Next, we will wrap everything together in a LightningModule.
class Learner(pl.LightningModule):def__init__(self, model:nn.Module, t_span:torch.Tensor, learning_rate:float=5e-3):super().__init__()self.model = modelself.t_span = t_spanself.learning_rate = learning_rate# self.accuracy = Accuracy(num_classes=2)self.accuracy = accuracydef forward(self, x):returnself.model(x)def inference(self, x, time_span):returnself.model(x, adjoint=False, integration_time=time_span)def inference_no_projection(self, x, time_span):returnself.model.forward_no_projection(x, adjoint=False, integration_time=time_span)def training_step(self, batch, batch_idx): x, y = batch y_pred =self(x) y_pred = y_pred[-1] # select last point of solution trajectory loss = nn.CrossEntropyLoss()(y_pred, y)self.log('train_loss', loss, prog_bar=True, logger=True)return lossdef validation_step(self, batch, batch_idx): x, y = batch y_pred =self(x) y_pred = y_pred[-1] # select last point of solution trajectory loss = nn.CrossEntropyLoss()(y_pred, y)self.log('val_loss', loss, prog_bar=True, logger=True) acc =self.accuracy(y_pred.softmax(dim=-1), y, num_classes=2, task="MULTICLASS")self.log('val_accuracy', acc, prog_bar=True, logger=True)return lossdef test_step(self, batch, batch_idx): x, y = batch y_pred =self(x) y_pred = y_pred[-1] # select last point of solution trajectory loss = nn.CrossEntropyLoss()(y_pred, y)self.log('test_loss', loss, prog_bar=True, logger=True) acc =self.accuracy(y_pred.softmax(dim=-1), y, num_classes=2, task="MULTICLASS")self.log('test_accuracy', acc, prog_bar=True, logger=True)return lossdef configure_optimizers(self): optimizer = torch.optim.Adam(self.model.parameters(), lr=self.learning_rate)return optimizer
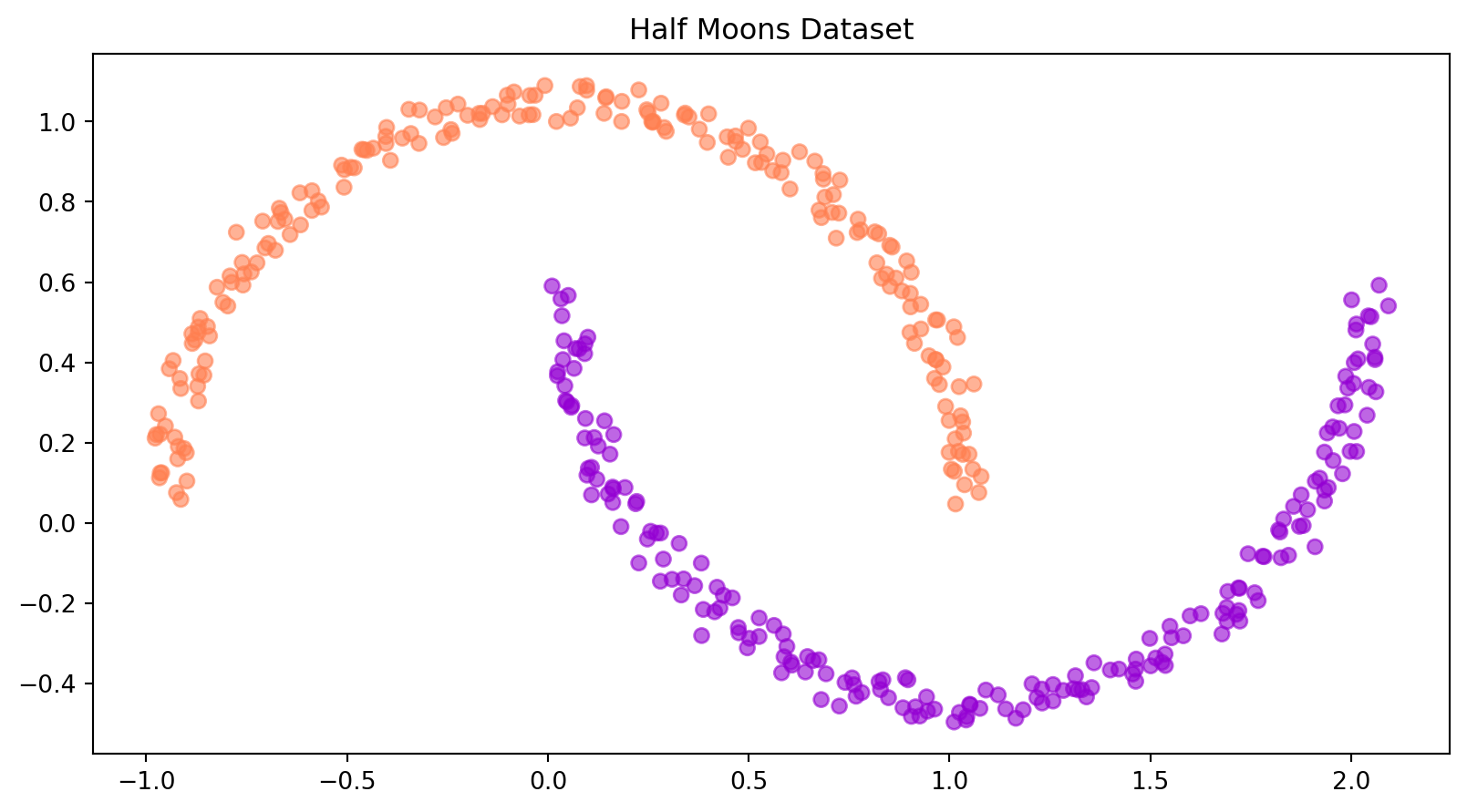
We will be working will Half Moons Dataset, a non-linearly separable, binary classification dataset. The code is based on the excellent TorchDyn tutorials (https://github.com/DiffEqML/torchdyn), as well as the original TorchDiffEq examples (https://github.com/rtqichen/torchdiffeq).
class MoonsDataset(Dataset):"""Half Moons Classification Dataset Adapted from https://github.com/DiffEqML/torchdyn """def__init__(self, num_samples=100, noise_std=1e-4):self.num_samples = num_samplesself.noise_std = noise_stdself.X, self.y =self.generate_moons(num_samples, noise_std)@staticmethoddef generate_moons(num_samples=100, noise_std=1e-4):"""Creates a *moons* dataset of `num_samples` data points. :param num_samples: number of data points in the generated dataset :type num_samples: int :param noise_std: standard deviation of noise magnitude added to each data point :type noise_std: float """ num_samples_out = num_samples //2 num_samples_in = num_samples - num_samples_out theta_out = np.linspace(0, np.pi, num_samples_out) theta_in = np.linspace(0, np.pi, num_samples_in) outer_circ_x = np.cos(theta_out) outer_circ_y = np.sin(theta_out) inner_circ_x =1- np.cos(theta_in) inner_circ_y =1- np.sin(theta_in) -0.5 X = np.vstack([np.append(outer_circ_x, inner_circ_x), np.append(outer_circ_y, inner_circ_y)]).T y = np.hstack([np.zeros(num_samples_out), np.ones(num_samples_in)])if noise_std isnotNone: X += noise_std * np.random.rand(num_samples, 2) X = torch.Tensor(X) y = torch.LongTensor(y)return X, ydef__len__(self):returnself.num_samplesdef__getitem__(self, idx):returnself.X[idx], self.y[idx]
def plot_binary_classification_dataset(X, y, title=None): CLASS_COLORS = ['coral', 'darkviolet'] fig, ax = plt.subplots(figsize=(10, 10)) ax.scatter(X[:, 0], X[:, 1], color=[CLASS_COLORS[yi.int()] for yi in y], alpha=0.6) ax.set_aspect('equal')if title isnotNone: ax.set_title(title)return fig, ax
Let’s now create the train, validation, and test sets, with their corresponding data loaders. We will create a single big dataset and randomly split it in train, val, and test sets.
We define a Neural ODE and train it. We will use a simple 2-layer MLP with a tanh activation and 64 hidden dimensions. We will train the model using the adjoint method for backpropagation.
A quick note on the architectural choices for our model. The Picard-Lindelöf theorem (Coddington and Levinson, 1955) states that the solution to an initial value problem exists and is unique if the differential equation is uniformly Lipschitz continuous in \(\mathbf{z}\) and continuous in \(t\). It turns out that this theorem holds for our model if the neural network has finite weights and uses Lipschitz nonlinearities, such as tanh or relu. However, not all tools are our deep learning arsenal is c. For example, as shown in The Lipschitz Constant of Self-Attention by Hyunjik Kim et al., standard self-attention is not Lipschitz. The authors propose alternative forms of self-attention that are Lipschitz.
┏━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃
┡━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━┩
│ 0 │ model │ ODEBlock │ 322 │ train │ 0 │
└───┴───────┴──────────┴────────┴───────┴───────┘
Trainable params: 322
Non-trainable params: 0
Total params: 322
Total estimated model params size (MB): 0
Modules in train mode: 6
Modules in eval mode: 0
Total FLOPs: 0
/Users/bartz/miniforge3/envs/spot313/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_connect
or.py:434: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value
of the `num_workers` argument` to `num_workers=23` in the `DataLoader` to improve performance.
/Users/bartz/miniforge3/envs/spot313/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_connect
or.py:434: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the
value of the `num_workers` argument` to `num_workers=23` in the `DataLoader` to improve performance.
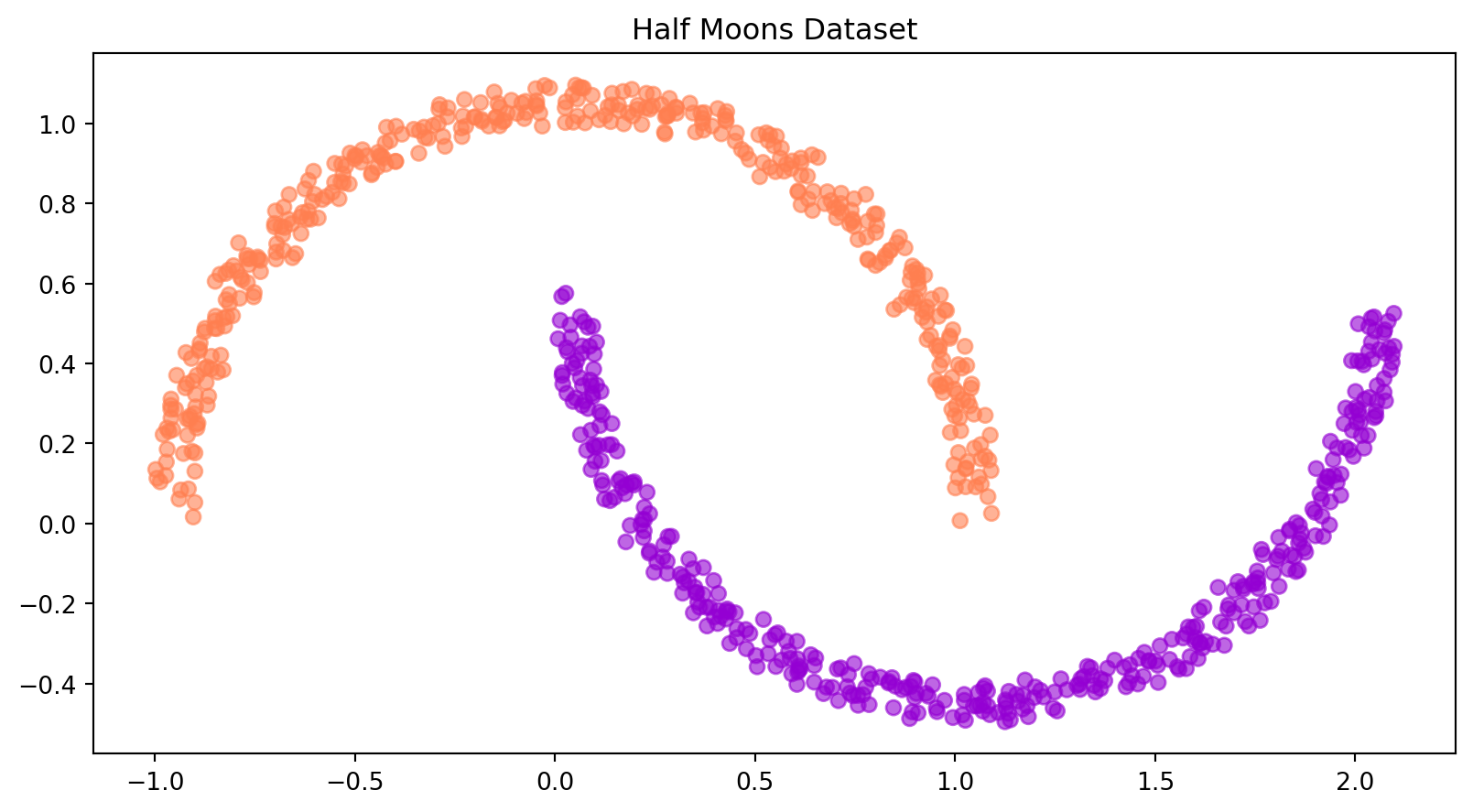
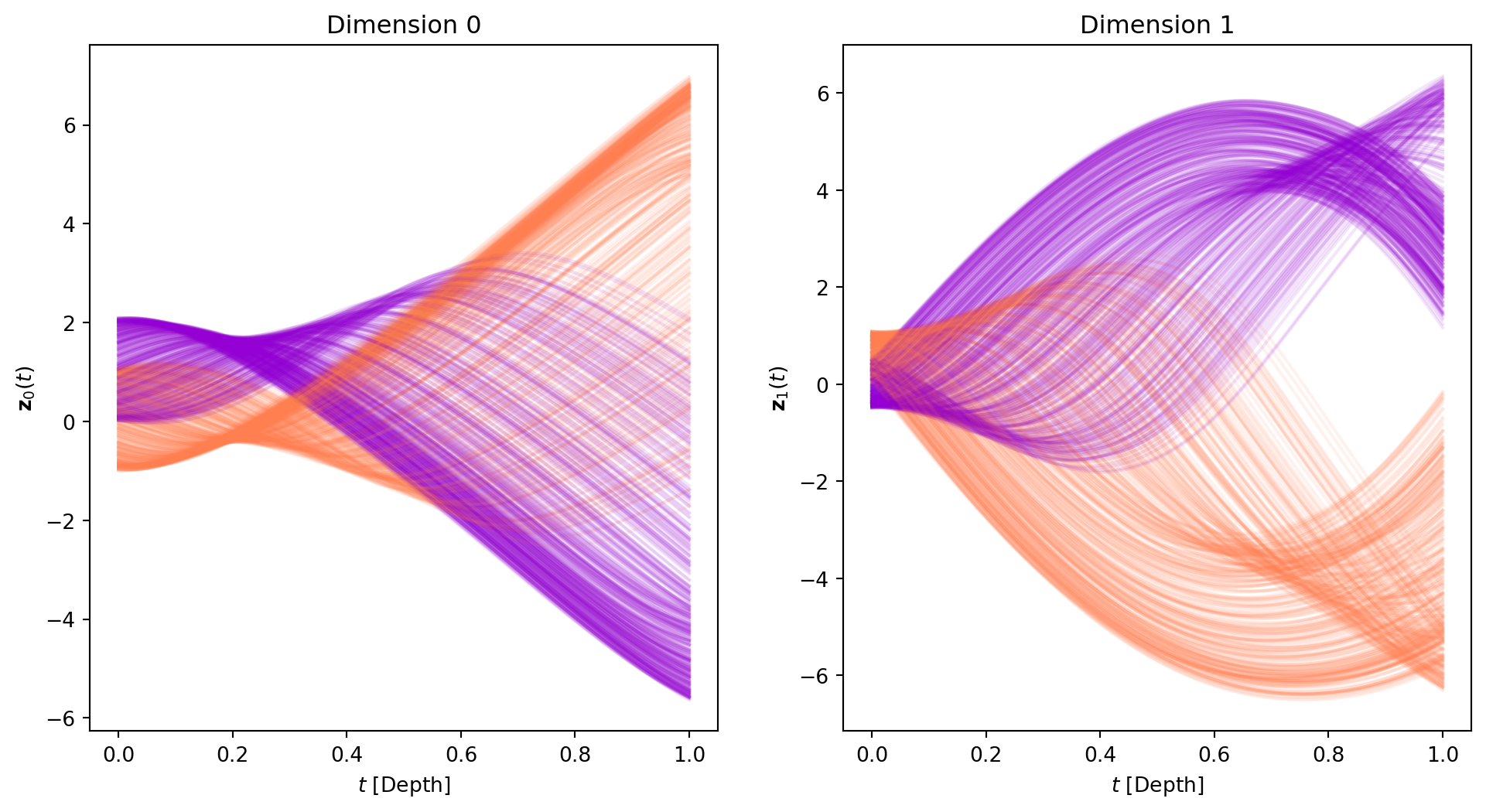
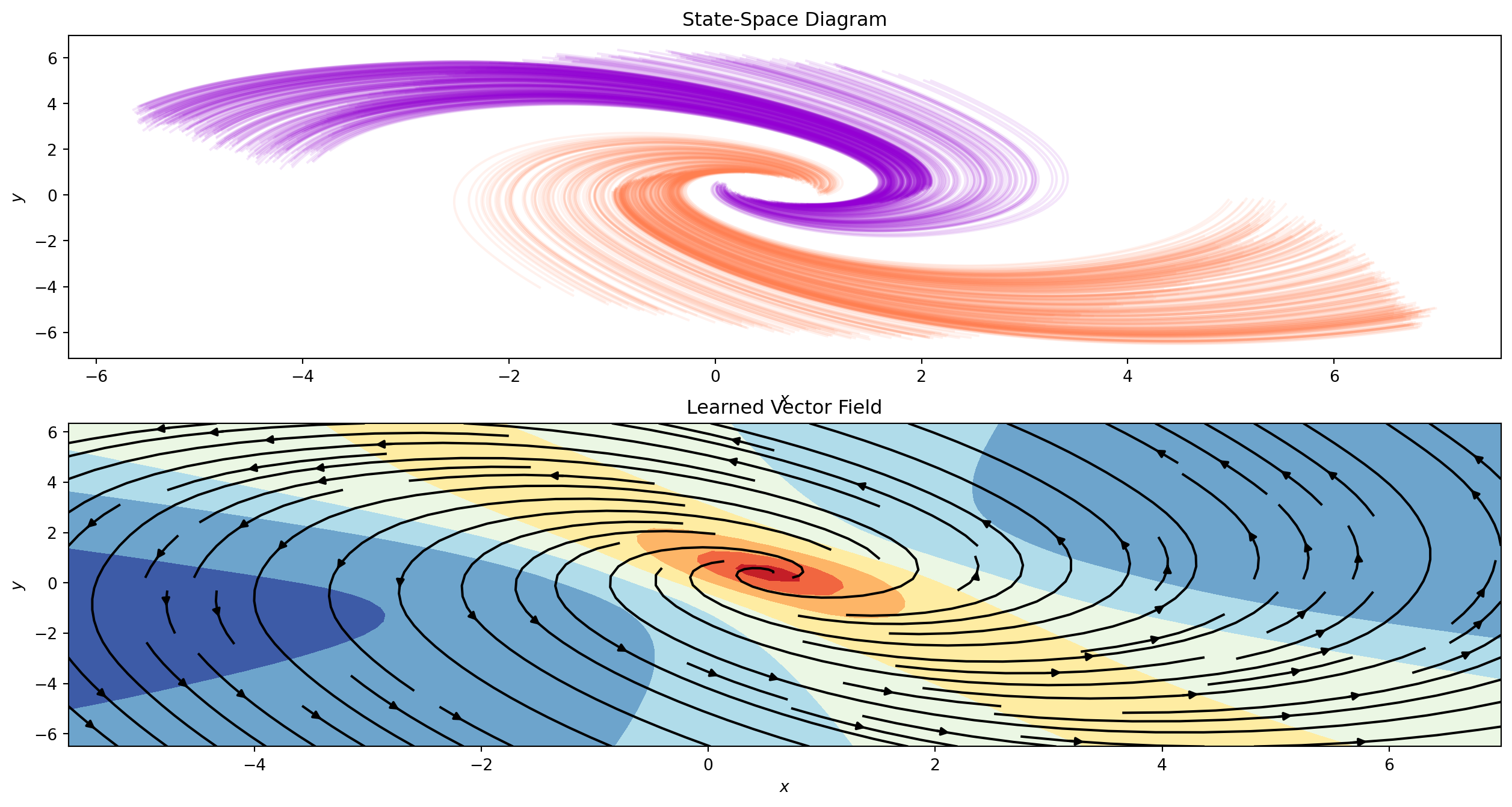
It seems that in less that 200 epochs we have achieved perfect validation accuracy. Let’s now use the trained model to run inference and visualize the trajectories using a dense time span of 100 timesteps.
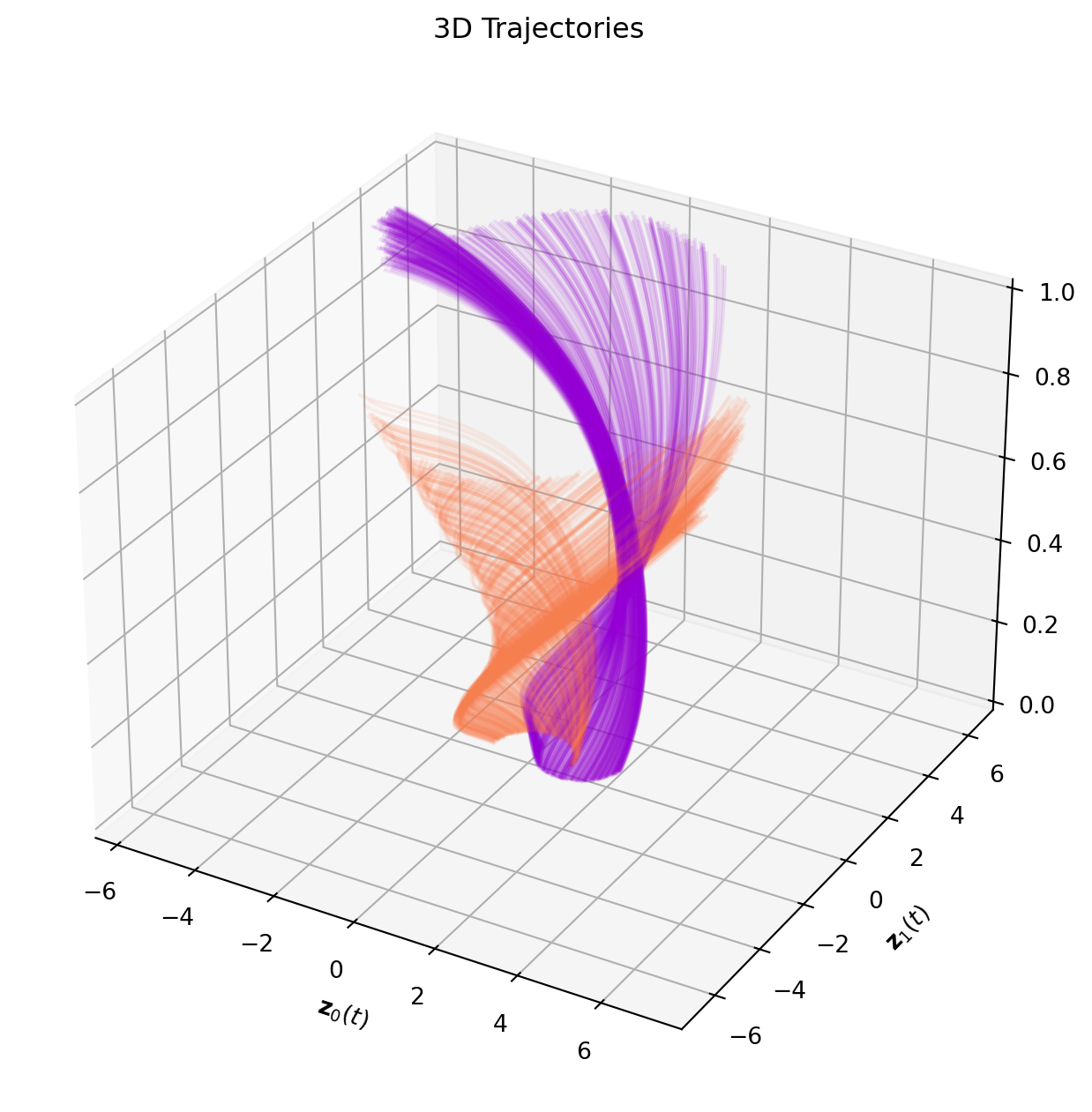
The 3D plot can be somewhat complicated to decipher. Thus, we also plot an animated version of the evolution. Each timestep of the animation is a slice on the temporal axis of the figure above.