47Hyperparameter Tuning with PyTorch Lightning and User Data Sets
In this section, we will show how user specfied data can be used for the PyTorch Lightning hyperparameter tuning workflow with spotpython.
47.1 Loading a User Specified Data Set
Using a user-specified data set is straightforward.
The user simply needs to provide a data set and loads is as a spotpythonCVSDataset() class by specifying the path, filename, and target column.
Consider the following example, where the user has a data set stored in the userData directory. The data set is stored in a file named data.csv. The target column is named target. To show the data, it is loaded as a pandas data frame and the first 5 rows are displayed. This step is not necessary for the hyperparameter tuning process, but it is useful for understanding the data.
# load the csv data set as a pandas dataframe and dislay the first 5 rowsimport pandas as pddata = pd.read_csv("./userData/data.csv")print(data.head())
The following step is not necessary for the hyperparameter tuning process, but it is useful for understanding the data. The data set is loaded as a DataLoader from torch.utils.data to check the data.
# Set batch size for DataLoaderbatch_size =5# Create DataLoaderfrom torch.utils.data import DataLoaderdataloader = DataLoader(data_set, batch_size=batch_size, shuffle=False)# Iterate over the data in the DataLoaderfor batch in dataloader: inputs, targets = batchprint(f"Batch Size: {inputs.size(0)}")print(f"Inputs Shape: {inputs.shape}")print(f"Targets Shape: {targets.shape}")print("---------------")print(f"Inputs: {inputs}")print(f"Targets: {targets}")break
Similar to the setting from Section 45.1, the hyperparameter tuning setup is defined. Instead of using the Diabetes data set, the user data set is used. The data_set parameter is set to the user data set. The fun_control dictionary is set up via the fun_control_init function.
Note, that we have modified the fun_evals parameter to 12 and the init_size to 7 to reduce the computational time for this example. The divergence_threshold is set to 5,000, which is based on some pre-experiments with the user data set.
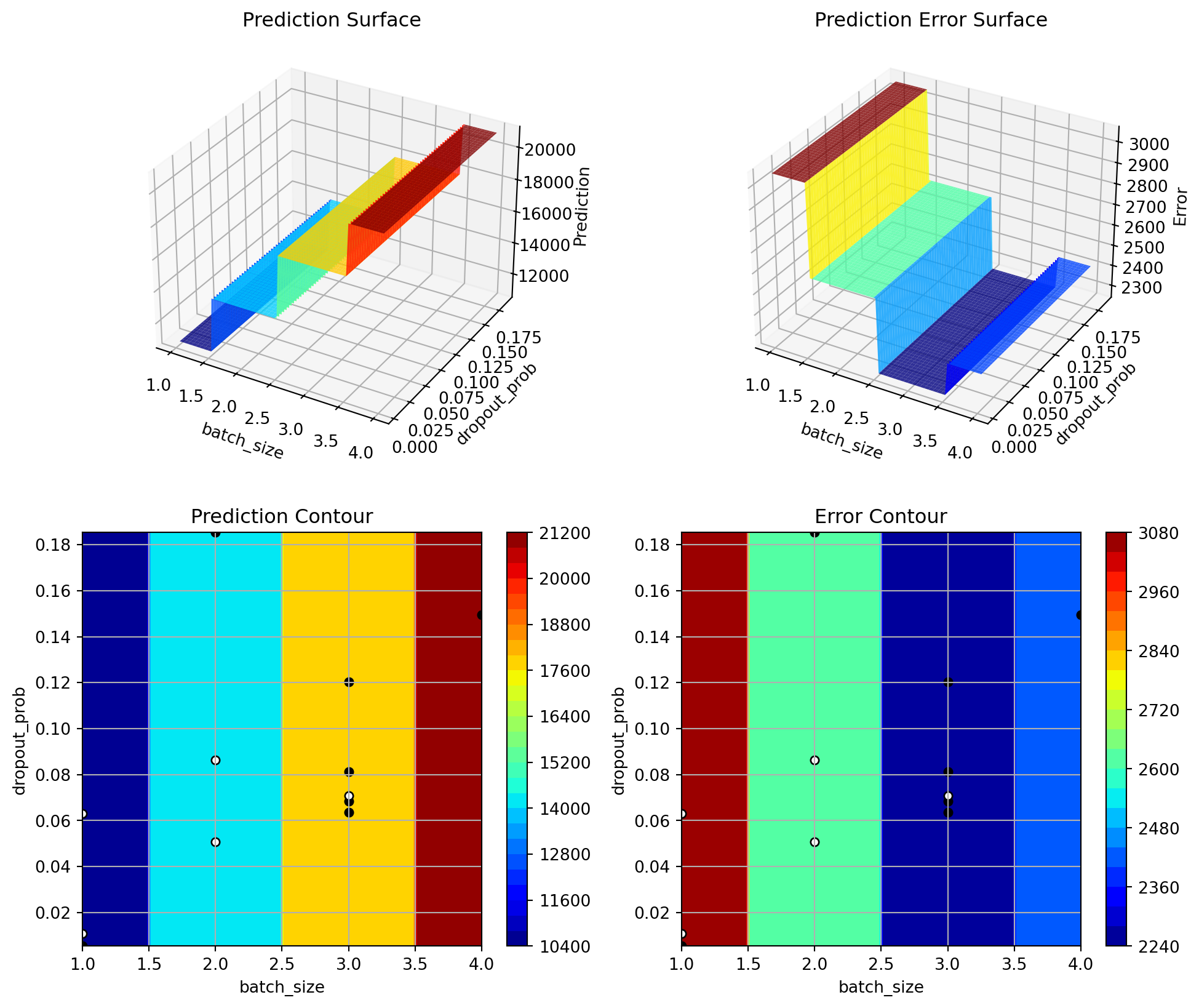
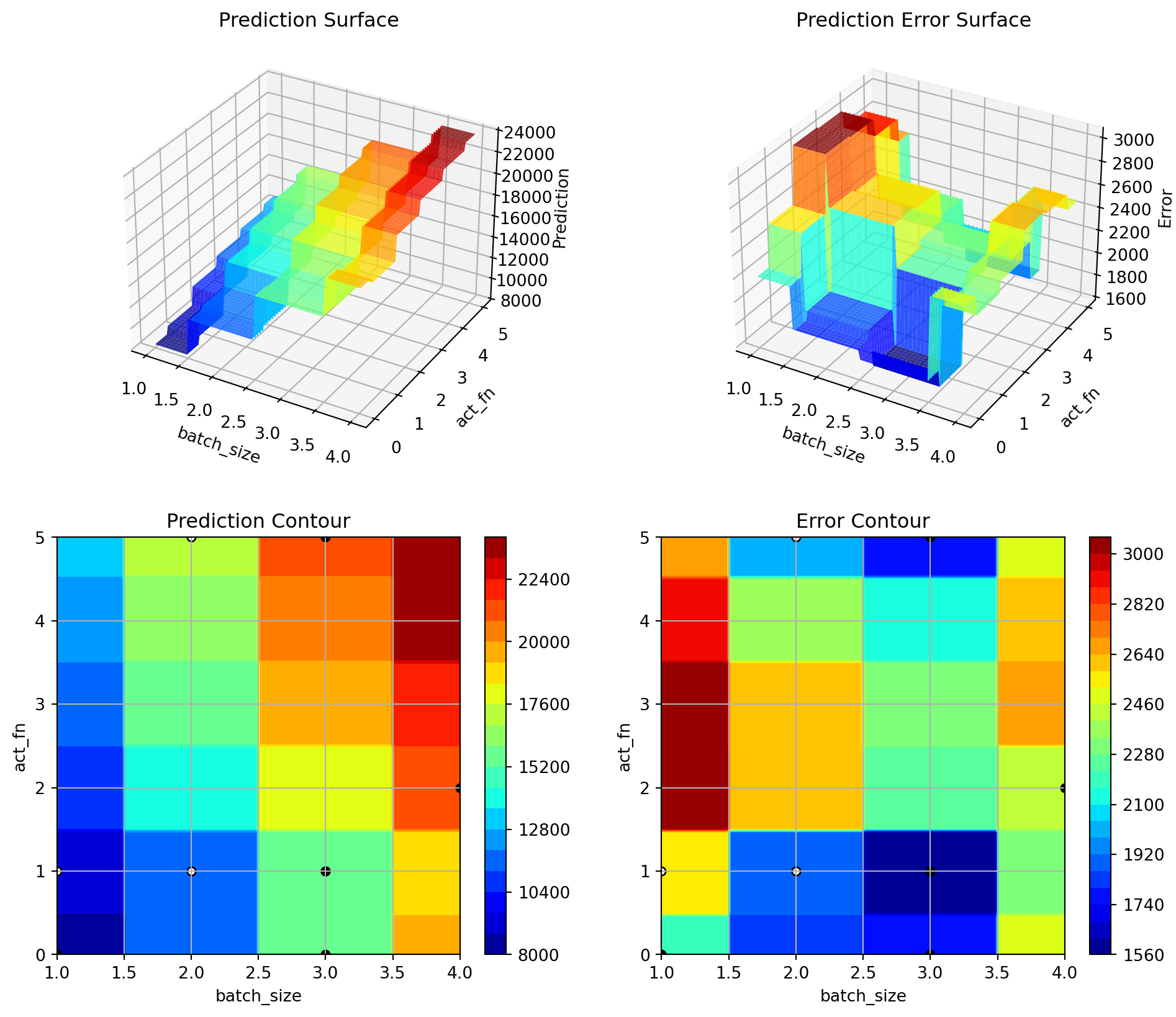
res = spot_tuner.run()print_res_table(spot_tuner)spot_tuner.plot_important_hyperparameter_contour(max_imp=3)
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 51.9 K │ train │ 409 K │ [4, 10] │ [4, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K
Non-trainable params: 0
Total params: 51.9 K
Total estimated model params size (MB): 0
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 409 K
train_model(): trainer.fit failed with exception: SparseAdam does not support dense gradients, please consider Adam instead
train_model result: {'val_loss': 23320.16015625, 'hp_metric': 23320.16015625}
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 12.8 M │ train │ 203 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M
Non-trainable params: 0
Total params: 12.8 M
Total estimated model params size (MB): 51
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 203 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 1.6 M │ [4, 10] │ [4, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 1.6 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 51.0 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.0 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 802 K │ train │ 12.8 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 802 K
Non-trainable params: 0
Total params: 802 K
Total estimated model params size (MB): 3
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 12.8 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 50.9 M │ train │ 203 M │ [2, 10] │ [2, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M
Non-trainable params: 0
Total params: 50.9 M
Total estimated model params size (MB): 203
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 203 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 807 K │ train │ 25.6 M │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K
Non-trainable params: 0
Total params: 807 K
Total estimated model params size (MB): 3
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 25.6 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 51.0 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.0 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 51.0 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.0 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 3.2 M │ train │ 51.0 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 3.2 M
Non-trainable params: 0
Total params: 3.2 M
Total estimated model params size (MB): 12
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 51.0 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 12.8 M │ train │ 50.9 M │ [2, 10] │ [2, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 12.8 M
Non-trainable params: 0
Total params: 12.8 M
Total estimated model params size (MB): 51
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 50.9 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 205 K │ train │ 3.2 M │ [8, 10] │ [8, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 205 K
Non-trainable params: 0
Total params: 205 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 3.2 M
train_model(): trainer.fit failed with exception: SparseAdam does not support dense gradients, please consider Adam instead
train_model result: {'val_loss': 22818.576171875, 'hp_metric': 22818.576171875}
spotpython tuning: 5972.04296875 [########--] 75.00%. Success rate: 40.00%
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 50.9 M │ train │ 203 M │ [2, 10] │ [2, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M
Non-trainable params: 0
Total params: 50.9 M
Total estimated model params size (MB): 203
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 203 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 50.9 M │ train │ 203 M │ [2, 10] │ [2, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M
Non-trainable params: 0
Total params: 50.9 M
Total estimated model params size (MB): 203
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 203 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 50.9 M │ train │ 203 M │ [2, 10] │ [2, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M
Non-trainable params: 0
Total params: 50.9 M
Total estimated model params size (MB): 203
Modules in train mode: 17
Modules in eval mode: 0
Total FLOPs: 203 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 53.2 K │ train │ 409 K │ [4, 10] │ [4, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K
Non-trainable params: 0
Total params: 53.2 K
Total estimated model params size (MB): 0
Modules in train mode: 24
Modules in eval mode: 0
Total FLOPs: 409 K
This section showed how to use user-specified data sets for the hyperparameter tuning process with spotpython. The user needs to provide the data set and load it as a spotpythonCSVDataset() class.