
'_L_in': 10,
'_L_out': 1,
'_torchmetric': 'mean_squared_error',
'metric': <function torchmetrics.functional.regression.mse.mean_squared_error(preds: torch.Tensor, target: torch.Tensor, squared: bool = True, num_outputs: int = 1) -> torch.Tensor>,
'_hparams_name': 'kwargs',
'_hparams': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8,
'_hparams_initial': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8}57.6 Converting a Lightning Model to a Plain Torch Model
57.6.1 The Function get_removed_attributes_and_base_net
spotpython provides a function to covert a PyTorch Lightning model to a plain PyTorch model. The function get_removed_attributes_and_base_net returns a tuple with the removed attributes and the base net. The base net is a plain PyTorch model. The removed attributes are the attributes of the PyTorch Lightning model that are not part of the base net.
This conversion can be reverted.
removed_attributes, torch_net = get_removed_attributes_and_base_net(net=mymodel)print(removed_attributes){'_compiler_ctx': None, '_example_input_array': tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]), '_device': device(type='mps', index=0), '_torchmetric': 'mean_squared_error', '_dtype': torch.float32, '_fabric_optimizers': [], '_hparams_initial': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8, '_current_fx_name': None, '_L_in': 10, '_L_out': 1, '_metric_attributes': None, '_hparams': "_L_cond": None
"act_fn": LeakyReLU()
"batch_norm": False
"batch_size": 32
"dropout_prob": 0.023931753071792624
"epochs": 16
"initialization": xavier_normal
"l1": 16
"lr_mult": 1.2532486761645163
"optimizer": Adamax
"patience": 8, '_log_hyperparams': True, '_device_mesh': None, '_trainer': None, '_param_requires_grad_state': {}, '_automatic_optimization': True, 'prepare_data_per_node': True, 'metric': <function mean_squared_error at 0x1430b5940>, '_strict_loading': None, '_fabric': None, 'allow_zero_length_dataloader_with_multiple_devices': False, '_hparams_name': 'kwargs'}print(torch_net)NNLinearRegressor(
(layers): Sequential(
(0): Linear(in_features=10, out_features=320, bias=True)
(1): LeakyReLU()
(2): Dropout(p=0.023931753071792624, inplace=False)
(3): Linear(in_features=320, out_features=160, bias=True)
(4): LeakyReLU()
(5): Dropout(p=0.023931753071792624, inplace=False)
(6): Linear(in_features=160, out_features=320, bias=True)
(7): LeakyReLU()
(8): Dropout(p=0.023931753071792624, inplace=False)
(9): Linear(in_features=320, out_features=160, bias=True)
(10): LeakyReLU()
(11): Dropout(p=0.023931753071792624, inplace=False)
(12): Linear(in_features=160, out_features=160, bias=True)
(13): LeakyReLU()
(14): Dropout(p=0.023931753071792624, inplace=False)
(15): Linear(in_features=160, out_features=80, bias=True)
(16): LeakyReLU()
(17): Dropout(p=0.023931753071792624, inplace=False)
(18): Linear(in_features=80, out_features=80, bias=True)
(19): LeakyReLU()
(20): Dropout(p=0.023931753071792624, inplace=False)
(21): Linear(in_features=80, out_features=1, bias=True)
)
)57.6.2 An Example how to use the Plain Torch Net
# Load the Diabetes dataset from sklearn
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Convert the data to PyTorch tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)
# Create a PyTorch dataset
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
# Create a PyTorch dataloader
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size)
torch_net.to(getDevice("cpu"))
# train the net
criterion = nn.MSELoss()
optimizer = optim.Adam(torch_net.parameters(), lr=0.01)
n_epochs = 100
losses = []
for epoch in range(n_epochs):
for inputs, targets in train_dataloader:
targets = targets.view(-1, 1)
optimizer.zero_grad()
outputs = torch_net(inputs)
loss = criterion(outputs, targets)
losses.append(loss.item())
loss.backward()
optimizer.step()
# visualize the network training
plt.plot(losses)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()