import numpy as np
from math import inf
from scipy.optimize import shgo
from scipy.optimize import direct
from scipy.optimize import differential_evolution
import matplotlib.pyplot as plt
from spotpython.fun.objectivefunctions import Analytical
from spotpython.spot import Spot
from spotpython.utils.init import (fun_control_init, design_control_init, surrogate_control_init, optimizer_control_init)
from spotpython.data.diabetes import Diabetes
from spotpython.hyperdict.light_hyper_dict import LightHyperDict
from spotpython.fun.hyperlight import HyperLight
from spotpython.utils.eda import print_exp_table, print_res_table12 Introduction to Sequential Parameter Optimization
The following libraries are used in this document:
This presents an introduction to spotpythons’s Spot class. The official spotpython documentation can be found here: https://sequential-parameter-optimization.github.io/spotpython/.
12.1 Surrogate Model Based Optimization
Surrogate model based optimization methods are common approaches in simulation and optimization. The sequential parameter optimization toolbox (SPOT) was developed because there is a great need for sound statistical analysis of simulation and optimization algorithms (Bartz-Beielstein, Lasarczyk, and Preuss 2005). SPOT includes methods for tuning based on classical regression and analysis of variance techniques. It presents tree-based models such as classification and regression trees and random forests as well as Bayesian optimization (Gaussian process models, also known as Kriging). Combinations of different meta-modeling approaches are possible. SPOT comes with a sophisticated surrogate model based optimization method, that can handle discrete and continuous inputs. Furthermore, any model implemented in scikit-learn can be used out-of-the-box as a surrogate in spotpython.
SPOT implements key techniques such as exploratory fitness landscape analysis and sensitivity analysis. It can be used to understand the performance of various algorithms, while simultaneously giving insights into their algorithmic behavior.
The spot loop consists of the following steps:
- Init: Build initial design \(X\) using the
designmethod, e.g., Latin Hypercube Sampling (LHS). - Evaluate initial design on real objective \(f\): \(y = f(X)\) using the
funmethod, e.g.,fun_sphere. - Build surrogate: \(S = S(X,y)\), using the
fitmethod of the surrogate model, e.g.,Kriging. - Optimize on surrogate: \(X_0 = \text{optimize}(S)\), using the
optimizermethod, e.g.,differential_evolution. - Evaluate on real objective: \(y_0 = f(X_0)\), using the
funmethod from above. - Impute (Infill) new points: \(X = X \cup X_0\), \(y = y \cup y_0\), using
Spot’sinfillmethod. - Goto 3.
12.2 Advantages of the spotpython Approach
Neural networks and many ML algorithms are non-deterministic, so results are noisy (i.e., depend on the the initialization of the weights). Enhanced noise handling strategies, OCBA (description from HPT-book).
Optimal Computational Budget Allocation (OCBA) is a very efficient solution to solve the “general ranking and selection problem” if the objective function is noisy. It allocates function evaluations in an uneven manner to identify the best solutions and to reduce the total optimization costs. [Chen10a, Bart11b] Given a total number of optimization samples \(N\) to be allocated to \(k\) competing solutions whose performance is depicted by random variables with means \(\bar{y}_i\) (\(i=1, 2, \ldots, k\)), and finite variances \(\sigma_i^2\), respectively, as \(N \to \infty\), the can be asymptotically maximized when \[\begin{align} \frac{N_i}{N_j} & = \left( \frac{ \sigma_i / \delta_{b,i}}{\sigma_j/ \delta_{b,j}} \right)^2, i,j \in \{ 1, 2, \ldots, k\}, \text{ and } i \neq j \neq b,\\ N_b &= \sigma_b \sqrt{ \sum_{i=1, i\neq b}^k \frac{N_i^2}{\sigma_i^2} }, \end{align}\] where \(N_i\) is the number of replications allocated to solution \(i\), \(\delta_{b,i} = \bar{y}_b - \bar{y}_i\), and \(\bar{y}_b \leq \min_{i\neq b} \bar{y}_i\) Bartz-Beielstein and Friese (2011).
Surrogate-based optimization: Better than grid search and random search (Reference to HPT-book)
Visualization
Importance based on the Kriging model
Sensitivity analysis. Exploratory fitness landscape analysis. Provides XAI methods (feature importance, integrated gradients, etc.)
Uncertainty quantification
Flexible, modular meta-modeling handling.
spotpythoncomes with a Kriging model, which can be replaced by any model implemented inscikit-learn.Enhanced metric handling, especially for categorical hyperparameters (any
sklearnmetric can be used). Default is..Integration with
TensorBoard: Visualization of the hyperparameter tuning process, of the training steps, the model graph. Parallel coordinates plot, scatter plot matrix, and more.Reproducibility. Results are stored as pickle files. The results can be loaded and visualized at any time and be transferred between different machines and operating systems.
Handles
scikit-learnmodels andPyTorchmodels out-of-the-box. The user has to add a simple wrapper for passing the hyperparameters to use aPyTorchmodel inspotpython.Compatible with
Lightning.User can add own models as plain python code.
User can add own data sets in various formats.
Flexible data handling and data preprocessing.
Many examples online (hyperparameter-tuning-cookbook).
spotpythonuses a robust optimizer that can even deal with hyperparameter-settings that cause crashes of the algorithms to be tuned.even if the optimum is not found, HPT with
spotpythonprevents the user from choosing bad hyperparameters in a systematic way (design of experiments).
12.3 Disadvantages of the spotpython Approach
- Time consuming
- Surrogate can be misguiding
12.4 An Initial Example: Optimization of the One-dimensional Sphere Function
12.4.1 The Objective Function: Sphere
The spotpython package provides several classes of objective functions. We will use the sphere-function, which is an analytical objective function. Analytical functions can be described by a (closed) formula: \[
f(x) = x^2.
\]
fun = Analytical().fun_sphere
x = np.linspace(-1, 1, 100).reshape(-1,1)
y = fun(x)
plt.figure()
plt.plot(x,y, "k")
plt.grid()
plt.xlabel("x")
plt.ylabel("f(x)")
plt.title("Sphere Function")
plt.show()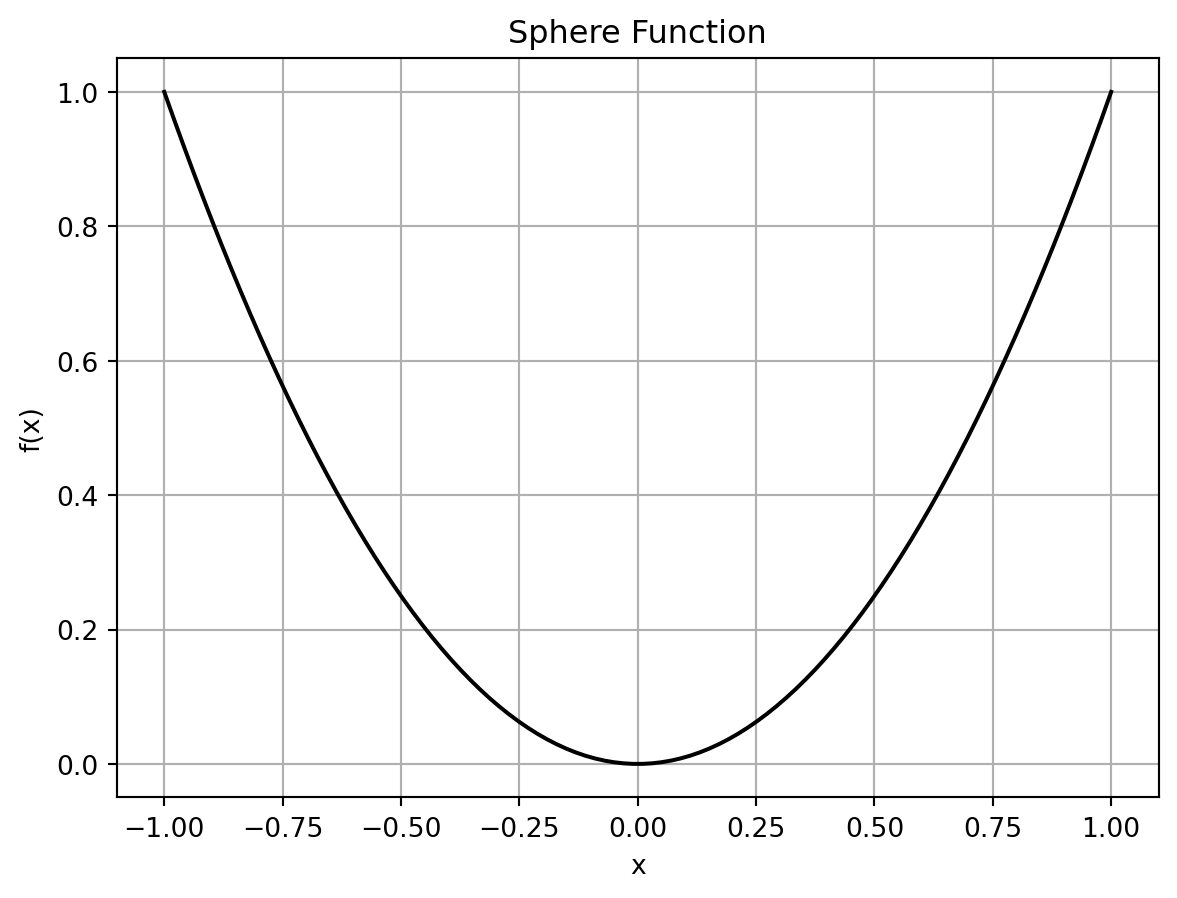
The optimal solution of the sphere function is \(x^* = 0\) with \(f(x^*) = 0\).
12.4.2 The Spot Method as an Optimization Algorithm Using a Surrogate Model
pyspot implements the Spot method. The Spot method uses a surrogate model to approximate the objective function and to find the optimal solution by performing an optimization on the surrogate model. In this example, Spot uses ten initial design points, which are sampled from a Latin Hypercube Sampling (LHS) design. The Spot method will then build a surrogate model based on these initial design points and the corresponding objective function values. The surrogate model is then used to find the optimal solution. As a default, Spot uses a Kriging surrogate model, which is a Gaussian process model. As a default, ten initial design points are sampled from a Latin Hypercube Sampling (LHS) design. Also as a default, 15 function evaluations are performed, i.e., the final surrogate model is built based on 15 points.
The specification of the lower and upper bounds of the input space is mandatory via the fun_control dictionary, is passed to the Spot method. For convenience, spotpython provides an initialization method fun_control_init() to create the fun_control dictionary. After the Spot method is initialized, the run() method is called to start the optimization process. The run() method will perform the optimization on the surrogate model and return the optimal solution. Finally, the print_results() method is called to print the results of the optimization process, i.e., the best objective function value (“min y”) and the corresponding input value (“x0”).
fun_control=fun_control_init(lower = np.array([-1]),
upper = np.array([1]))
S = Spot(fun=fun, fun_control=fun_control)
S.run()
S.print_results()spotpython tuning: 2.4412172266370036e-09 [#######---] 73.33%. Success rate: 100.00%
spotpython tuning: 2.032431480352692e-09 [########--] 80.00%. Success rate: 100.00%
spotpython tuning: 2.032431480352692e-09 [#########-] 86.67%. Success rate: 66.67%
spotpython tuning: 2.032431480352692e-09 [#########-] 93.33%. Success rate: 50.00%
spotpython tuning: 1.2228307315407816e-10 [##########] 100.00%. Success rate: 60.00% Done...
Experiment saved to 000_res.pkl
min y: 1.2228307315407816e-10
x0: 1.1058167712332733e-05[['x0', np.float64(1.1058167712332733e-05)]]spotpython provides a method plot_progress() to visualize the search progress. The parameter log_y is used to plot the objective function values on a logarithmic scale. The black points represent the ten initial design points, whereas the remainin g five red points represent the points found by the surrogate model based optimization.
S.plot_progress(log_y=True)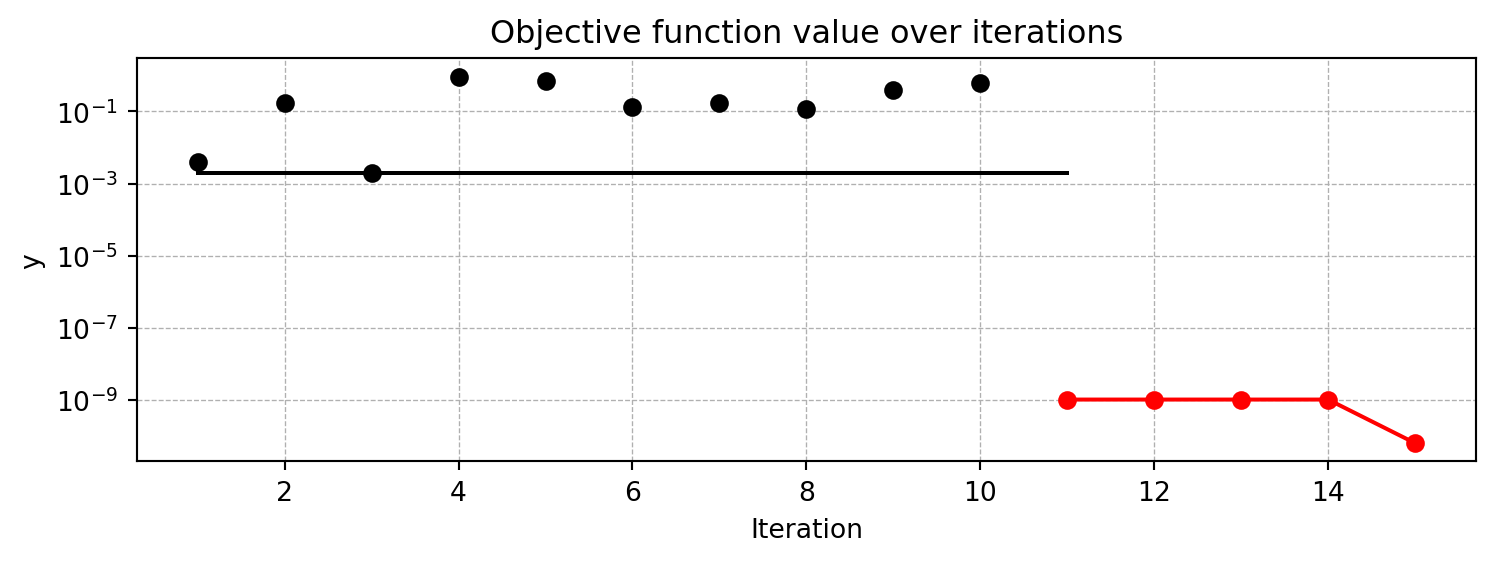
S.surrogate_control{'log_level': 50,
'method': 'regression',
'model_optimizer': <function scipy.optimize._differentialevolution.differential_evolution(func, bounds, args=(), strategy='best1bin', maxiter=1000, popsize=15, tol=0.01, mutation=(0.5, 1), recombination=0.7, rng=None, callback=None, disp=False, polish=True, init='latinhypercube', atol=0, updating='immediate', workers=1, constraints=(), x0=None, *, integrality=None, vectorized=False, seed=None)>,
'model_fun_evals': 10000,
'min_theta': -3.0,
'max_theta': 2.0,
'isotropic': False,
'kernel': 'gauss',
'kernel_params': {},
'p_val': 2.0,
'n_p': 1,
'optim_p': False,
'min_Lambda': -9,
'max_Lambda': 0,
'seed': 124,
'theta_init_zero': False,
'var_type': ['num'],
'metric_factorial': 'canberra',
'use_nystrom': False,
'nystrom_m': 20,
'nystrom_seed': 1234,
'max_surrogate_points': 30}12.5 A Second Example: Optimization of a User-Specified Multi-dimensional Function
Users can easily specify their own objective functions. The following example shows how to use the Spot method to optimize a user-specified two-dimensional function. Here we will use the 2-dimensional Branin function, which is a well-known test function in optimization. The Branin function is defined as follows: \[
f(x) = a (x2 - bx1^2 + cx1 - r)^2 + s(1-t) \cos(x1) + s
\] where:
- \(a = 1\),
- \(b = 5.1/(4\pi^2)\),
- \(c = 5/\pi\),
- \(r = 6\),
- \(s = 10\), and
- \(t = 1/(8\pi)\).
The input space is defined as \(x_1 \in [-5, 10]\) and \(x_2 \in [0, 15]\). The user specified Branin function can be implemented as follows (note, that the function is vectorized, i.e., it can handle multiple input points at once and that the **kwargs argument is mandatory for compatibility with spotpython to pass additional parameters to the function, if needed):
def user_fun(X, **kwargs):
x1 = X[:, 0]
x2 = X[:, 1]
a = 1
b = 5.1 / (4 * np.pi**2)
c = 5 / np.pi
r = 6
s = 10
t = 1 / (8 * np.pi)
y = a * (x2 - b * x1**2 + c * x1 - r)**2 + s * (1 - t) * np.cos(x1) + s
return yThe Branin function has its global minimum at three points: \(f(x^*) = 0.397887\), at \(x^* = (-\pi, 12.275)\), \((\pi, 2.275)\) and \((9.42478, 2.475)\). It can be visualized as shown in Figure 12.2.
x1 = np.linspace(-5, 10, 100)
x2 = np.linspace(0, 15, 100)
X1, X2 = np.meshgrid(x1, x2)
Z = user_fun(np.array([X1.ravel(), X2.ravel()]).T)
Z = Z.reshape(X1.shape)
plt.figure(figsize=(8, 6))
plt.contourf(X1, X2, Z, levels=30, cmap='jet')
plt.colorbar(label='f(x)')
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('Branin Function')
plt.scatter([-np.pi, np.pi, 9.42478], [12.275, 2.275, 2.475], color='white', label='Global Minima')
plt.legend()
plt.show()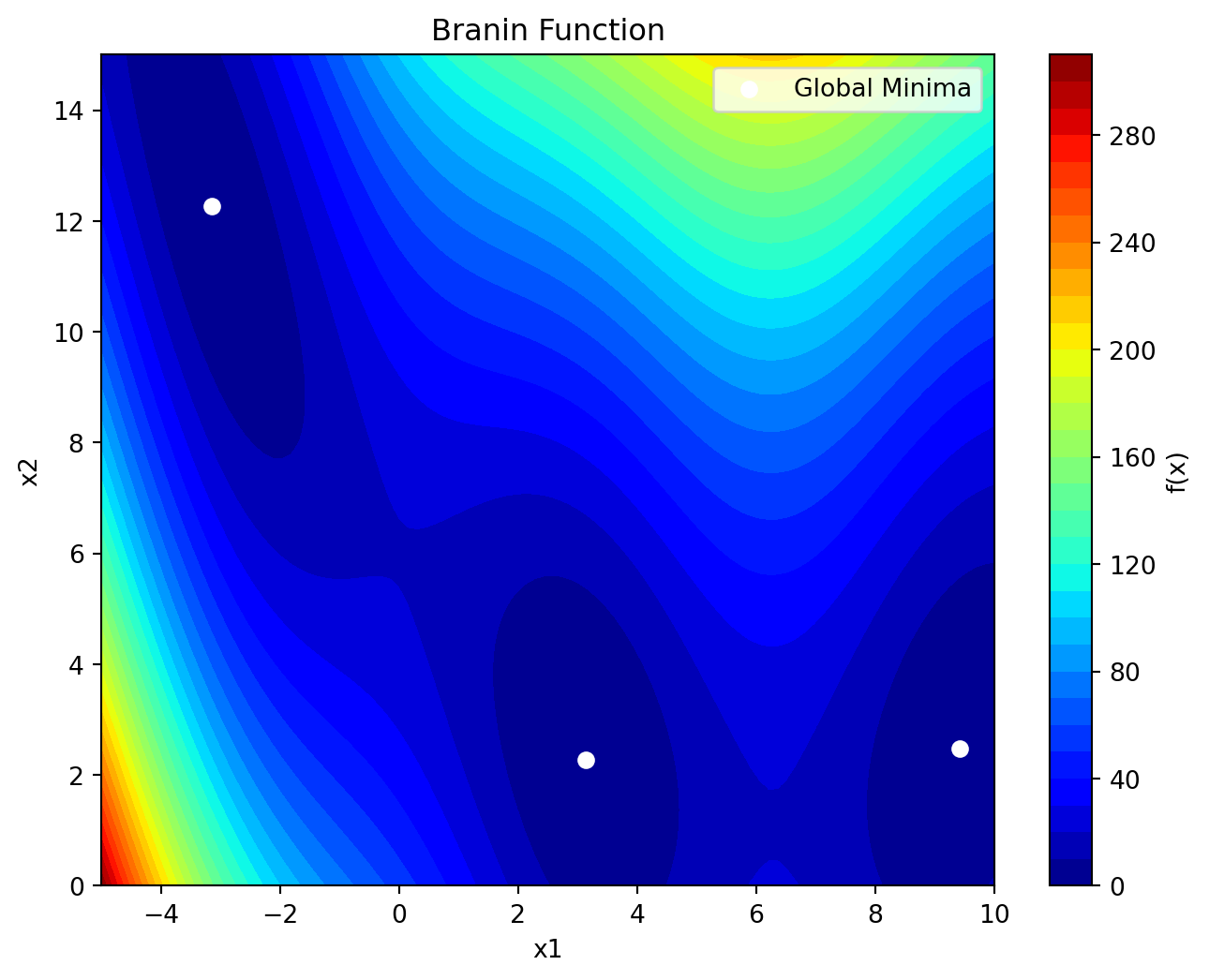
The default Spot class assumes a noisy objective function, because many real-world applications have noisy objective functions. Here, we will set the noise parameter to False in the fun_control dictionary, because the Branin function is a deterministic function. Accordingly, the interpolation surrogate method is used, which is suitable for deterministic functions. Therefore, we need to specify the interpolation method in the surrogate_control dictionary. Furthermore, since the Branin is harder to optimize than the sphere function, we will increase the number of function evaluations to 25 and the number of initial design points to 15.
fun_control = fun_control_init(
lower = np.array( [-5, 0]),
upper = np.array([10, 15]),
fun_evals = 25,
noise = False,
seed=123
)
design_control=design_control_init(init_size=15)
surrogate_control=surrogate_control_init(method="interpolation")
S_2 = Spot(fun=user_fun,
fun_control=fun_control,
design_control=design_control,
surrogate_control=surrogate_control)
S_2.run()
S_2.print_results()
S_2.plot_progress(log_y=True)spotpython tuning: 3.1165078710223124 [######----] 64.00%. Success rate: 0.00%
spotpython tuning: 2.323465946406328 [#######---] 68.00%. Success rate: 50.00%
spotpython tuning: 0.7636114164021386 [#######---] 72.00%. Success rate: 66.67%
spotpython tuning: 0.7636114164021386 [########--] 76.00%. Success rate: 50.00%
spotpython tuning: 0.7134874467492036 [########--] 80.00%. Success rate: 60.00%
spotpython tuning: 0.5278720689655838 [########--] 84.00%. Success rate: 66.67%
spotpython tuning: 0.4032724486704513 [#########-] 88.00%. Success rate: 71.43%
spotpython tuning: 0.39848208189117607 [#########-] 92.00%. Success rate: 75.00%
spotpython tuning: 0.3984371737124537 [##########] 96.00%. Success rate: 77.78%
spotpython tuning: 0.3984371737124537 [##########] 100.00%. Success rate: 70.00% Done...
Experiment saved to 000_res.pkl
min y: 0.3984371737124537
x0: -3.144600358136924
x1: 12.30473238732154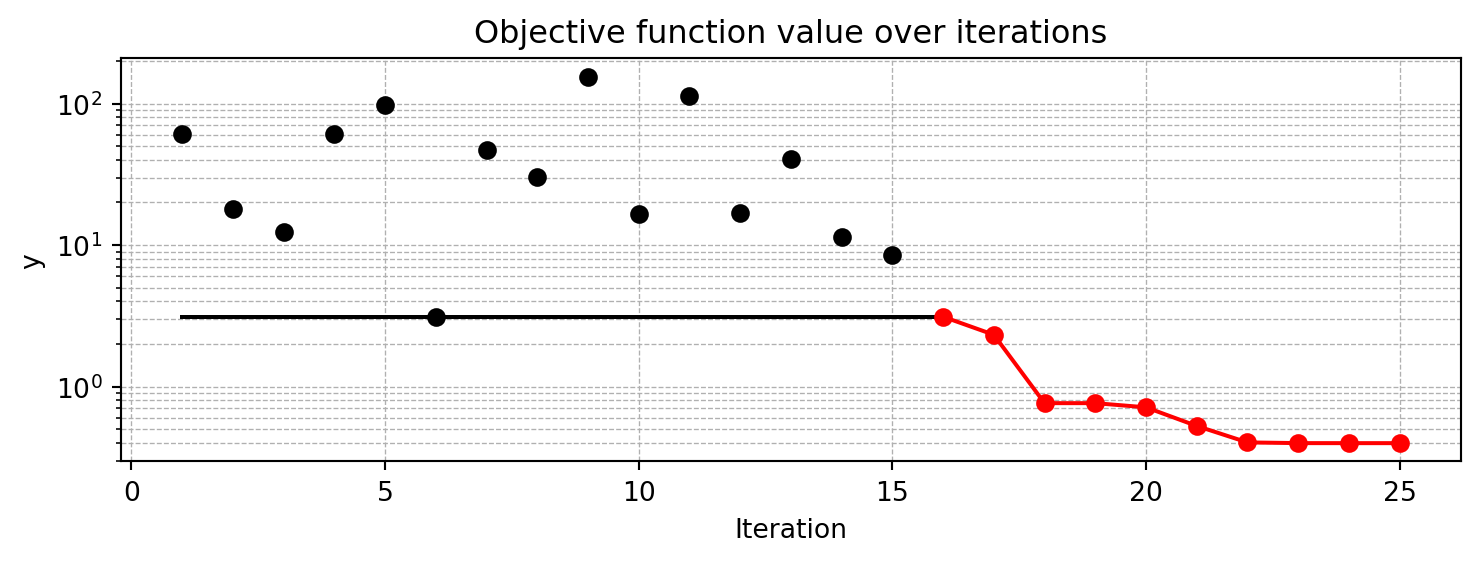
The resulting surrogate used by Spot can be visualized as shown in Figure 12.3.
S_2.plot_contour()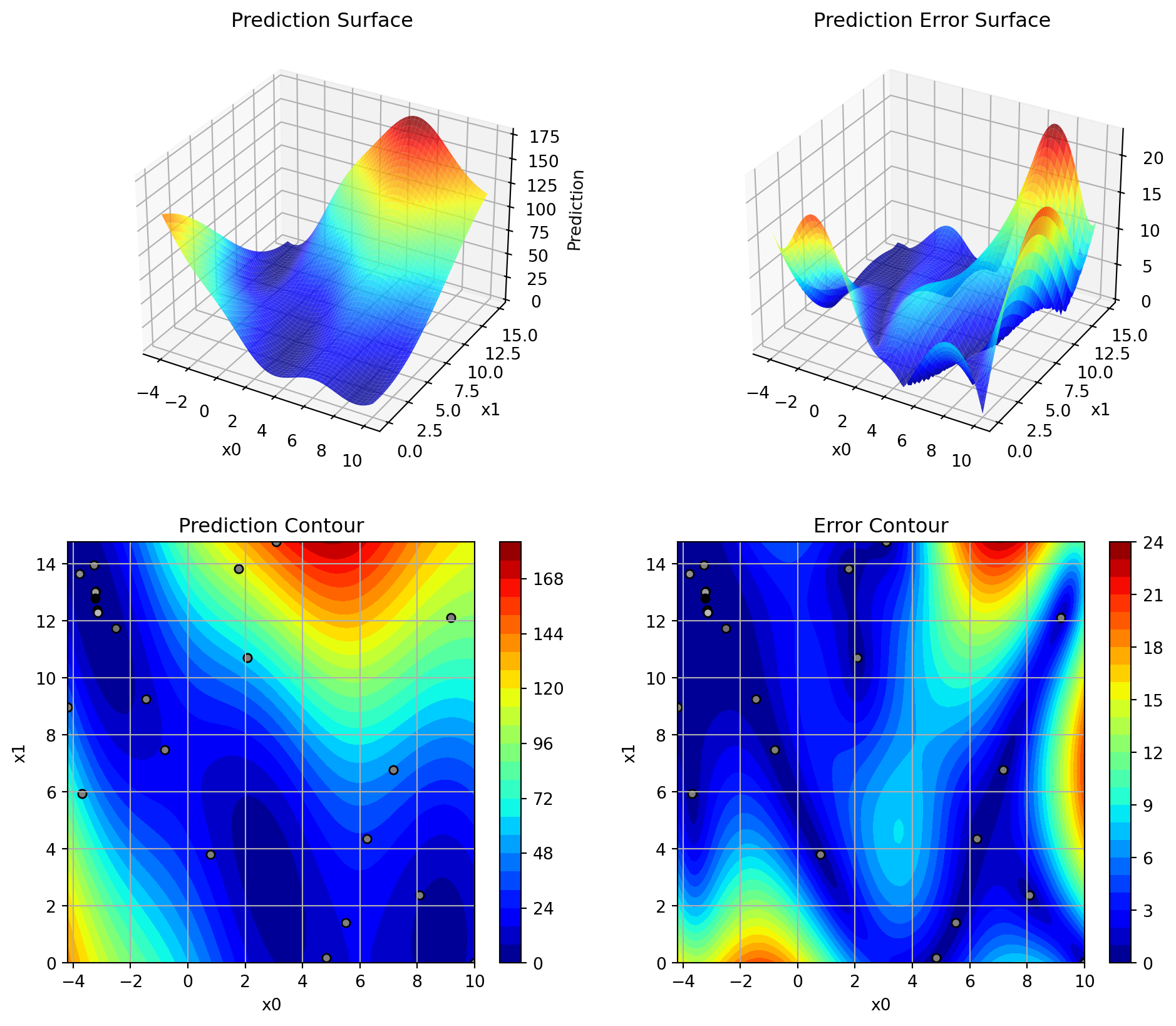
S_2.surrogate_control{'log_level': 50,
'method': 'interpolation',
'model_optimizer': <function scipy.optimize._differentialevolution.differential_evolution(func, bounds, args=(), strategy='best1bin', maxiter=1000, popsize=15, tol=0.01, mutation=(0.5, 1), recombination=0.7, rng=None, callback=None, disp=False, polish=True, init='latinhypercube', atol=0, updating='immediate', workers=1, constraints=(), x0=None, *, integrality=None, vectorized=False, seed=None)>,
'model_fun_evals': 10000,
'min_theta': -3.0,
'max_theta': 2.0,
'isotropic': False,
'kernel': 'gauss',
'kernel_params': {},
'p_val': 2.0,
'n_p': 1,
'optim_p': False,
'min_Lambda': -9,
'max_Lambda': 0,
'seed': 124,
'theta_init_zero': False,
'var_type': ['num', 'num'],
'metric_factorial': 'canberra',
'use_nystrom': False,
'nystrom_m': 20,
'nystrom_seed': 1234,
'max_surrogate_points': 30}12.6 A Third Example: Hyperparameter Tuning of a Neural Network
spotpython provides several PyTorch neural networks, which can be used out-of-the-box for hyperparameter tuning. We will use the Diabetes dataset, which is a regression dataset with 10 input features and one output feature.
Similar to the steps from above, we define the fun_control dictionary. The hyperparameter tuning of neural networks requires a few additional parameters in the fun_control dictionary, e.g., for selecting the neural network model, the hyperparameter dictionary, and the number of input and output features of the neural network. The fun_control dictionary is initialized using the fun_control_init() method. The following parameters are used:
- The
core_model_nameparameter specifies the neural network model to be used. In this case, we will use theNNLinearRegressor, which is a simple linear regression model implemented inspotpython. - The
hyperdictparameter specifies the hyperparameter dictionary to be used. In this case, we will use theLightHyperDict, which is a hyperparameter dictionary for light-weight models. _L_inand_L_outspecify the number of input and output features of the neural network, respectively. In this case, we will use 10 input features and 1 output feature, which are required for theDiabetesdataset.
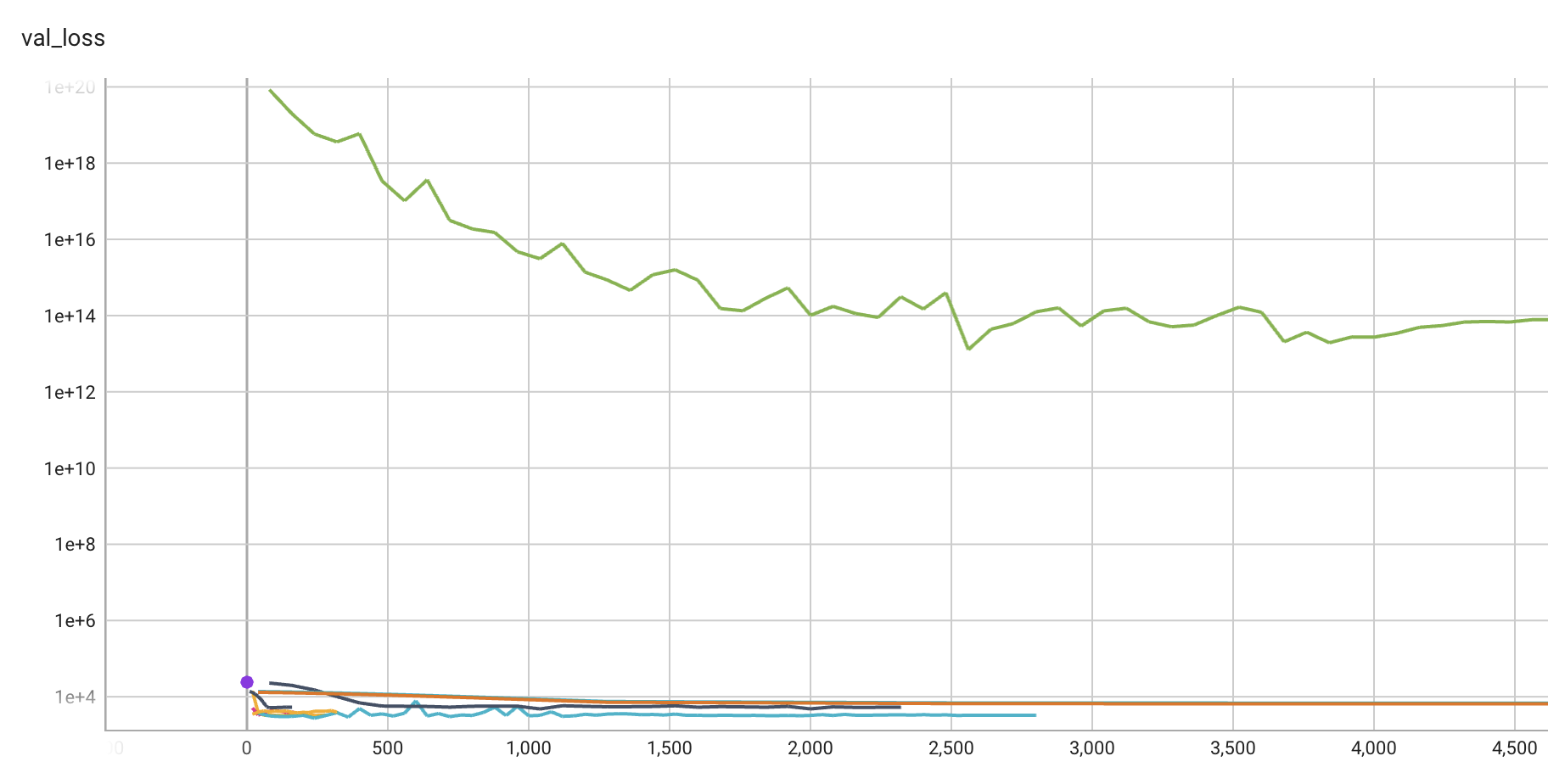
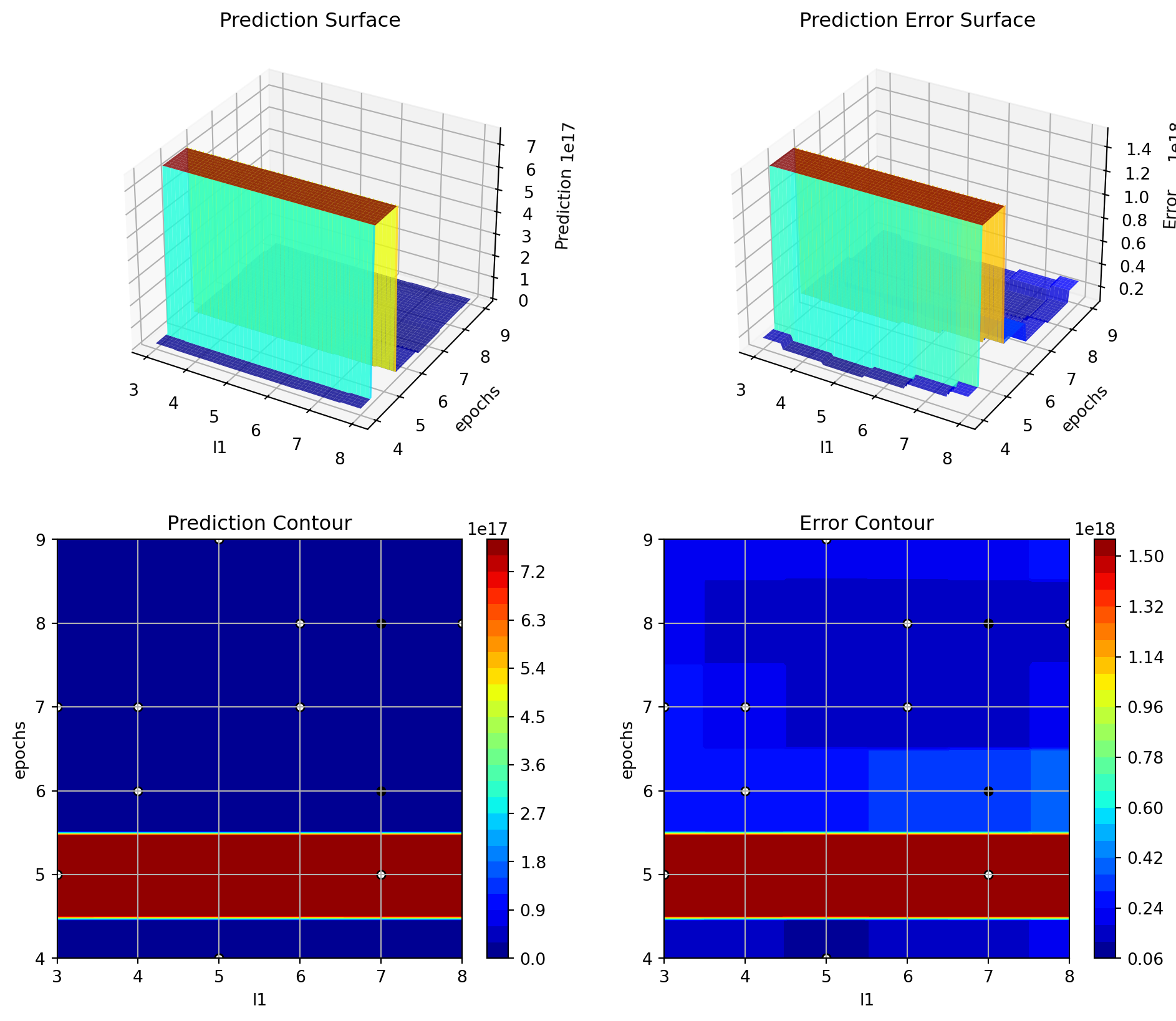
Sometimes, very bad configurations appear in the initial design, leading to an unnecessarily long optimization process. An example is illustrated in Figure 12.4. To avoid this, we can set a divergence threshold in the fun_control dictionary. The divergence_threshold parameter is used to stop the optimization process if the objective function value exceeds a certain threshold. This is useful to avoid long optimization processes if the objective function is not well-behaved. We have set the divergence_threshold=5_000.
fun_control = fun_control_init(
PREFIX="S_3",
max_time=1,
data_set = Diabetes(),
core_model_name="light.regression.NNLinearRegressor",
hyperdict=LightHyperDict,
divergence_threshold=5_000,
_L_in=10,
_L_out=1)
S_3 = Spot(fun=HyperLight().fun,
fun_control=fun_control)
S_3.surrogate_controlmodule_name: light
submodule_name: regression
model_name: NNLinearRegressor{'log_level': 50,
'method': 'regression',
'model_optimizer': <function scipy.optimize._differentialevolution.differential_evolution(func, bounds, args=(), strategy='best1bin', maxiter=1000, popsize=15, tol=0.01, mutation=(0.5, 1), recombination=0.7, rng=None, callback=None, disp=False, polish=True, init='latinhypercube', atol=0, updating='immediate', workers=1, constraints=(), x0=None, *, integrality=None, vectorized=False, seed=None)>,
'model_fun_evals': 10000,
'min_theta': -3.0,
'max_theta': 2.0,
'isotropic': False,
'kernel': 'gauss',
'kernel_params': {},
'p_val': 2.0,
'n_p': 1,
'optim_p': False,
'min_Lambda': -9,
'max_Lambda': 0,
'seed': 124,
'theta_init_zero': False,
'var_type': ['int',
'int',
'int',
'factor',
'factor',
'float',
'float',
'int',
'factor',
'factor'],
'metric_factorial': 'canberra',
'use_nystrom': False,
'nystrom_m': 20,
'nystrom_seed': 1234,
'max_surrogate_points': 30}S_3.run()
S_3.print_results()
S_3.plot_progress(log_y=True)┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.7 M │ train │ 407 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.7 M Non-trainable params: 0 Total params: 12.7 M Total estimated model params size (MB): 50 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 407 M
train_model result: {'val_loss': 13860.1416015625, 'hp_metric': 13860.1416015625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 409 K │ [4, 10] │ [4, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 409 K
train_model result: {'val_loss': 5115.263671875, 'hp_metric': 5115.263671875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 50.9 M │ train │ 813 M │ [8, 10] │ [8, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M Non-trainable params: 0 Total params: 50.9 M Total estimated model params size (MB): 203 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 813 M
train_model result: {'val_loss': 5342.6416015625, 'hp_metric': 5342.6416015625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 807 K │ train │ 12.8 M │ [8, 10] │ [8, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 807 K Non-trainable params: 0 Total params: 807 K Total estimated model params size (MB): 3 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 12.8 M
train_model result: {'val_loss': 14175.4755859375, 'hp_metric': 14175.4755859375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 3.2 M │ train │ 25.5 M │ [4, 10] │ [4, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 3.2 M Non-trainable params: 0 Total params: 3.2 M Total estimated model params size (MB): 12 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 25.5 M
train_model result: {'val_loss': nan, 'hp_metric': nan}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.7 M │ train │ 50.9 M │ [2, 10] │ [2, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 12.7 M Non-trainable params: 0 Total params: 12.7 M Total estimated model params size (MB): 50 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 50.9 M
train_model result: {'val_loss': 5.328983764888453e+18, 'hp_metric': 5.328983764888453e+18}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 3.2 M │ [8, 10] │ [8, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 3.2 M
train_model result: {'val_loss': nan, 'hp_metric': nan}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 807 K │ train │ 3.2 M │ [2, 10] │ [2, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 807 K Non-trainable params: 0 Total params: 807 K Total estimated model params size (MB): 3 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.2 M
train_model result: {'val_loss': 22902.03125, 'hp_metric': 22902.03125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 1.6 M │ [4, 10] │ [4, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 11929.5634765625, 'hp_metric': 11929.5634765625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 3.2 M │ train │ 102 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 3.2 M Non-trainable params: 0 Total params: 3.2 M Total estimated model params size (MB): 12 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 102 M
train_model(): trainer.fit failed with exception: SparseAdam does not support dense gradients, please consider Adam insteadtrain_model result: {'val_loss': 24054.533203125, 'hp_metric': 24054.533203125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.8 M │ train │ 407 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M Non-trainable params: 0 Total params: 12.8 M Total estimated model params size (MB): 51 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 407 M
train_model result: {'val_loss': 17948.6796875, 'hp_metric': 17948.6796875}
spotpython tuning: 5115.263671875 [######----] 60.00%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.8 M │ train │ 101 M │ [4, 10] │ [4, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M Non-trainable params: 0 Total params: 12.8 M Total estimated model params size (MB): 51 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 101 M
train_model(): trainer.fit failed with exception: SparseAdam does not support dense gradients, please consider Adam instead
train_model result: {'val_loss': 104114438144.0, 'hp_metric': 104114438144.0}
spotpython tuning: 5115.263671875 [#######---] 66.67%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.8 M │ train │ 407 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M Non-trainable params: 0 Total params: 12.8 M Total estimated model params size (MB): 51 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 407 M
train_model(): trainer.fit failed with exception: SparseAdam does not support dense gradients, please consider Adam instead
train_model result: {'val_loss': 3014937856.0, 'hp_metric': 3014937856.0}
spotpython tuning: 5115.263671875 [#######---] 73.33%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 50.9 M │ train │ 1.6 B │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 50.9 M Non-trainable params: 0 Total params: 50.9 M Total estimated model params size (MB): 203 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 1.6 B
train_model result: {'val_loss': 15521.505859375, 'hp_metric': 15521.505859375}
spotpython tuning: 5115.263671875 [########--] 80.00%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 1.6 M │ [4, 10] │ [4, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 17394.609375, 'hp_metric': 17394.609375}
spotpython tuning: 5115.263671875 [#########-] 86.67%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.8 M │ train │ 203 M │ [8, 10] │ [8, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M Non-trainable params: 0 Total params: 12.8 M Total estimated model params size (MB): 51 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 203 M
train_model result: {'val_loss': 5266.83984375, 'hp_metric': 5266.83984375}
spotpython tuning: 5115.263671875 [#########-] 93.33%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 12.8 M │ train │ 407 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 12.8 M Non-trainable params: 0 Total params: 12.8 M Total estimated model params size (MB): 51 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 407 M
train_model result: {'val_loss': 23922.74609375, 'hp_metric': 23922.74609375}
spotpython tuning: 5115.263671875 [##########] 100.00%. Success rate: 0.00% Done...
Experiment saved to S_3_res.pkl
min y: 5115.263671875
l1: 3.0
epochs: 7.0
batch_size: 2.0
act_fn: 2.0
optimizer: 2.0
dropout_prob: 0.184251494885258
lr_mult: 3.1418668140600845
patience: 6.0
batch_norm: 0.0
initialization: 2.0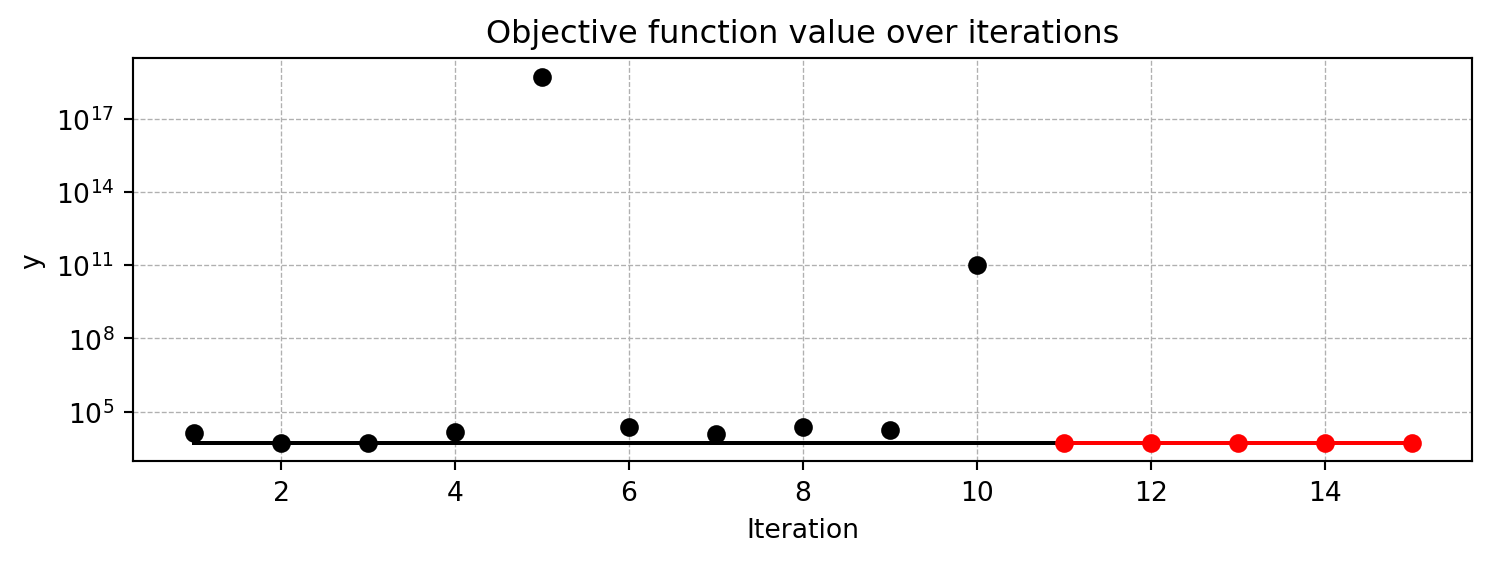
Results can be printed using Spot’s print_results() method. The results include the best objective function value, the corresponding input values, and the number of function evaluations.
results = S_3.print_results()min y: 5115.263671875
l1: 3.0
epochs: 7.0
batch_size: 2.0
act_fn: 2.0
optimizer: 2.0
dropout_prob: 0.184251494885258
lr_mult: 3.1418668140600845
patience: 6.0
batch_norm: 0.0
initialization: 2.0S_3.surrogate_control{'log_level': 50,
'method': 'regression',
'model_optimizer': <function scipy.optimize._differentialevolution.differential_evolution(func, bounds, args=(), strategy='best1bin', maxiter=1000, popsize=15, tol=0.01, mutation=(0.5, 1), recombination=0.7, rng=None, callback=None, disp=False, polish=True, init='latinhypercube', atol=0, updating='immediate', workers=1, constraints=(), x0=None, *, integrality=None, vectorized=False, seed=None)>,
'model_fun_evals': 10000,
'min_theta': -3.0,
'max_theta': 2.0,
'isotropic': False,
'kernel': 'gauss',
'kernel_params': {},
'p_val': 2.0,
'n_p': 1,
'optim_p': False,
'min_Lambda': -9,
'max_Lambda': 0,
'seed': 124,
'theta_init_zero': False,
'var_type': ['int',
'int',
'int',
'factor',
'factor',
'float',
'float',
'int',
'factor',
'factor'],
'metric_factorial': 'canberra',
'use_nystrom': False,
'nystrom_m': 20,
'nystrom_seed': 1234,
'max_surrogate_points': 30}A formatted table of the results can be printed using the print_res_table() method:
print_res_table(S_3)| name | type | default | lower | upper | tuned | transform | importance | stars |
|----------------|--------|-----------|---------|---------|--------------------|-----------------------|--------------|---------|
| l1 | int | 3 | 3.0 | 8.0 | 3.0 | transform_power_2_int | 0.00 | |
| epochs | int | 4 | 4.0 | 9.0 | 7.0 | transform_power_2_int | 100.00 | *** |
| batch_size | int | 4 | 1.0 | 4.0 | 2.0 | transform_power_2_int | 0.00 | |
| act_fn | factor | ReLU | 0.0 | 5.0 | ReLU | None | 0.00 | |
| optimizer | factor | SGD | 0.0 | 11.0 | Adam | None | 0.00 | |
| dropout_prob | float | 0.01 | 0.0 | 0.25 | 0.184251494885258 | None | 0.00 | |
| lr_mult | float | 1.0 | 0.1 | 10.0 | 3.1418668140600845 | None | 0.00 | |
| patience | int | 2 | 2.0 | 6.0 | 6.0 | transform_power_2_int | 0.00 | |
| batch_norm | factor | 0 | 0.0 | 1.0 | 0 | None | 0.03 | |
| initialization | factor | Default | 0.0 | 4.0 | kaiming_normal | None | 0.00 | |The fitness landscape can be visualized using the plot_important_hyperparameter_contour() method:
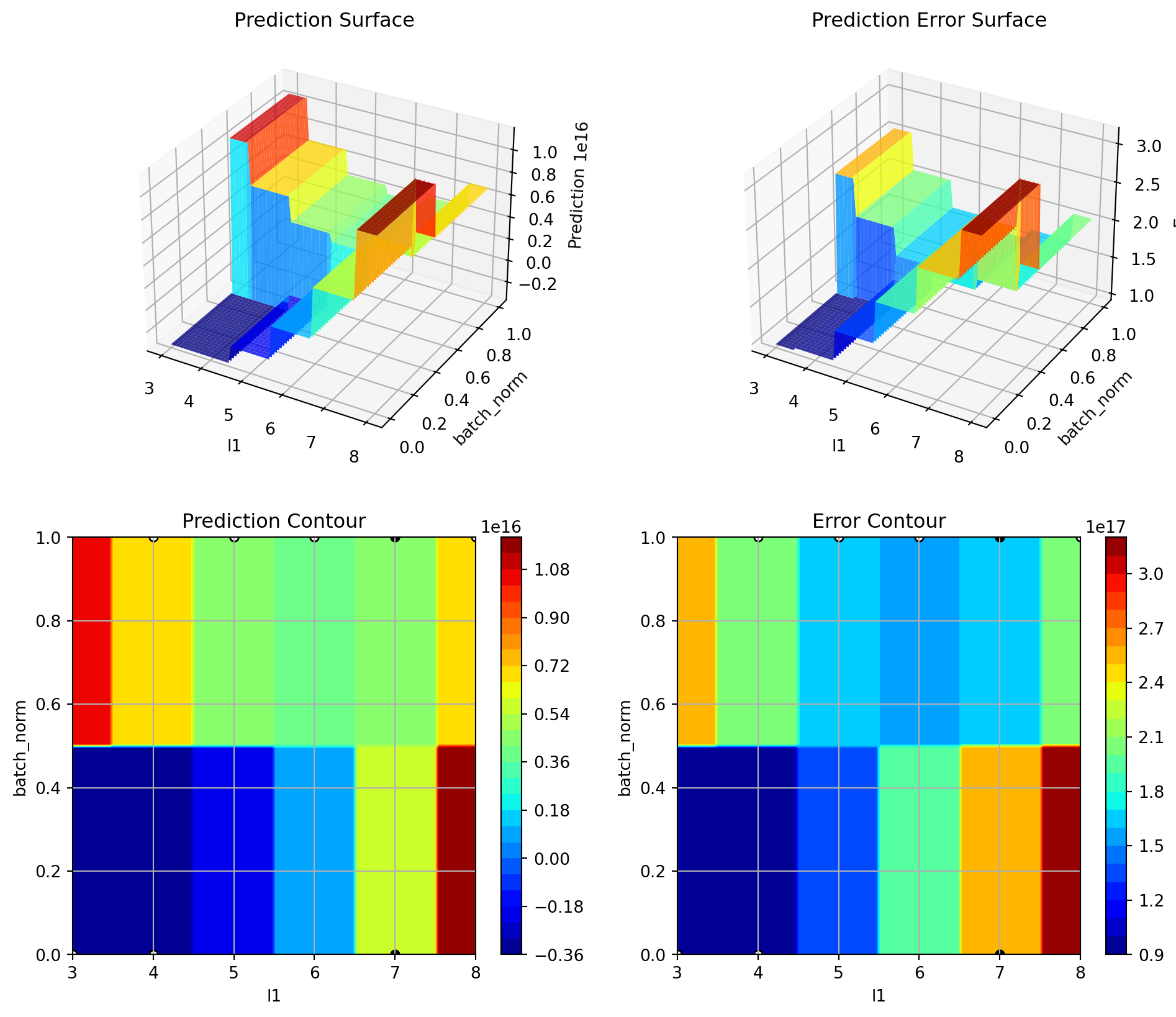
S_3.plot_important_hyperparameter_contour(max_imp=3)l1: 0.001217746922356549
epochs: 100.0
batch_size: 0.001217746922356549
act_fn: 0.001217746922356549
optimizer: 0.001217746922356549
dropout_prob: 0.001217746922356549
lr_mult: 0.001217746922356549
patience: 0.001217746922356549
batch_norm: 0.028897599107519437
initialization: 0.001217746922356549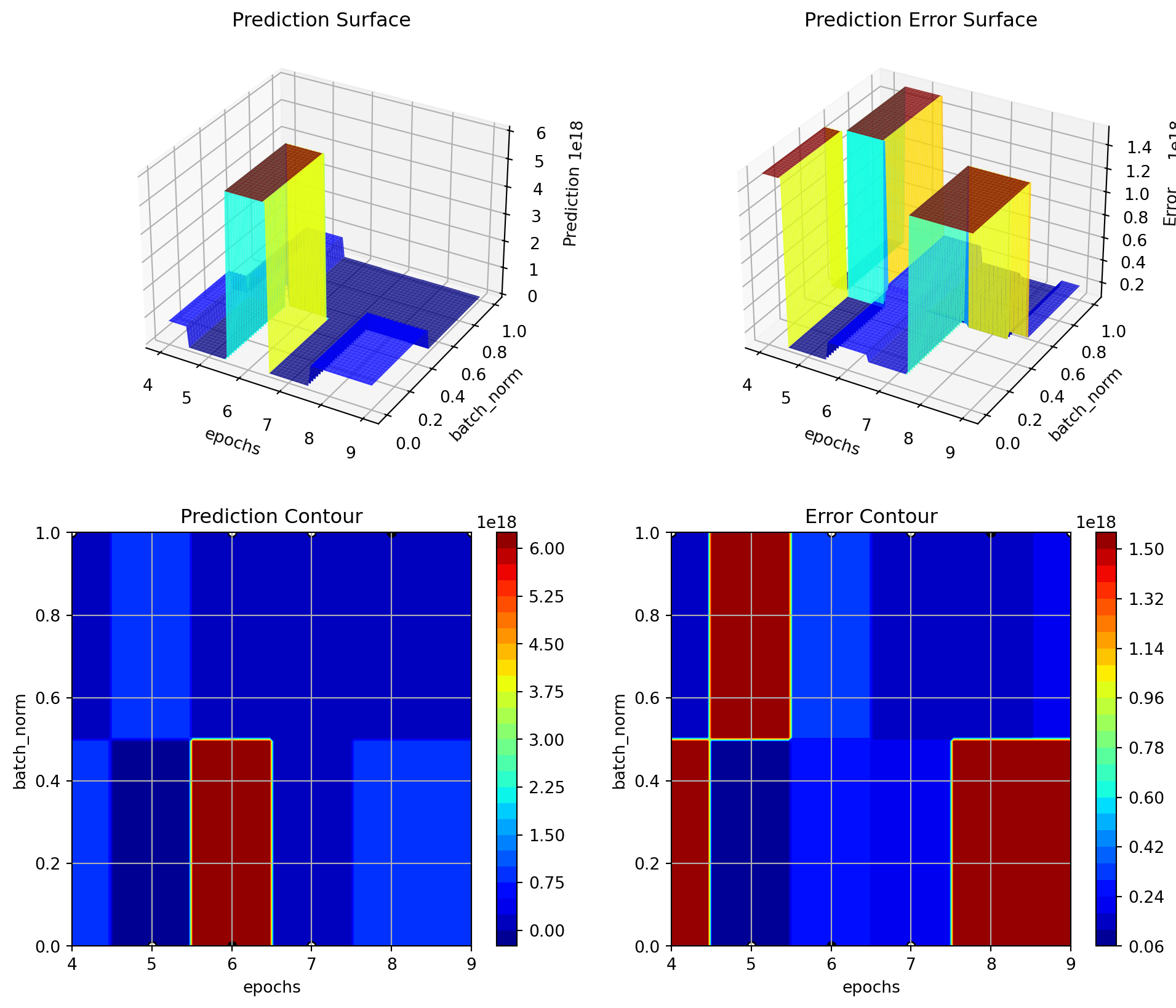
12.7 Organization
Spot organizes the surrogate based optimization process in four steps:
- Selection of the objective function:
fun. - Selection of the initial design:
design. - Selection of the optimization algorithm:
optimizer. - Selection of the surrogate model:
surrogate.
For each of these steps, the user can specify an object:
from spotpython.fun.objectivefunctions import Analytical
fun = Analytical().fun_sphere
from spotpython.design.spacefilling import SpaceFilling
design = SpaceFilling(2)
from scipy.optimize import differential_evolution
optimizer = differential_evolution
from spotpython.surrogate.kriging import Kriging
surrogate = Kriging()For each of these steps, the user can specify a dictionary of control parameters.
fun_controldesign_controloptimizer_controlsurrogate_control
Each of these dictionaries has an initialization method, e.g., fun_control_init(). The initialization methods set the default values for the control parameters.
ImportantImportant:
- The specification of an lower bound in
fun_controlis mandatory.
12.8 Summary: Basic Attributes and Methods of the Spot Object
The Spot class organizes the surrogate based optimization process into the
funobject with dictionryfun_control,designobject with dictionarydesign_control,optimizerobject with dictionaryoptimizer_control, andsurrogateobject with dictionarysurrogate_control.
| Object | Description | Default |
|---|---|---|
fun |
Can be one of the following: (1) any function from spotpython.fun.*, e.g., fun_rosen, (2) a user-specified function (vectorized and accepting the **kwargs argument as, e.g., in Section 12.5), or, (3) if PyTorch hyperparameter tuning with Lightning is desired, the HyperLight class from spotpython, see HyperLight. |
There is no default, a simple example is fun = Analytical().fun_sphere |
design |
Can be any design generating function from spotpython.design:*, e.g., Clustered, Factorial, Grid, Poor, Random, Sobol, or SpaceFilling. |
design = SpaceFilling(k=15) |
optimizer |
Can be any of dual_annealing, direct, shgo, basinhopping, or differential_evolution, see, e.g., differential_evolution. |
optimizer=differential_evolution |
surrogate |
Can be any sklearn regressor, e.g., GaussianProcessRegressor or, the Kriging class from spotpython. |
surrogate=Kriging() |
| Dictionary | Code Reference | Example |
|---|---|---|
fun_control |
fun_control_init | The lower and upper arguments are mandatory, e.g., fun_control=fun_control_init(lower=np.array([-1, -1]),upper=np.array([1, 1])). |
design_control |
design_control_init() | design_control=design_control_init() |
optimizer_control |
optimizer_control_init | optimizer_control_init() |
surrogate_control |
surrogate_control_init | surrogate_control=surrogate_control_init() |
Based on the definition of the fun, design, optimizer, and surrogate objects, and their corresponding control parameter dictionaries, fun_control, design_control, optimizer_control, and surrogate_control, the Spot object can be build as follows:
fun_control=fun_control_init(lower=np.array([-1, -1]),
upper=np.array([1, 1]))
design_control=design_control_init()
optimizer_control=optimizer_control_init()
surrogate_control=surrogate_control_init()
spot_tuner = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control,
optimizer_control=optimizer_control,
surrogate_control=surrogate_control)12.9 Run
spot_tuner.run()spotpython tuning: 6.611333241687761e-06 [#######---] 73.33%. Success rate: 100.00%
spotpython tuning: 6.611333241687761e-06 [########--] 80.00%. Success rate: 50.00%
spotpython tuning: 6.611333241687761e-06 [#########-] 86.67%. Success rate: 33.33%
spotpython tuning: 6.611333241687761e-06 [#########-] 93.33%. Success rate: 25.00%
spotpython tuning: 3.1531067682958562e-06 [##########] 100.00%. Success rate: 40.00% Done...
Experiment saved to 000_res.pkl<spotpython.spot.spot.Spot at 0x12cd50690>12.10 Print the Results
spot_tuner.print_results()min y: 3.1531067682958562e-06
x0: -0.0012459503825024937
x1: -0.0012651934289418935[['x0', np.float64(-0.0012459503825024937)],
['x1', np.float64(-0.0012651934289418935)]]12.11 Show the Progress
spot_tuner.plot_progress()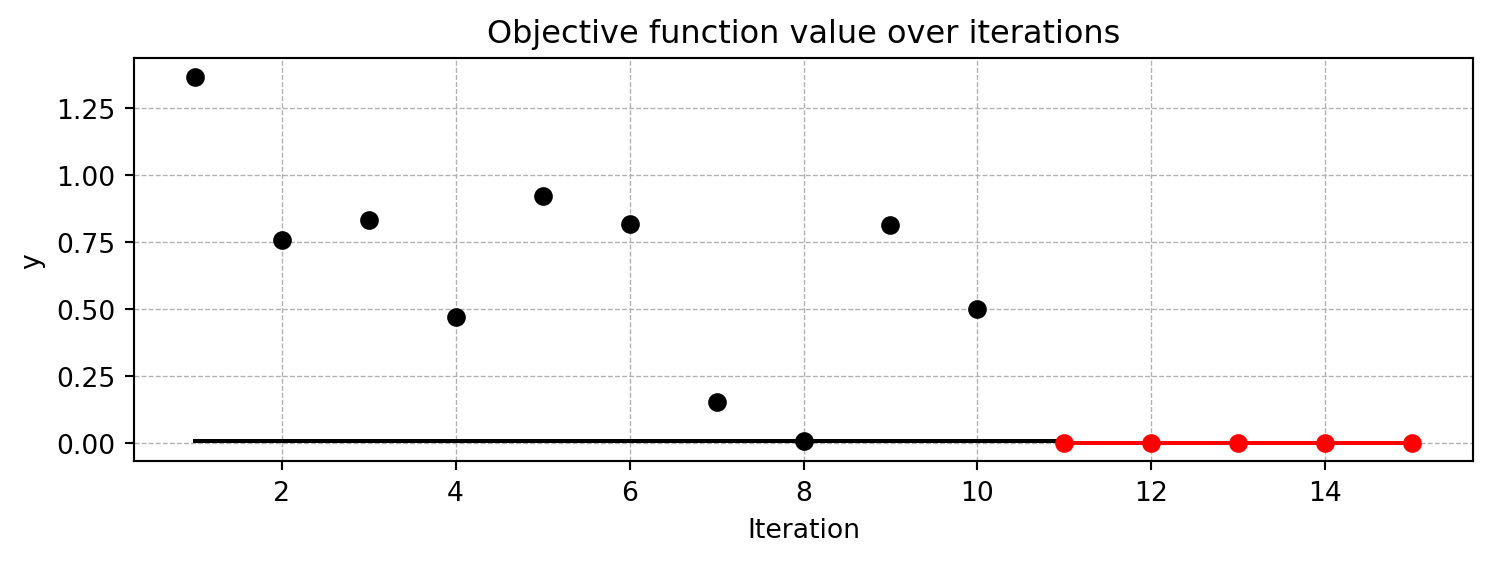
12.12 Visualize the Surrogate
- The plot method of the
krigingsurrogate is used. - Note: the plot uses the interval defined by the ranges of the natural variables.
spot_tuner.surrogate.plot()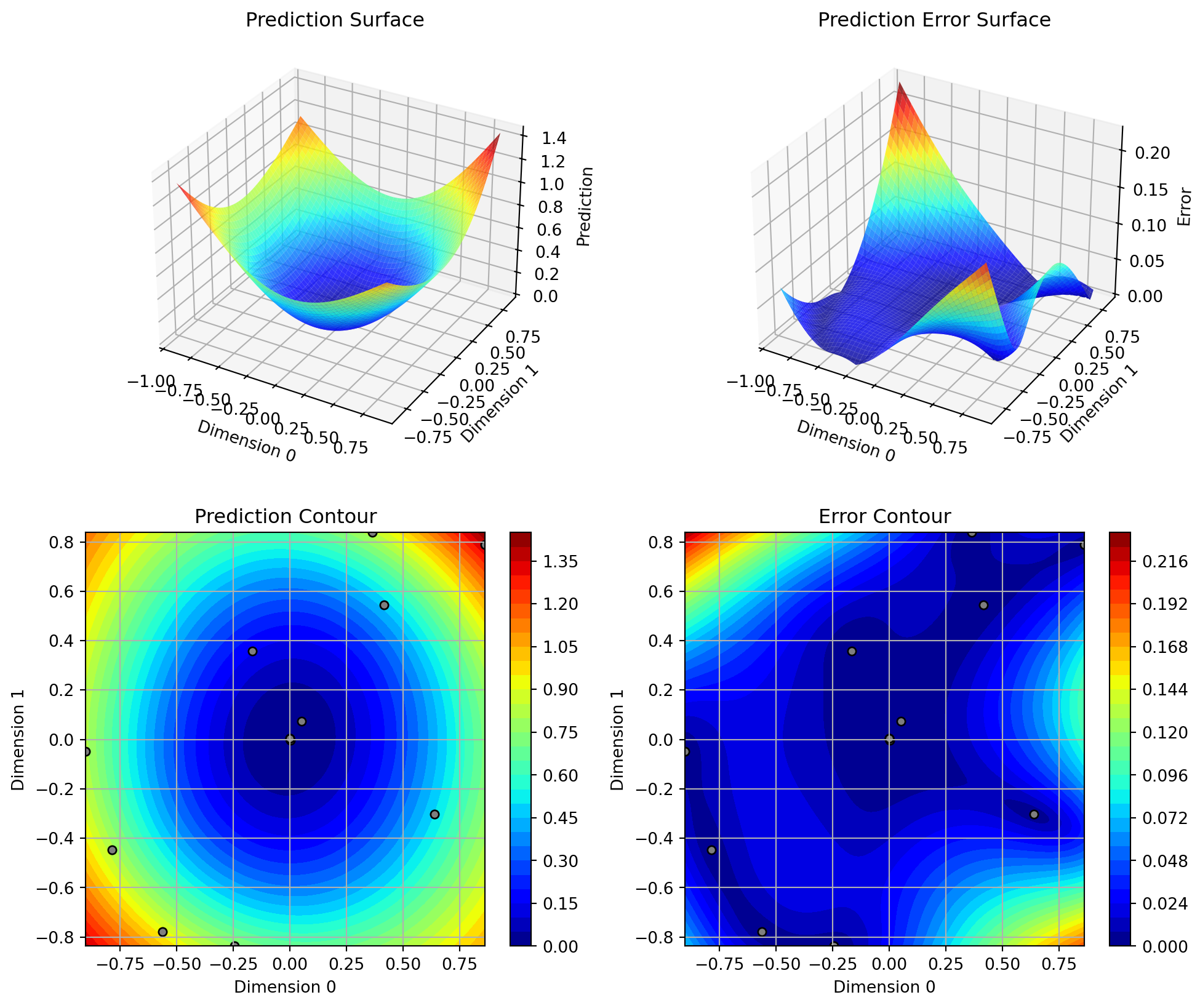
12.13 Init: Build Initial Design
from spotpython.design.spacefilling import SpaceFilling
from spotpython.surrogate.kriging import Kriging
from spotpython.fun.objectivefunctions import Analytical
from spotpython.utils.init import fun_control_init
gen = SpaceFilling(2)
rng = np.random.RandomState(1)
lower = np.array([-5,-0])
upper = np.array([10,15])
fun = Analytical().fun_branin
fun_control = fun_control_init(sigma=0)
X = gen.scipy_lhd(10, lower=lower, upper = upper)
print(X)
y = fun(X, fun_control=fun_control)
print(y)[[ 8.97647221 13.41926847]
[ 0.66946019 1.22344228]
[ 5.23614115 13.78185824]
[ 5.6149825 11.5851384 ]
[-1.72963184 1.66516096]
[-4.26945568 7.1325531 ]
[ 1.26363761 10.17935555]
[ 2.88779942 8.05508969]
[-3.39111089 4.15213772]
[ 7.30131231 5.22275244]]
[128.95676449 31.73474356 172.89678121 126.71295908 64.34349975
70.16178611 48.71407916 31.77322887 76.91788181 30.69410529]12.14 Replicability
Seed
gen = SpaceFilling(2, seed=123)
X0 = gen.scipy_lhd(3)
gen = SpaceFilling(2, seed=345)
X1 = gen.scipy_lhd(3)
X2 = gen.scipy_lhd(3)
gen = SpaceFilling(2, seed=123)
X3 = gen.scipy_lhd(3)
X0, X1, X2, X3(array([[0.77254938, 0.31539299],
[0.59321338, 0.93854273],
[0.27469803, 0.3959685 ]]),
array([[0.78373509, 0.86811887],
[0.06692621, 0.6058029 ],
[0.41374778, 0.00525456]]),
array([[0.121357 , 0.69043832],
[0.41906219, 0.32838498],
[0.86742658, 0.52910374]]),
array([[0.77254938, 0.31539299],
[0.59321338, 0.93854273],
[0.27469803, 0.3959685 ]]))12.15 Surrogates
12.15.1 A Simple Predictor
The code below shows how to use a simple model for prediction. Assume that only two (very costly) measurements are available:
- f(0) = 0.5
- f(2) = 2.5
We are interested in the value at \(x_0 = 1\), i.e., \(f(x_0 = 1)\), but cannot run an additional, third experiment.
from sklearn import linear_model
X = np.array([[0], [2]])
y = np.array([0.5, 2.5])
S_lm = linear_model.LinearRegression()
S_lm = S_lm.fit(X, y)
X0 = np.array([[1]])
y0 = S_lm.predict(X0)
print(y0)[1.5]Central Idea: Evaluation of the surrogate model S_lm is much cheaper (or / and much faster) than running the real-world experiment \(f\).
12.16 Tensorboard Setup
12.16.1 Tensorboard Configuration
The TENSORBOARD_CLEAN argument can be set to True in the fun_control dictionary to archive the TensorBoard folder if it already exists. This is useful if you want to start a hyperparameter tuning process from scratch. If you want to continue a hyperparameter tuning process, set TENSORBOARD_CLEAN to False. Then the TensorBoard folder will not be archived and the old and new TensorBoard files will shown in the TensorBoard dashboard.
12.16.2 Starting TensorBoard
TensorBoard can be started as a background process with the following command, where ./runs is the default directory for the TensorBoard log files:
tensorboard --logdir="./runs"
NoteTENSORBOARD_PATH
The TensorBoard path can be printed with the following command (after a fun_control object has been created):
from spotpython.utils.init import get_tensorboard_path
get_tensorboard_path(fun_control)12.17 Demo/Test: Objective Function Fails
SPOT expects np.nan values from failed objective function values. These are handled. Note: SPOT’s counter considers only successful executions of the objective function.
import numpy as np
from spotpython.fun.objectivefunctions import Analytical
from spotpython.spot import Spot
import numpy as np
from math import inf
# number of initial points:
ni = 20
# number of points
n = 30
fun = Analytical().fun_random_error
fun_control=fun_control_init(
lower = np.array([-1]),
upper= np.array([1]),
fun_evals = n,
show_progress=False)
design_control=design_control_init(init_size=ni)
spot_1 = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control)
# assert value error from the run method
try:
spot_1.run()
except ValueError as e:
print(e)Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Using spacefilling design as fallback.
Experiment saved to 000_res.pkl12.18 Handling Results: Printing, Saving, and Loading
The results can be printed with the following command:
spot_tuner.print_results(print_screen=False)The tuned hyperparameters can be obtained as a dictionary with the following command:
from spotpython.hyperparameters.values import get_tuned_hyperparameters
get_tuned_hyperparameters(spot_tuner, fun_control)The results can be saved and reloaded with the following commands:
from spotpython.utils.file import save_pickle, load_pickle
from spotpython.utils.init import get_experiment_name
experiment_name = get_experiment_name("024")
SAVE_AND_LOAD = False
if SAVE_AND_LOAD == True:
save_pickle(spot_tuner, experiment_name)
spot_tuner = load_pickle(experiment_name)12.19 spotpython as a Hyperparameter Tuner
12.19.1 Modifying Hyperparameter Levels
spotpython distinguishes between different types of hyperparameters. The following types are supported:
int(integer)float(floating point number)boolean(boolean)factor(categorical)
12.19.1.1 Integer Hyperparameters
Integer hyperparameters can be modified with the set_int_hyperparameter_values() [SOURCE] function. The following code snippet shows how to modify the n_estimators hyperparameter of a random forest model:
from spotriver.hyperdict.river_hyper_dict import RiverHyperDict
from spotpython.utils.init import fun_control_init
from spotpython.hyperparameters.values import set_int_hyperparameter_values
from spotpython.utils.eda import print_exp_table
fun_control = fun_control_init(
core_model_name="forest.AMFRegressor",
hyperdict=RiverHyperDict,
)
print("Before modification:")
print_exp_table(fun_control)
set_int_hyperparameter_values(fun_control, "n_estimators", 2, 5)
print("After modification:")
print_exp_table(fun_control)Before modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.1 | 10 | None |
| use_aggregation | factor | 1 | 0 | 1 | None |
Setting hyperparameter n_estimators to value [2, 5].
Variable type is int.
Core type is None.
Calling modify_hyper_parameter_bounds().
After modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.1 | 10 | None |
| use_aggregation | factor | 1 | 0 | 1 | None |12.19.1.2 Float Hyperparameters
Float hyperparameters can be modified with the set_float_hyperparameter_values() [SOURCE] function. The following code snippet shows how to modify the step hyperparameter of a hyperparameter of a Mondrian Regression Tree model:
from spotriver.hyperdict.river_hyper_dict import RiverHyperDict
from spotpython.utils.init import fun_control_init
from spotpython.hyperparameters.values import set_float_hyperparameter_values
from spotpython.utils.eda import print_exp_table
fun_control = fun_control_init(
core_model_name="forest.AMFRegressor",
hyperdict=RiverHyperDict,
)
print("Before modification:")
print_exp_table(fun_control)
set_float_hyperparameter_values(fun_control, "step", 0.2, 5)
print("After modification:")
print_exp_table(fun_control)Before modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.1 | 10 | None |
| use_aggregation | factor | 1 | 0 | 1 | None |
Setting hyperparameter step to value [0.2, 5].
Variable type is float.
Core type is None.
Calling modify_hyper_parameter_bounds().
After modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.2 | 5 | None |
| use_aggregation | factor | 1 | 0 | 1 | None |12.19.1.3 Boolean Hyperparameters
Boolean hyperparameters can be modified with the set_boolean_hyperparameter_values() [SOURCE] function. The following code snippet shows how to modify the use_aggregation hyperparameter of a Mondrian Regression Tree model:
from spotriver.hyperdict.river_hyper_dict import RiverHyperDict
from spotpython.utils.init import fun_control_init
from spotpython.hyperparameters.values import set_boolean_hyperparameter_values
from spotpython.utils.eda import print_exp_table
fun_control = fun_control_init(
core_model_name="forest.AMFRegressor",
hyperdict=RiverHyperDict,
)
print("Before modification:")
print_exp_table(fun_control)
set_boolean_hyperparameter_values(fun_control, "use_aggregation", 0, 0)
print("After modification:")
print_exp_table(fun_control)Before modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.1 | 10 | None |
| use_aggregation | factor | 1 | 0 | 1 | None |
Setting hyperparameter use_aggregation to value [0, 0].
Variable type is factor.
Core type is bool.
Calling modify_boolean_hyper_parameter_levels().
After modification:
| name | type | default | lower | upper | transform |
|-----------------|--------|-----------|---------|---------|-----------------------|
| n_estimators | int | 3 | 2 | 5 | transform_power_2_int |
| step | float | 1 | 0.1 | 10 | None |
| use_aggregation | factor | 1 | 0 | 0 | None |12.19.1.4 Factor Hyperparameters
Factor hyperparameters can be modified with the set_factor_hyperparameter_values() [SOURCE] function. The following code snippet shows how to modify the leaf_model hyperparameter of a Hoeffding Tree Regressor model:
from spotriver.hyperdict.river_hyper_dict import RiverHyperDict
from spotpython.utils.init import fun_control_init
from spotpython.hyperparameters.values import set_factor_hyperparameter_values
from spotpython.utils.eda import print_exp_table
fun_control = fun_control_init(
core_model_name="tree.HoeffdingTreeRegressor",
hyperdict=RiverHyperDict,
)
print("Before modification:")
print_exp_table(fun_control)
set_factor_hyperparameter_values(fun_control, "leaf_model", ['LinearRegression',
'Perceptron'])
print("After modification:")Before modification:
| name | type | default | lower | upper | transform |
|------------------------|--------|------------------|---------|----------|------------------------|
| grace_period | int | 200 | 10 | 1000 | None |
| max_depth | int | 20 | 2 | 20 | transform_power_2_int |
| delta | float | 1e-07 | 1e-08 | 1e-06 | None |
| tau | float | 0.05 | 0.01 | 0.1 | None |
| leaf_prediction | factor | mean | 0 | 2 | None |
| leaf_model | factor | LinearRegression | 0 | 2 | None |
| model_selector_decay | float | 0.95 | 0.9 | 0.99 | None |
| splitter | factor | EBSTSplitter | 0 | 2 | None |
| min_samples_split | int | 5 | 2 | 10 | None |
| binary_split | factor | 0 | 0 | 1 | None |
| max_size | float | 500.0 | 100 | 1000 | None |
| memory_estimate_period | int | 6 | 3 | 8 | transform_power_10_int |
| stop_mem_management | factor | 0 | 0 | 1 | None |
| remove_poor_attrs | factor | 0 | 0 | 1 | None |
| merit_preprune | factor | 1 | 0 | 1 | None |
After modification:12.20 Sampling in spotpython
spotpython uses a class for generating space-filling designs using Latin Hypercube Sampling (LHS) and maximin distance criteria. It is based on scipy’s LatinHypercube class. The following example demonstrates how to generate a Latin Hypercube Sampling design using spotpython. The result is shown in Figure 12.5. As can seen in the figure, a Latin hypercube sample generates \(n\) points in \([0,1)^{d}\). Each univariate marginal distribution is stratified, placing exactly one point in \([j/n, (j+1)/n)\) for \(j=0,1,...,n-1\).
import matplotlib.pyplot as plt
import numpy as np
from spotpython.design.spacefilling import SpaceFilling
lhd = SpaceFilling(k=2, seed=123)
X = lhd.scipy_lhd(n=10, repeats=1, lower=np.array([0, 0]), upper=np.array([10, 10]))
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('x1')
plt.ylabel('x2')
plt.grid()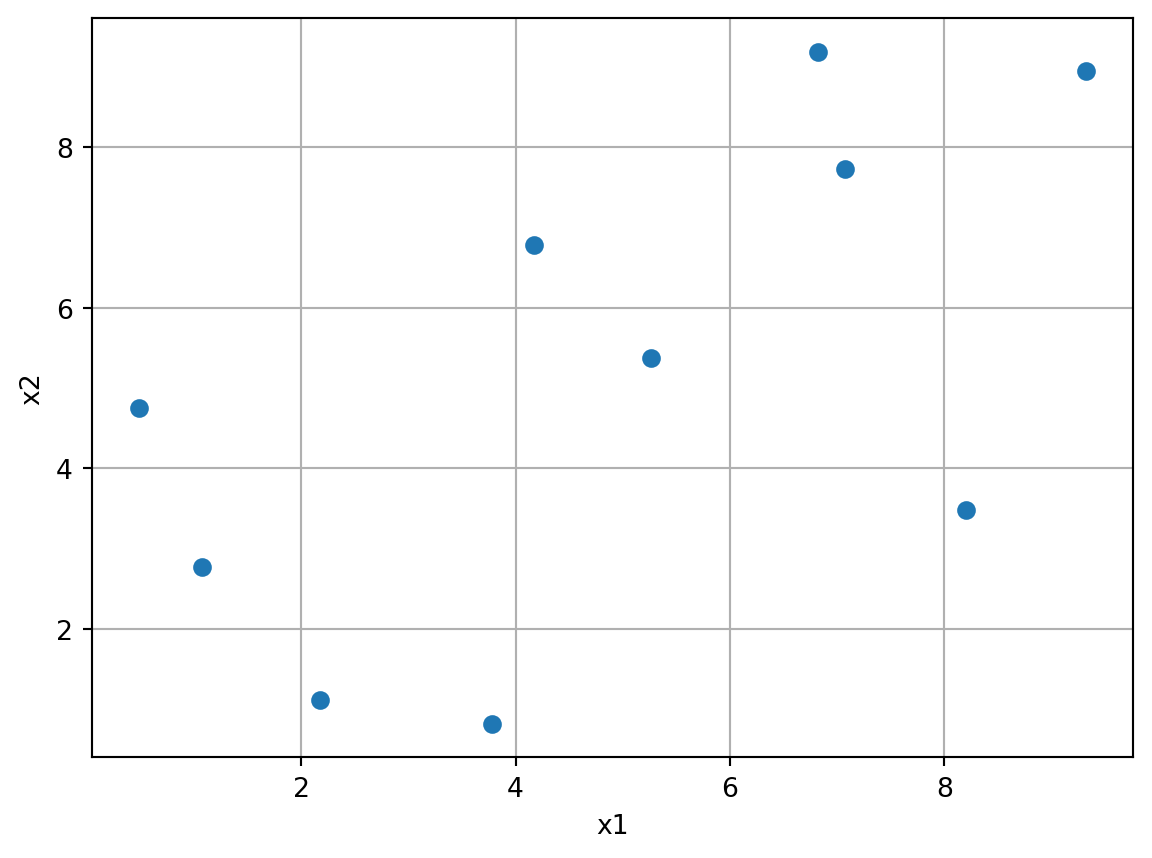
12.21 Example: Spot and the Sphere Function
Central Idea: Evaluation of the surrogate model S is much cheaper (or / and much faster) than running the real-world experiment \(f\). We start with a small example.
import numpy as np
from math import inf
from spotpython.fun.objectivefunctions import Analytical
from spotpython.utils.init import fun_control_init, design_control_init
from spotpython.hyperparameters.values import set_control_key_value
from spotpython.spot import Spot
import matplotlib.pyplot as plt12.21.1 The Objective Function: Sphere
The spotpython package provides several classes of objective functions. We will use an analytical objective function, i.e., a function that can be described by a (closed) formula: \[
f(x) = x^2
\]
fun = Analytical().fun_sphereWe can apply the function fun to input values and plot the result:
x = np.linspace(-1,1,100).reshape(-1,1)
y = fun(x)
plt.figure()
plt.plot(x, y, "k")
plt.show()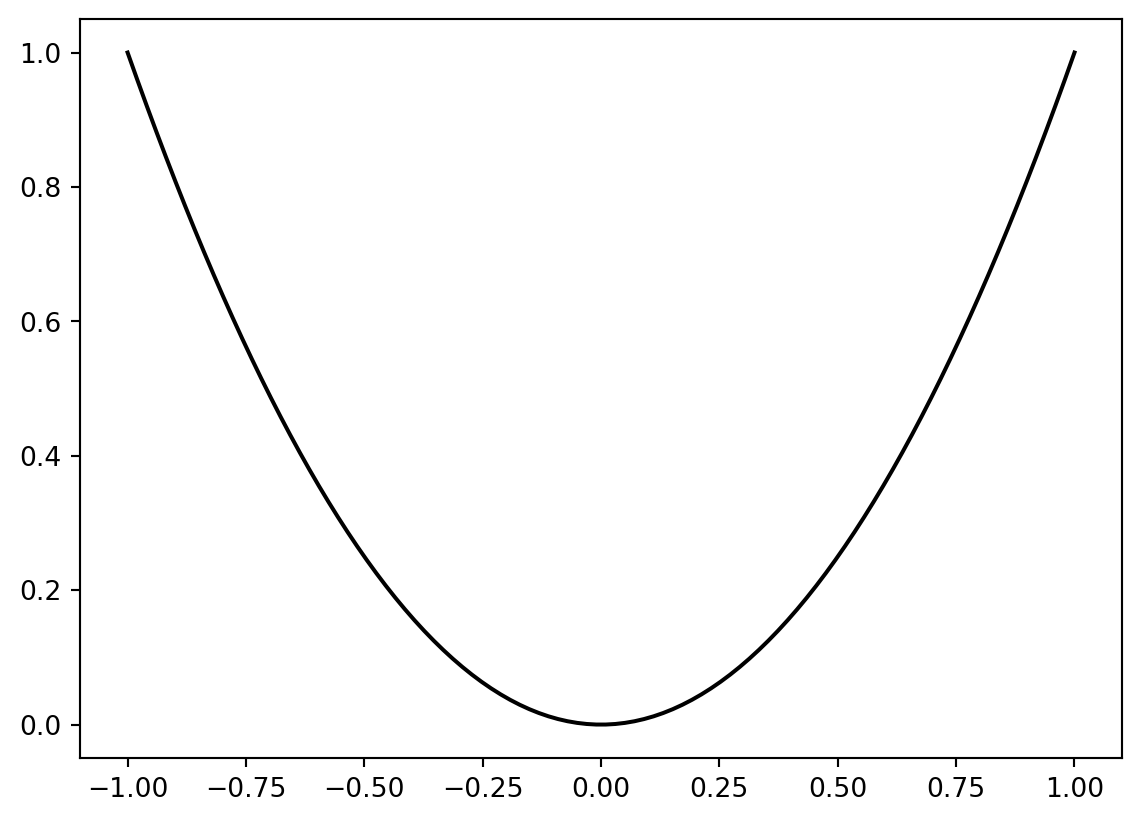
12.21.2 The Spot Method as an Optimization Algorithm Using a Surrogate Model
We initialize the fun_control dictionary. The fun_control dictionary contains the parameters for the objective function. The fun_control dictionary is passed to the Spot method.
fun_control=fun_control_init(lower = np.array([-1]),
upper = np.array([1]))
spot_0 = Spot(fun=fun,
fun_control=fun_control)
spot_0.run()spotpython tuning: 2.4412172266370036e-09 [#######---] 73.33%. Success rate: 100.00%
spotpython tuning: 2.032431480352692e-09 [########--] 80.00%. Success rate: 100.00%
spotpython tuning: 2.032431480352692e-09 [#########-] 86.67%. Success rate: 66.67%
spotpython tuning: 2.032431480352692e-09 [#########-] 93.33%. Success rate: 50.00%
spotpython tuning: 1.2228307315407816e-10 [##########] 100.00%. Success rate: 60.00% Done...
Experiment saved to 000_res.pkl<spotpython.spot.spot.Spot at 0x373daa5d0>The method print_results() prints the results, i.e., the best objective function value (“min y”) and the corresponding input value (“x0”).
spot_0.print_results()min y: 1.2228307315407816e-10
x0: 1.1058167712332733e-05[['x0', np.float64(1.1058167712332733e-05)]]To plot the search progress, the method plot_progress() can be used. The parameter log_y is used to plot the objective function values on a logarithmic scale.
spot_0.plot_progress(log_y=True)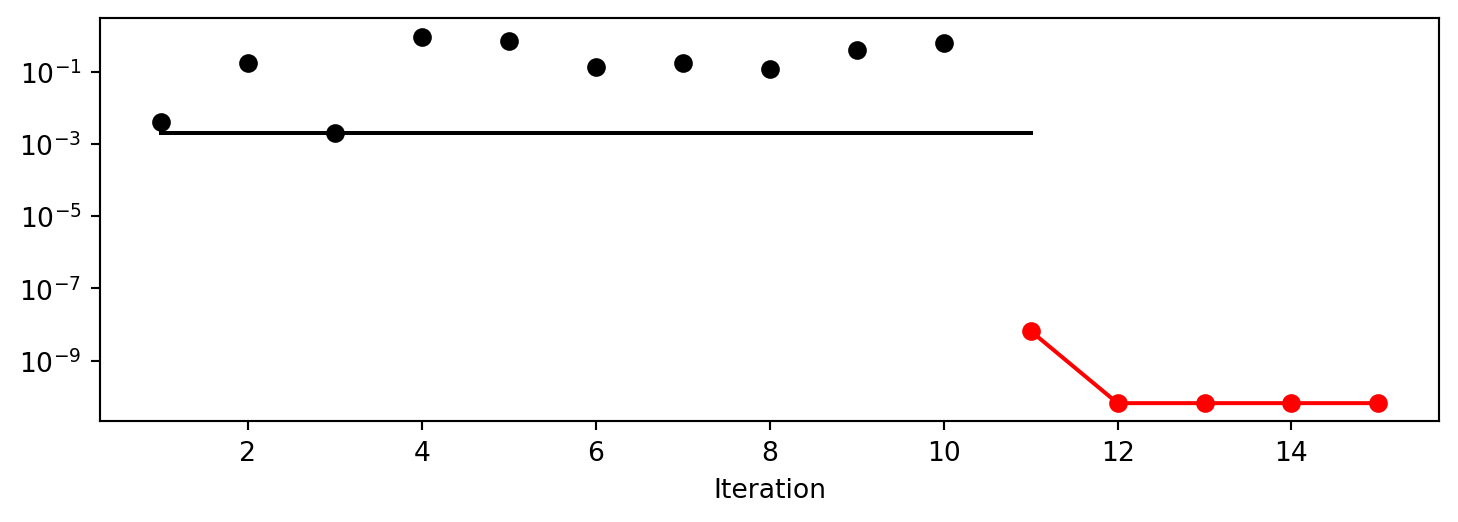
Spot method. The black elements (points and line) represent the initial design, before the surrogate is build. The red elements represent the search on the surrogate.
If the dimension of the input space is one, the method plot_model() can be used to visualize the model and the underlying objective function values.
spot_0.plot_model()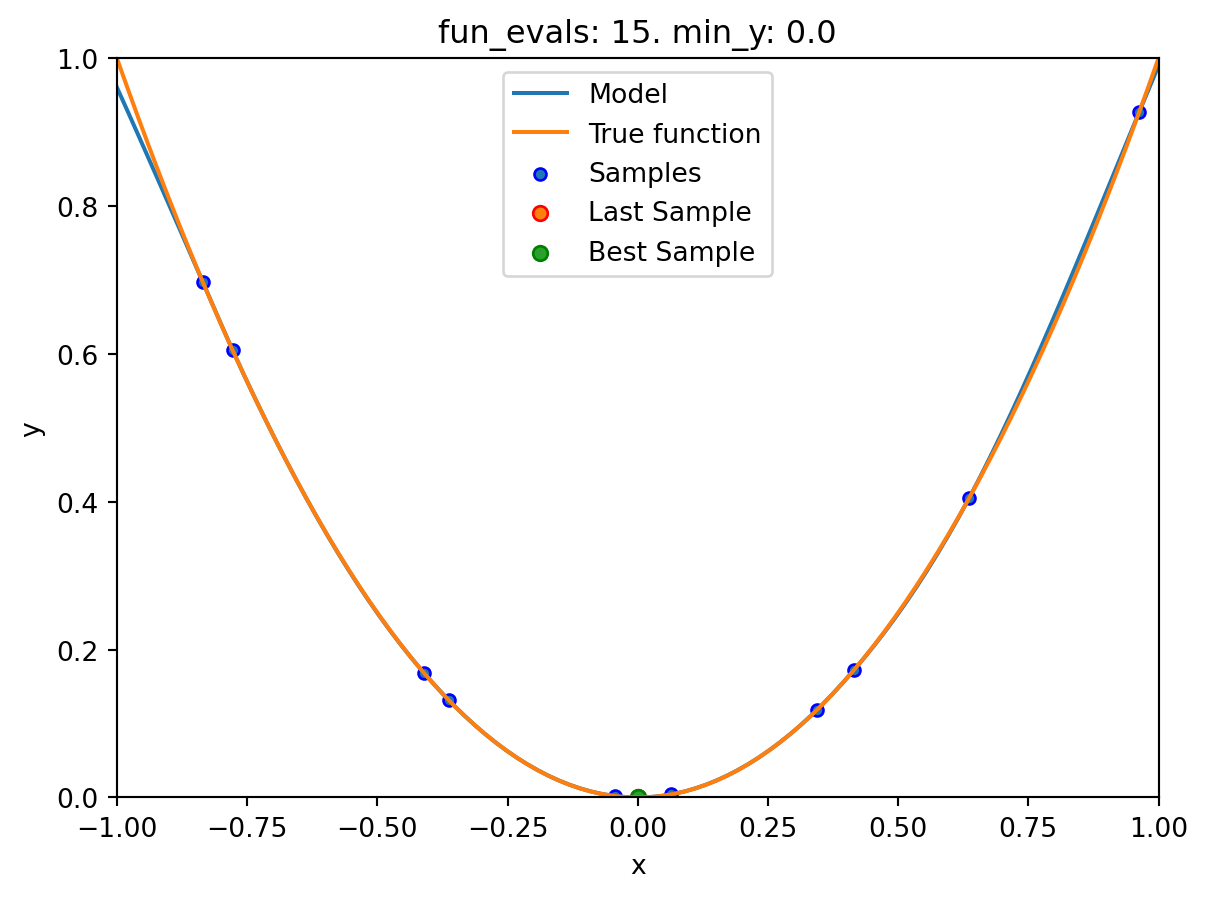
12.22 Spot Parameters: fun_evals, init_size and show_models
We will modify three parameters:
- The number of function evaluations (
fun_evals) will be set to10(instead of 15, which is the default value) in thefun_controldictionary. - The parameter
show_models, which visualizes the search process for each single iteration for 1-dim functions, in thefun_controldictionary. - The size of the initial design (
init_size) in thedesign_controldictionary.
The full list of the Spot parameters is shown in code reference on GitHub, see Spot.
fun_control=fun_control_init(lower = np.array([-1]),
upper = np.array([1]),
fun_evals = 10,
show_models = True)
design_control = design_control_init(init_size=9)
spot_1 = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control)
spot_1.run()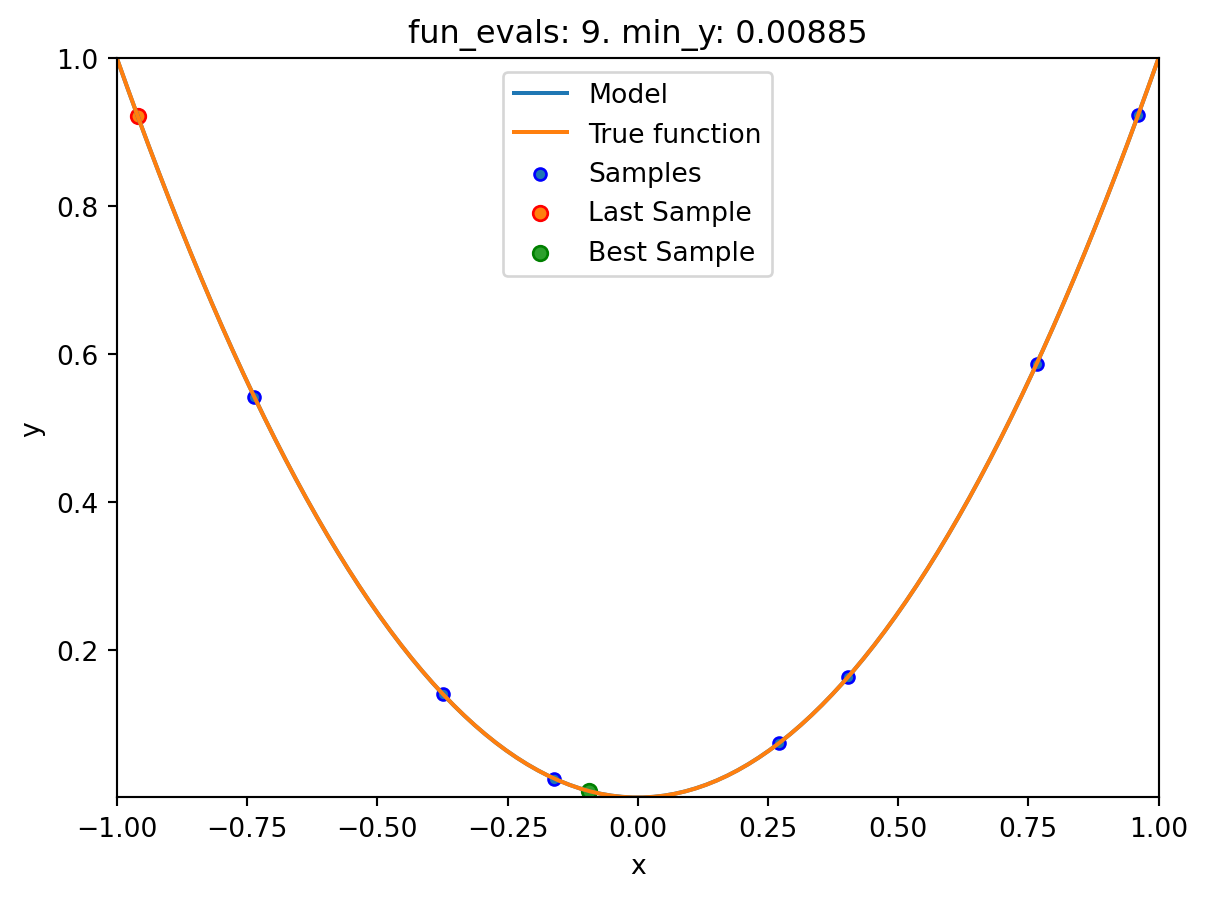
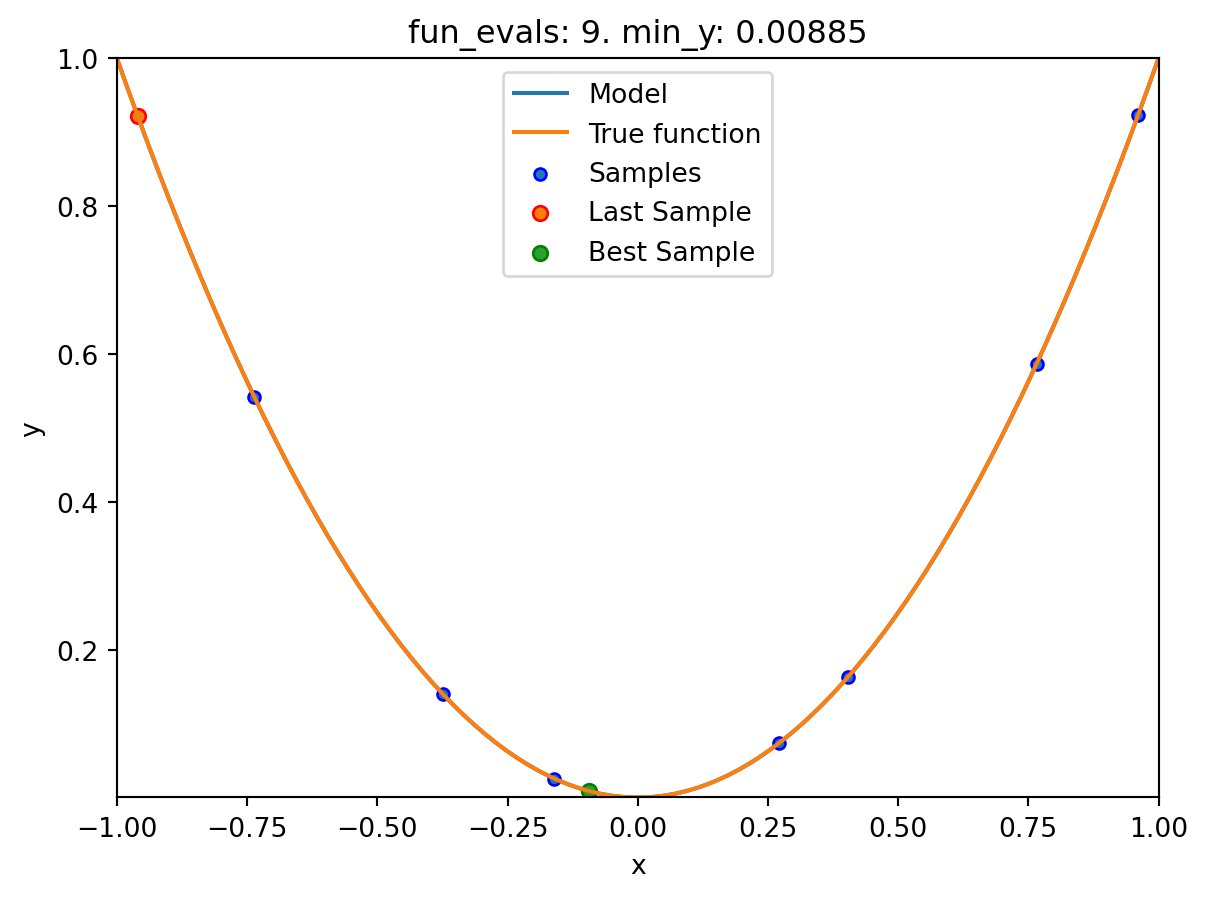
spotpython tuning: 3.7772791809054267e-10 [##########] 100.00%. Success rate: 100.00% Done...
Experiment saved to 000_res.pkl12.23 Print the Results
spot_1.print_results()min y: 3.7772791809054267e-10
x0: -1.9435223643954877e-05[['x0', np.float64(-1.9435223643954877e-05)]]12.24 Show the Progress
spot_1.plot_progress()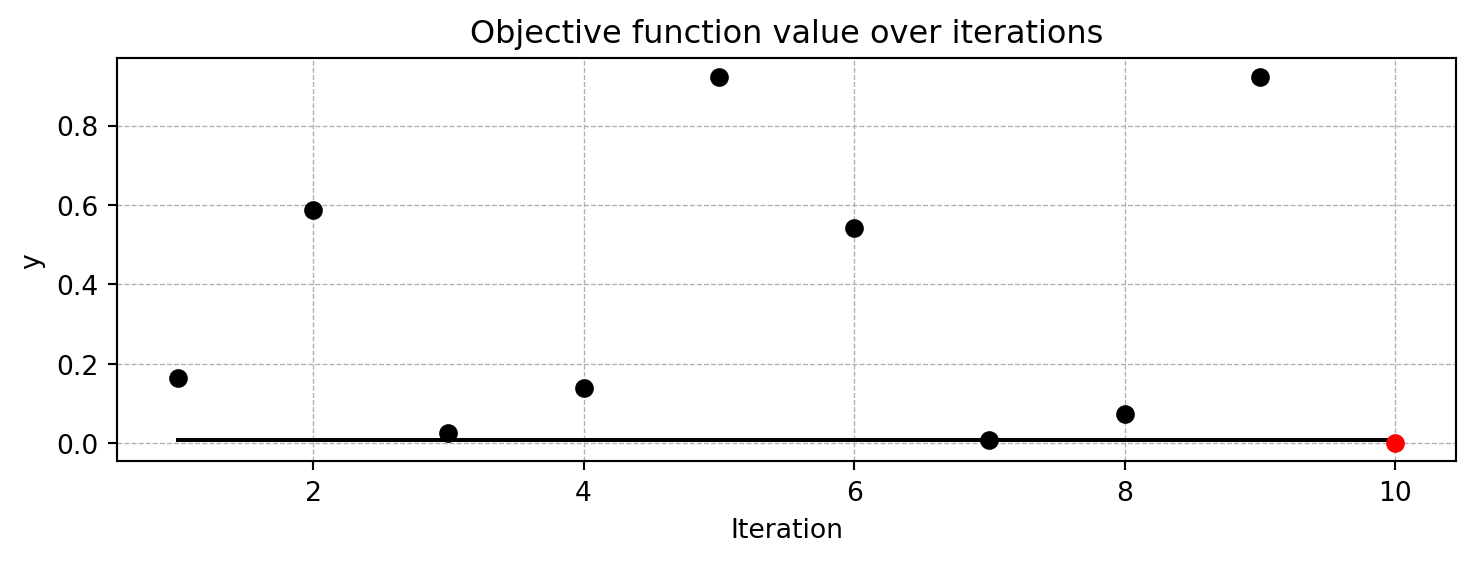
12.25 Visualizing the Optimization and Hyperparameter Tuning Process with TensorBoard
spotpython supports the visualization of the hyperparameter tuning process with TensorBoard. The following example shows how to use TensorBoard with spotpython.
First, we define an “PREFIX” to identify the hyperparameter tuning process. The PREFIX is used to create a directory for the TensorBoard files.
fun_control = fun_control_init(
PREFIX = "01",
lower = np.array([-1]),
upper = np.array([2]),
fun_evals=100,
TENSORBOARD_CLEAN=True,
tensorboard_log=True)
design_control = design_control_init(init_size=5)Moving TENSORBOARD_PATH: runs/ to TENSORBOARD_PATH_OLD: runs_OLD/runs_2025_11_06_17_15_07_0
Created spot_tensorboard_path: runs/spot_logs/01_maans08_2025-11-06_17-15-07 for SummaryWriter()Since the tensorboard_log is True, spotpython will log the optimization process in the TensorBoard files. The argument TENSORBOARD_CLEAN=True will move the TensorBoard files from the previous run to a backup folder, so that TensorBoard files from previous runs are not overwritten and a clean start in the runs folder is guaranteed.
spot_tuner = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control)
spot_tuner.run()
spot_tuner.print_results()spotpython tuning: 6.428084284497196e-06 [#---------] 6.00%. Success rate: 100.00%
spotpython tuning: 1.0018985789303623e-07 [#---------] 7.00%. Success rate: 100.00%
spotpython tuning: 7.156564048814216e-08 [#---------] 8.00%. Success rate: 100.00%
spotpython tuning: 7.4015092835768465e-09 [#---------] 9.00%. Success rate: 100.00%
spotpython tuning: 7.4015092835768465e-09 [#---------] 10.00%. Success rate: 80.00%
spotpython tuning: 7.4015092835768465e-09 [#---------] 11.00%. Success rate: 66.67%
spotpython tuning: 7.4015092835768465e-09 [#---------] 12.00%. Success rate: 57.14%
spotpython tuning: 7.4015092835768465e-09 [#---------] 13.00%. Success rate: 50.00%
spotpython tuning: 7.4015092835768465e-09 [#---------] 14.00%. Success rate: 44.44%
spotpython tuning: 7.4015092835768465e-09 [##--------] 15.00%. Success rate: 40.00%
spotpython tuning: 7.4015092835768465e-09 [##--------] 16.00%. Success rate: 36.36%
spotpython tuning: 7.4015092835768465e-09 [##--------] 17.00%. Success rate: 33.33%
spotpython tuning: 7.4015092835768465e-09 [##--------] 18.00%. Success rate: 30.77%
spotpython tuning: 7.4015092835768465e-09 [##--------] 19.00%. Success rate: 28.57%
spotpython tuning: 7.4015092835768465e-09 [##--------] 20.00%. Success rate: 26.67%
spotpython tuning: 7.4015092835768465e-09 [##--------] 21.00%. Success rate: 25.00%
spotpython tuning: 7.4015092835768465e-09 [##--------] 22.00%. Success rate: 23.53%
spotpython tuning: 7.4015092835768465e-09 [##--------] 23.00%. Success rate: 22.22%
spotpython tuning: 7.4015092835768465e-09 [##--------] 24.00%. Success rate: 21.05%
spotpython tuning: 7.4015092835768465e-09 [##--------] 25.00%. Success rate: 20.00%
spotpython tuning: 7.4015092835768465e-09 [###-------] 26.00%. Success rate: 19.05%
spotpython tuning: 7.4015092835768465e-09 [###-------] 27.00%. Success rate: 18.18%
spotpython tuning: 7.4015092835768465e-09 [###-------] 28.00%. Success rate: 17.39%
spotpython tuning: 7.4015092835768465e-09 [###-------] 29.00%. Success rate: 16.67%
spotpython tuning: 7.4015092835768465e-09 [###-------] 30.00%. Success rate: 16.00%
spotpython tuning: 7.4015092835768465e-09 [###-------] 31.00%. Success rate: 15.38%
spotpython tuning: 7.4015092835768465e-09 [###-------] 32.00%. Success rate: 14.81%
spotpython tuning: 7.4015092835768465e-09 [###-------] 33.00%. Success rate: 14.29%
spotpython tuning: 7.4015092835768465e-09 [###-------] 34.00%. Success rate: 13.79%
spotpython tuning: 7.4015092835768465e-09 [####------] 35.00%. Success rate: 13.33%
spotpython tuning: 7.4015092835768465e-09 [####------] 36.00%. Success rate: 12.90%
spotpython tuning: 7.4015092835768465e-09 [####------] 37.00%. Success rate: 12.50%
Using spacefilling design as fallback.
spotpython tuning: 7.4015092835768465e-09 [####------] 38.00%. Success rate: 12.12%
spotpython tuning: 7.4015092835768465e-09 [####------] 39.00%. Success rate: 11.76%
spotpython tuning: 7.4015092835768465e-09 [####------] 40.00%. Success rate: 11.43%
spotpython tuning: 7.4015092835768465e-09 [####------] 41.00%. Success rate: 11.11%
spotpython tuning: 7.4015092835768465e-09 [####------] 42.00%. Success rate: 10.81%
spotpython tuning: 7.4015092835768465e-09 [####------] 43.00%. Success rate: 10.53%
Using spacefilling design as fallback.
spotpython tuning: 7.4015092835768465e-09 [####------] 44.00%. Success rate: 10.26%
spotpython tuning: 7.4015092835768465e-09 [####------] 45.00%. Success rate: 10.00%
spotpython tuning: 4.312084739261867e-09 [#####-----] 46.00%. Success rate: 12.20%
spotpython tuning: 4.312084739261867e-09 [#####-----] 47.00%. Success rate: 11.90%
spotpython tuning: 4.2846000859350335e-09 [#####-----] 48.00%. Success rate: 13.95%
spotpython tuning: 4.254083847765371e-09 [#####-----] 49.00%. Success rate: 15.91%
spotpython tuning: 4.254083847765371e-09 [#####-----] 50.00%. Success rate: 15.56%
Using spacefilling design as fallback.
spotpython tuning: 4.254083847765371e-09 [#####-----] 51.00%. Success rate: 15.22%
spotpython tuning: 9.802119461374754e-10 [#####-----] 52.00%. Success rate: 17.02%
spotpython tuning: 9.802119461374754e-10 [#####-----] 53.00%. Success rate: 16.67%
spotpython tuning: 9.802119461374754e-10 [#####-----] 54.00%. Success rate: 16.33%
spotpython tuning: 9.802119461374754e-10 [######----] 55.00%. Success rate: 16.00%
spotpython tuning: 9.802119461374754e-10 [######----] 56.00%. Success rate: 15.69%
spotpython tuning: 9.802119461374754e-10 [######----] 57.00%. Success rate: 15.38%
spotpython tuning: 9.802119461374754e-10 [######----] 58.00%. Success rate: 15.09%
spotpython tuning: 9.802119461374754e-10 [######----] 59.00%. Success rate: 14.81%
spotpython tuning: 9.421493769530215e-10 [######----] 60.00%. Success rate: 16.36%
spotpython tuning: 9.421493769530215e-10 [######----] 61.00%. Success rate: 16.07%
Using spacefilling design as fallback.
spotpython tuning: 9.421493769530215e-10 [######----] 62.00%. Success rate: 15.79%
spotpython tuning: 9.421493769530215e-10 [######----] 63.00%. Success rate: 15.52%
spotpython tuning: 9.421493769530215e-10 [######----] 64.00%. Success rate: 15.25%
spotpython tuning: 9.421493769530215e-10 [######----] 65.00%. Success rate: 15.00%
spotpython tuning: 9.421493769530215e-10 [#######---] 66.00%. Success rate: 14.75%
spotpython tuning: 9.421493769530215e-10 [#######---] 67.00%. Success rate: 14.52%
spotpython tuning: 9.421493769530215e-10 [#######---] 68.00%. Success rate: 14.29%
spotpython tuning: 9.421493769530215e-10 [#######---] 69.00%. Success rate: 14.06%
Using spacefilling design as fallback.
spotpython tuning: 9.421493769530215e-10 [#######---] 70.00%. Success rate: 13.85%
spotpython tuning: 9.421493769530215e-10 [#######---] 71.00%. Success rate: 13.64%
spotpython tuning: 9.421493769530215e-10 [#######---] 72.00%. Success rate: 13.43%
Using spacefilling design as fallback.
spotpython tuning: 9.421493769530215e-10 [#######---] 73.00%. Success rate: 13.24%
spotpython tuning: 9.421493769530215e-10 [#######---] 74.00%. Success rate: 13.04%
spotpython tuning: 9.421493769530215e-10 [########--] 75.00%. Success rate: 12.86%
spotpython tuning: 9.421493769530215e-10 [########--] 76.00%. Success rate: 12.68%
spotpython tuning: 9.421493769530215e-10 [########--] 77.00%. Success rate: 12.50%
spotpython tuning: 9.421493769530215e-10 [########--] 78.00%. Success rate: 12.33%
Using spacefilling design as fallback.
spotpython tuning: 9.421493769530215e-10 [########--] 79.00%. Success rate: 12.16%
spotpython tuning: 2.670314613623362e-10 [########--] 80.00%. Success rate: 13.33%
spotpython tuning: 1.0264793385366614e-10 [########--] 81.00%. Success rate: 14.47%
spotpython tuning: 1.0264793385366614e-10 [########--] 82.00%. Success rate: 14.29%
spotpython tuning: 1.0264793385366614e-10 [########--] 83.00%. Success rate: 14.10%
spotpython tuning: 1.0264793385366614e-10 [########--] 84.00%. Success rate: 13.92%
spotpython tuning: 1.0264793385366614e-10 [########--] 85.00%. Success rate: 13.75%
spotpython tuning: 1.0264793385366614e-10 [#########-] 86.00%. Success rate: 13.58%
spotpython tuning: 1.0264793385366614e-10 [#########-] 87.00%. Success rate: 13.41%
spotpython tuning: 1.0264793385366614e-10 [#########-] 88.00%. Success rate: 13.25%
spotpython tuning: 1.0264793385366614e-10 [#########-] 89.00%. Success rate: 13.10%
spotpython tuning: 6.105961713788403e-11 [#########-] 90.00%. Success rate: 14.12%
spotpython tuning: 6.105961713788403e-11 [#########-] 91.00%. Success rate: 13.95%
spotpython tuning: 6.105961713788403e-11 [#########-] 92.00%. Success rate: 13.79%
spotpython tuning: 6.105961713788403e-11 [#########-] 93.00%. Success rate: 13.64%
spotpython tuning: 6.105961713788403e-11 [#########-] 94.00%. Success rate: 13.48%
Using spacefilling design as fallback.
spotpython tuning: 6.105961713788403e-11 [##########] 95.00%. Success rate: 13.33%
spotpython tuning: 4.607935942920989e-14 [##########] 96.00%. Success rate: 14.29%
spotpython tuning: 4.607935942920989e-14 [##########] 97.00%. Success rate: 14.13%
spotpython tuning: 4.607935942920989e-14 [##########] 98.00%. Success rate: 13.98%
spotpython tuning: 4.607935942920989e-14 [##########] 99.00%. Success rate: 13.83%
spotpython tuning: 4.607935942920989e-14 [##########] 100.00%. Success rate: 13.68% Done...
Experiment saved to 01_res.pkl
min y: 4.607935942920989e-14
x0: 2.1466103379330375e-07[['x0', np.float64(2.1466103379330375e-07)]]Now we can start TensorBoard in the background. The TensorBoard process will read the TensorBoard files and visualize the hyperparameter tuning process. From the terminal, we can start TensorBoard with the following command:
tensorboard --logdir="./runs"logdir is the directory where the TensorBoard files are stored. In our case, the TensorBoard files are stored in the directory ./runs.
TensorBoard will start a web server on port 6006. We can access the TensorBoard web server with the following URL:
http://localhost:6006/The first TensorBoard visualization shows the objective function values plotted against the wall time. The wall time is the time that has passed since the start of the hyperparameter tuning process. The five initial design points are shown in the upper left region of the plot. The line visualizes the optimization process. 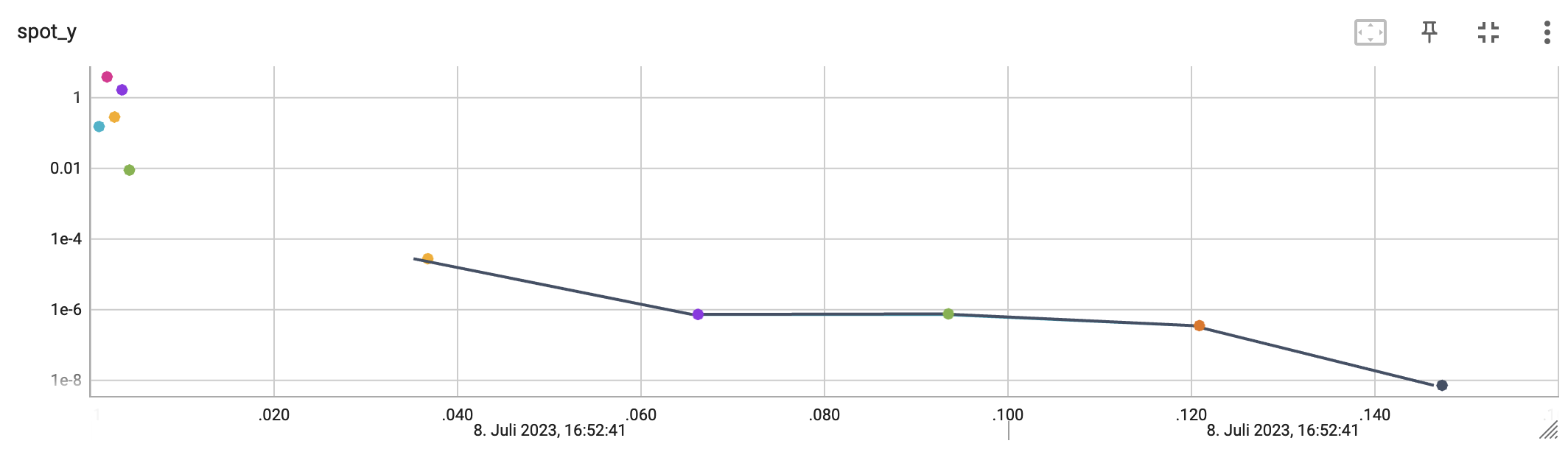
The second TensorBoard visualization shows the input values, i.e., \(x_0\), plotted against the wall time. 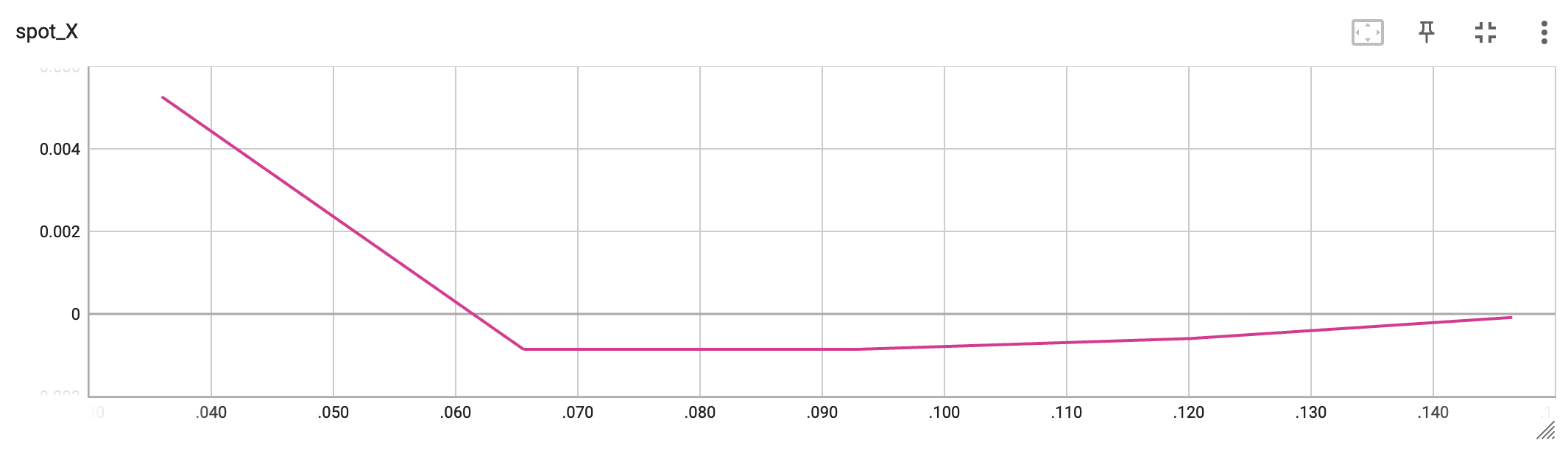
The third TensorBoard plot illustrates how spotpython can be used as a microscope for the internal mechanisms of the surrogate-based optimization process. Here, one important parameter, the learning rate \(\theta\) of the Kriging surrogate is plotted against the number of optimization steps.

12.26 Jupyter Notebook
Note
- The Jupyter-Notebook of this lecture is available on GitHub in the Hyperparameter-Tuning-Cookbook Repository