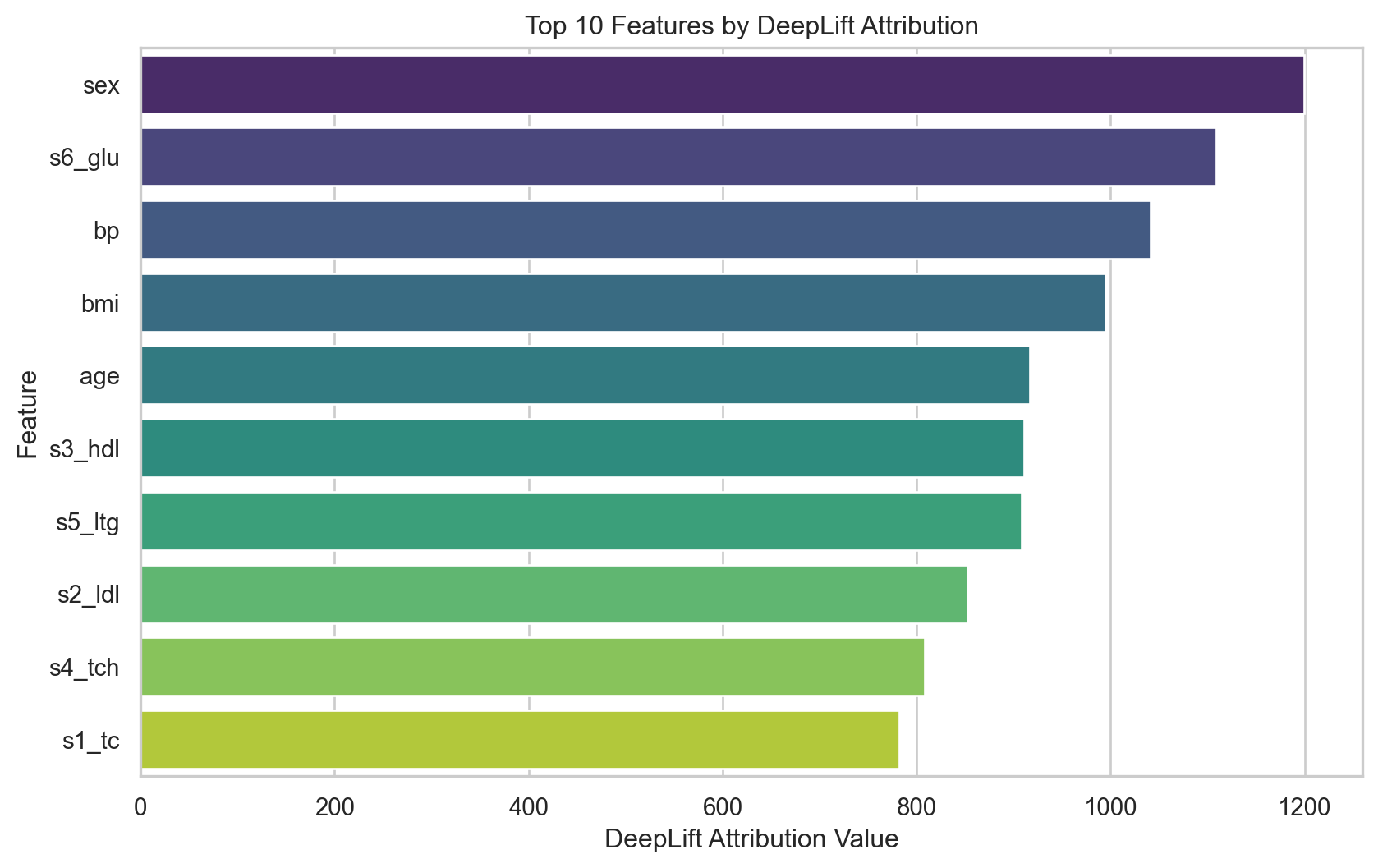
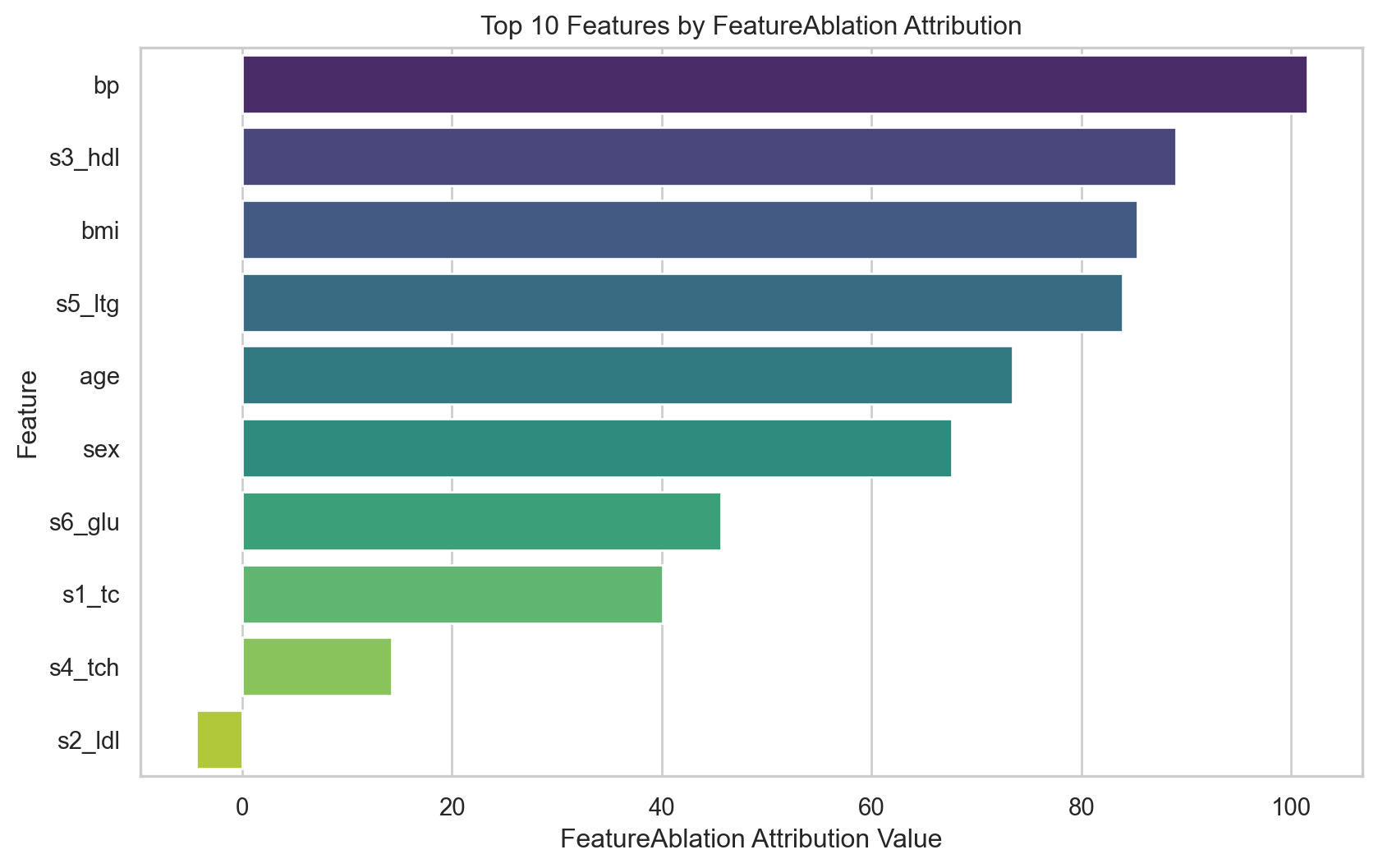
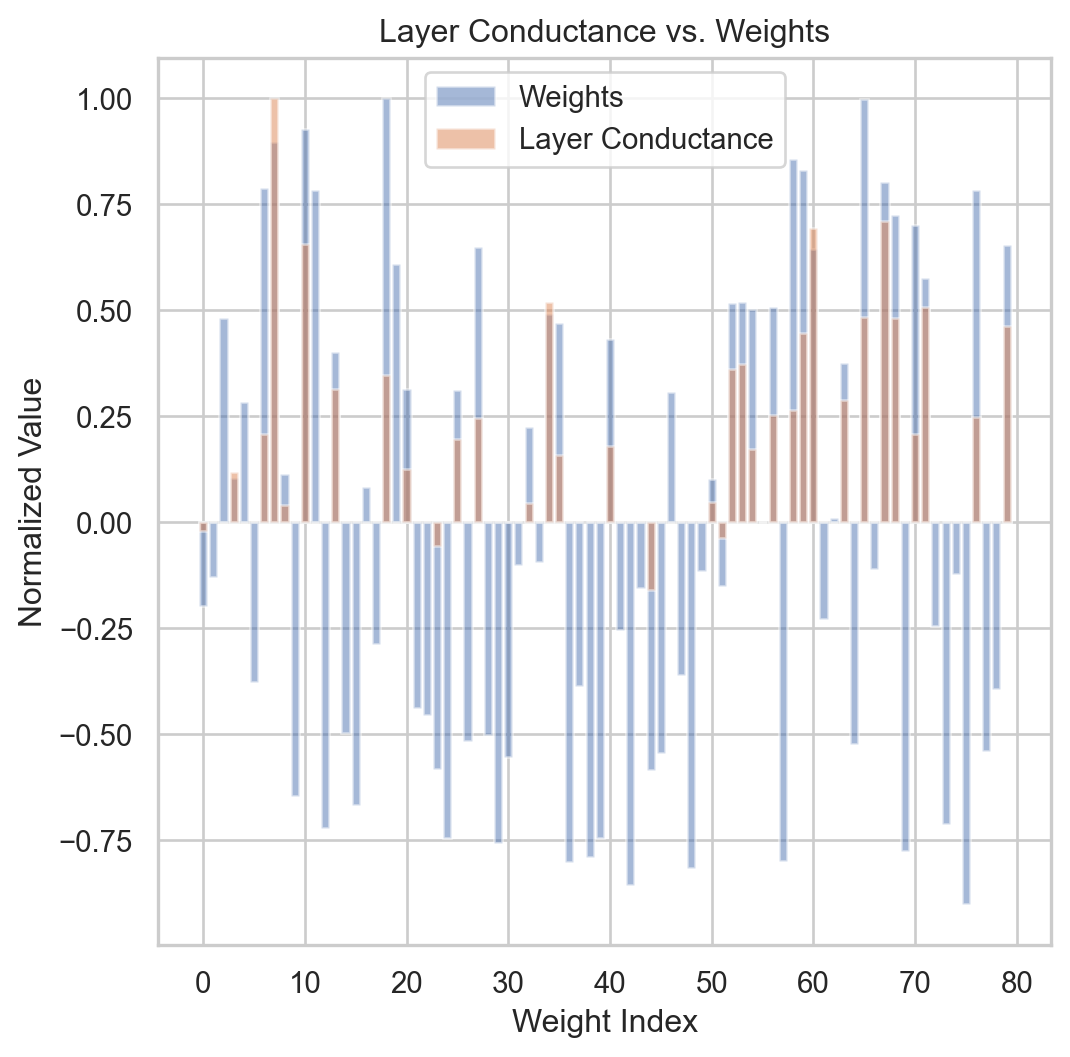
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 51.6 M
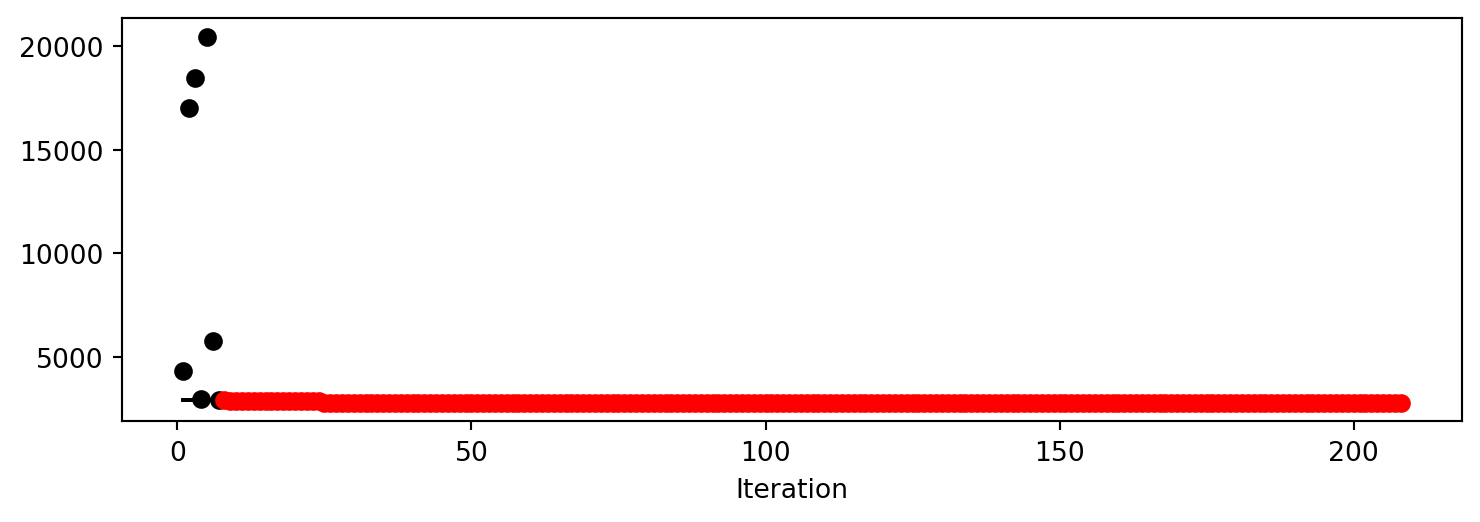
train_model result: {'val_loss': 24008.5703125, 'hp_metric': 24008.5703125}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 816 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 816 M
train_model result: {'val_loss': 25638.1328125, 'hp_metric': 25638.1328125}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 12.9 M
train_model result: {'val_loss': 4298.646484375, 'hp_metric': 4298.646484375}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 1.6 B │ [1024, 10] │ [1024, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 1.6 B
train_model result: {'val_loss': 23521.087890625, 'hp_metric': 23521.087890625}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 12.7 M │ train │ 52.1 B │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴────────────┴───────────┘
Trainable params: 12.7 M
Non-trainable params: 0
Total params: 12.7 M
Total estimated model params size (MB): 50
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 52.1 B
train_model result: {'val_loss': 234333.578125, 'hp_metric': 234333.578125}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 52.5 M
train_model result: {'val_loss': 24054.228515625, 'hp_metric': 24054.228515625}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 24212.8515625, 'hp_metric': 24212.8515625}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 25.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.6 M
train_model result: {'val_loss': 15141.951171875, 'hp_metric': 15141.951171875}
spotpython tuning: 4298.646484375 [----------] 1.25%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 25.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.6 M
train_model result: {'val_loss': 10541.05859375, 'hp_metric': 10541.05859375}
spotpython tuning: 4298.646484375 [----------] 2.89%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 6.5 M
train_model result: {'val_loss': 22962.96484375, 'hp_metric': 22962.96484375}
spotpython tuning: 4298.646484375 [----------] 4.47%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 12.7 M │ train │ 814 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.7 M
Non-trainable params: 0
Total params: 12.7 M
Total estimated model params size (MB): 50
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 814 M
train_model result: {'val_loss': 77827.0234375, 'hp_metric': 77827.0234375}
spotpython tuning: 4298.646484375 [#---------] 6.53%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 23592.322265625, 'hp_metric': 23592.322265625}
spotpython tuning: 4298.646484375 [#---------] 7.10%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 3.3 M
train_model result: {'val_loss': 6308.0634765625, 'hp_metric': 6308.0634765625}
spotpython tuning: 4298.646484375 [#---------] 8.08%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 3.3 M
train_model result: {'val_loss': 24040.986328125, 'hp_metric': 24040.986328125}
spotpython tuning: 4298.646484375 [#---------] 9.34%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 3.3 M
train_model result: {'val_loss': 20776.10546875, 'hp_metric': 20776.10546875}
spotpython tuning: 4298.646484375 [#---------] 10.97%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 25.8 M
train_model result: {'val_loss': 23944.212890625, 'hp_metric': 23944.212890625}
spotpython tuning: 4298.646484375 [#---------] 11.92%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 103 M
train_model result: {'val_loss': 24245.560546875, 'hp_metric': 24245.560546875}
spotpython tuning: 4298.646484375 [#---------] 13.00%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 102 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 102 M
train_model result: {'val_loss': 23191.6796875, 'hp_metric': 23191.6796875}
spotpython tuning: 4298.646484375 [#---------] 14.49%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 6.5 M
train_model result: {'val_loss': 22550.796875, 'hp_metric': 22550.796875}
spotpython tuning: 4298.646484375 [##--------] 16.05%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 25.8 M
train_model result: {'val_loss': 23998.98046875, 'hp_metric': 23998.98046875}
spotpython tuning: 4298.646484375 [##--------] 17.95%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 12.9 M
train_model result: {'val_loss': 7605.974609375, 'hp_metric': 7605.974609375}
spotpython tuning: 4298.646484375 [##--------] 19.39%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 6.6 M
train_model result: {'val_loss': 24050.08984375, 'hp_metric': 24050.08984375}
spotpython tuning: 4298.646484375 [##--------] 21.45%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 12.9 M
train_model result: {'val_loss': 13179.0244140625, 'hp_metric': 13179.0244140625}
spotpython tuning: 4298.646484375 [##--------] 22.72%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 12.9 M
train_model result: {'val_loss': 3.0394979793716095e+24, 'hp_metric': 3.0394979793716095e+24}
spotpython tuning: 4298.646484375 [##--------] 23.63%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 52.5 M
train_model result: {'val_loss': 24071.0078125, 'hp_metric': 24071.0078125}
spotpython tuning: 4298.646484375 [###-------] 26.13%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 22922.708984375, 'hp_metric': 22922.708984375}
spotpython tuning: 4298.646484375 [###-------] 26.88%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 21665.01953125, 'hp_metric': 21665.01953125}
spotpython tuning: 4298.646484375 [###-------] 31.33%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 24376.826171875, 'hp_metric': 24376.826171875}
spotpython tuning: 4298.646484375 [###-------] 34.39%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 52.5 M
train_model result: {'val_loss': 23619.865234375, 'hp_metric': 23619.865234375}
spotpython tuning: 4298.646484375 [####------] 36.29%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 819 M │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 819 M
train_model result: {'val_loss': 23855.919921875, 'hp_metric': 23855.919921875}
spotpython tuning: 4298.646484375 [####------] 39.63%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 204 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 204 M
train_model result: {'val_loss': 18489.638671875, 'hp_metric': 18489.638671875}
spotpython tuning: 4298.646484375 [####------] 42.13%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 6.6 M
train_model result: {'val_loss': 24000.38671875, 'hp_metric': 24000.38671875}
spotpython tuning: 4298.646484375 [####------] 44.69%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 23436.99609375, 'hp_metric': 23436.99609375}
spotpython tuning: 4298.646484375 [#####-----] 49.02%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 103 M
train_model result: {'val_loss': 24025.77734375, 'hp_metric': 24025.77734375}
spotpython tuning: 4298.646484375 [#####-----] 50.85%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.6 M
train_model result: {'val_loss': 24050.146484375, 'hp_metric': 24050.146484375}
spotpython tuning: 4298.646484375 [#####-----] 53.32%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.8 M
train_model result: {'val_loss': 23898.478515625, 'hp_metric': 23898.478515625}
spotpython tuning: 4298.646484375 [######----] 55.86%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 51.2 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.2 M
train_model result: {'val_loss': 20080.798828125, 'hp_metric': 20080.798828125}
spotpython tuning: 4298.646484375 [######----] 57.54%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 13.1 M
train_model result: {'val_loss': 24015.955078125, 'hp_metric': 24015.955078125}
spotpython tuning: 4298.646484375 [######----] 60.36%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.6 M
train_model result: {'val_loss': 24050.486328125, 'hp_metric': 24050.486328125}
spotpython tuning: 4298.646484375 [######----] 64.32%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 102 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 102 M
train_model result: {'val_loss': 17813.669921875, 'hp_metric': 17813.669921875}
spotpython tuning: 4298.646484375 [#######---] 67.94%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 3.3 M
train_model result: {'val_loss': 22139.86328125, 'hp_metric': 22139.86328125}
spotpython tuning: 4298.646484375 [#######---] 71.39%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K
Non-trainable params: 0
Total params: 202 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 6.5 M
train_model result: {'val_loss': 24036.263671875, 'hp_metric': 24036.263671875}
spotpython tuning: 4298.646484375 [########--] 75.07%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 1.6 M
train_model result: {'val_loss': 21281.712890625, 'hp_metric': 21281.712890625}
spotpython tuning: 4298.646484375 [########--] 78.08%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 1.6 M
train_model result: {'val_loss': 5334.50048828125, 'hp_metric': 5334.50048828125}
spotpython tuning: 4298.646484375 [########--] 81.38%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 6.5 M
train_model result: {'val_loss': 24019.35546875, 'hp_metric': 24019.35546875}
spotpython tuning: 4298.646484375 [#########-] 85.05%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 1.6 M
train_model result: {'val_loss': 5027.46240234375, 'hp_metric': 5027.46240234375}
spotpython tuning: 4298.646484375 [#########-] 88.36%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 816 M │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 816 M
train_model result: {'val_loss': 724579.1875, 'hp_metric': 724579.1875}
spotpython tuning: 4298.646484375 [#########-] 89.59%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 25.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.6 M
train_model result: {'val_loss': 24025.4453125, 'hp_metric': 24025.4453125}
spotpython tuning: 4298.646484375 [#########-] 92.27%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 103 M
train_model result: {'val_loss': 23999.83203125, 'hp_metric': 23999.83203125}
spotpython tuning: 4298.646484375 [#########-] 93.96%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 25.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 25.6 M
train_model result: {'val_loss': 19088.296875, 'hp_metric': 19088.296875}
spotpython tuning: 4298.646484375 [##########] 95.92%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.8 M
train_model result: {'val_loss': 24011.466796875, 'hp_metric': 24011.466796875}
spotpython tuning: 4298.646484375 [##########] 97.75%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 3.3 B │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 3.3 B
train_model result: {'val_loss': 13796.8359375, 'hp_metric': 13796.8359375}
spotpython tuning: 4298.646484375 [##########] 98.57%. Success rate: 0.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 12.7 M │ train │ 13.0 B │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 12.7 M
Non-trainable params: 0
Total params: 12.7 M
Total estimated model params size (MB): 50
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 13.0 B
train_model result: {'val_loss': 76184.4921875, 'hp_metric': 76184.4921875}
spotpython tuning: 4298.646484375 [##########] 100.00%. Success rate: 0.00% Done...
Experiment saved to 602_12_1_res.pkl
<spotpython.spot.spot.Spot at 0x1533ec830>