import os
from math import inf
import numpy as np
import warnings
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import RidgeCV, ElasticNet, LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor, RandomForestClassifier
from sklearn.metrics import mean_absolute_error, accuracy_score, roc_curve, roc_auc_score, log_loss, mean_squared_error
from spotpython.hyperparameters.values import set_control_key_value
from spotpython.plot.validation import plot_confusion_matrix, plot_roc
from spotpython.spot import Spot
from spotpython.hyperparameters.values import (get_one_core_model_from_X, add_core_model_to_fun_control, get_default_hyperparameters_as_array)
from spotpython.hyperdict.sklearn_hyper_dict import SklearnHyperDict
from spotpython.hyperparameters.values import (modify_hyper_parameter_bounds, modify_hyper_parameter_levels, get_default_hyperparameters_as_array)
from spotpython.fun.hypersklearn import HyperSklearn
from spotpython.utils.eda import print_res_table
from spotpython.utils.init import (fun_control_init, design_control_init, surrogate_control_init, get_tensorboard_path, get_experiment_name)
from spotpython.utils.file import load_result
if not os.path.exists('./figures'):
os.makedirs('./figures')
warnings.filterwarnings("ignore")35 HPT: sklearn SVC on Moons Data
This chapter is a tutorial for the Hyperparameter Tuning (HPT) of a sklearn SVC model on the Moons dataset.
35.1 Packages used in this Chapter
35.2 Step 1: Setup
Before we consider the detailed experimental setup, we select the parameters that affect run time, initial design size and the device that is used.
CautionCaution: Run time (and initial design size) should be increased for real experiments
- MAX_TIME is set to one minute for demonstration purposes. For real experiments, this should be increased to at least 1 hour.
MAX_TIME = 1
PREFIX = "401_sklearn_classification"35.3 Step 2: Initialization of the Empty fun_control Dictionary
spotpython supports the visualization of the hyperparameter tuning process with TensorBoard. The following example shows how to use TensorBoard with spotpython. The fun_control dictionary is the central data structure that is used to control the optimization process. It is initialized as follows:
fun_control = fun_control_init(
PREFIX=PREFIX,
TENSORBOARD_CLEAN=True,
max_time=MAX_TIME,
fun_evals=inf,
tolerance_x = np.sqrt(np.spacing(1)))Moving TENSORBOARD_PATH: runs/ to TENSORBOARD_PATH_OLD: runs_OLD/runs_2025_11_06_18_04_20_0
TipTip: TensorBoard
- Since the
spot_tensorboard_pathargument is notNone, which is the default,spotpythonwill log the optimization process in the TensorBoard folder. - The
TENSORBOARD_CLEANargument is set toTrueto archive the TensorBoard folder if it already exists. This is useful if you want to start a hyperparameter tuning process from scratch. If you want to continue a hyperparameter tuning process, setTENSORBOARD_CLEANtoFalse. Then the TensorBoard folder will not be archived and the old and new TensorBoard files will shown in the TensorBoard dashboard.
35.4 Step 3: SKlearn Load Data (Classification)
Randomly generate classification data.
n_features = 2
n_samples = 500
target_column = "y"
ds = make_moons(n_samples, noise=0.5, random_state=0)
X, y = ds
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
train = pd.DataFrame(np.hstack((X_train, y_train.reshape(-1, 1))))
test = pd.DataFrame(np.hstack((X_test, y_test.reshape(-1, 1))))
train.columns = [f"x{i}" for i in range(1, n_features+1)] + [target_column]
test.columns = [f"x{i}" for i in range(1, n_features+1)] + [target_column]
train.head()| x1 | x2 | y | |
|---|---|---|---|
| 0 | 1.960101 | 0.383172 | 0.0 |
| 1 | 2.354420 | -0.536942 | 1.0 |
| 2 | 1.682186 | -0.332108 | 0.0 |
| 3 | 1.856507 | 0.687220 | 1.0 |
| 4 | 1.925524 | 0.427413 | 1.0 |
Figure 35.1 shows the moons data used for the hyperparameter tuning example.
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
cm = plt.cm.RdBu
cm_bright = ListedColormap(["#FF0000", "#0000FF"])
ax = plt.subplot(1, 1, 1)
ax.set_title("Input data")
# Plot the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright, edgecolors="k")
# Plot the testing points
ax.scatter(
X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6, edgecolors="k"
)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_xticks(())
ax.set_yticks(())
plt.tight_layout()
plt.show()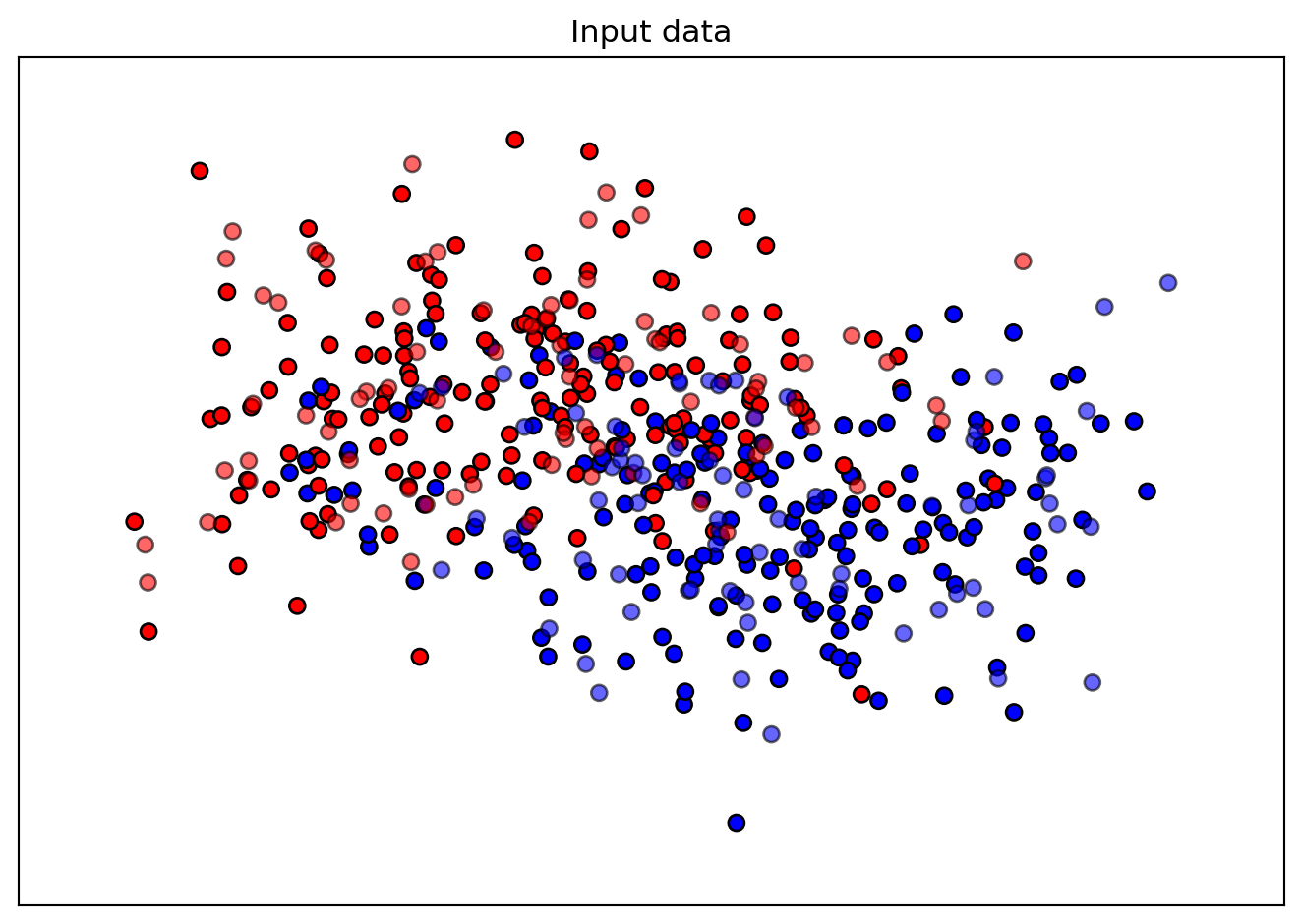
n_samples = len(train)
# add the dataset to the fun_control
fun_control.update({"data": None, # dataset,
"train": train,
"test": test,
"n_samples": n_samples,
"target_column": target_column})35.5 Step 4: Specification of the Preprocessing Model
Data preprocessing can be very simple, e.g., you can ignore it. Then you would choose the prep_model “None”:
prep_model = None
fun_control.update({"prep_model": prep_model})A default approach for numerical data is the StandardScaler (mean 0, variance 1). This can be selected as follows:
prep_model = StandardScaler
fun_control.update({"prep_model": prep_model})Even more complicated pre-processing steps are possible, e.g., the following pipeline:
categorical_columns = []
one_hot_encoder = OneHotEncoder(handle_unknown="ignore", sparse_output=False)
prep_model = ColumnTransformer(
transformers=[
("categorical", one_hot_encoder, categorical_columns),
],
remainder=StandardScaler,
)35.6 Step 5: Select Model (algorithm) and core_model_hyper_dict
The selection of the algorithm (ML model) that should be tuned is done by specifying the its name from the sklearn implementation. For example, the SVC support vector machine classifier is selected as follows:
add_core_model_to_fun_control(core_model=SVC,
fun_control=fun_control,
hyper_dict=SklearnHyperDict,
filename=None)Now fun_control has the information from the JSON file. The corresponding entries for the core_model class are shown below.
fun_control['core_model_hyper_dict']{'C': {'type': 'float',
'default': 1.0,
'transform': 'None',
'lower': 0.1,
'upper': 10.0},
'kernel': {'levels': ['linear', 'poly', 'rbf', 'sigmoid'],
'type': 'factor',
'default': 'rbf',
'transform': 'None',
'core_model_parameter_type': 'str',
'lower': 0,
'upper': 3},
'degree': {'type': 'int',
'default': 3,
'transform': 'None',
'lower': 3,
'upper': 3},
'gamma': {'levels': ['scale', 'auto'],
'type': 'factor',
'default': 'scale',
'transform': 'None',
'core_model_parameter_type': 'str',
'lower': 0,
'upper': 1},
'coef0': {'type': 'float',
'default': 0.0,
'transform': 'None',
'lower': 0.0,
'upper': 0.0},
'shrinking': {'levels': [0, 1],
'type': 'factor',
'default': 0,
'transform': 'None',
'core_model_parameter_type': 'bool',
'lower': 0,
'upper': 1},
'probability': {'levels': [0, 1],
'type': 'factor',
'default': 0,
'transform': 'None',
'core_model_parameter_type': 'bool',
'lower': 0,
'upper': 1},
'tol': {'type': 'float',
'default': 0.001,
'transform': 'None',
'lower': 0.0001,
'upper': 0.01},
'cache_size': {'type': 'float',
'default': 200,
'transform': 'None',
'lower': 100,
'upper': 400},
'break_ties': {'levels': [0, 1],
'type': 'factor',
'default': 0,
'transform': 'None',
'core_model_parameter_type': 'bool',
'lower': 0,
'upper': 1}}
Note
sklearn Model Selection
The following sklearn models are supported by default:
- RidgeCV
- RandomForestClassifier
- SVC
- LogisticRegression
- KNeighborsClassifier
- GradientBoostingClassifier
- GradientBoostingRegressor
- ElasticNet
They can be imported as follows:
from sklearn.linear_model import RidgeCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import ElasticNet35.7 Step 6: Modify hyper_dict Hyperparameters for the Selected Algorithm aka core_model
spotpython provides functions for modifying the hyperparameters, their bounds and factors as well as for activating and de-activating hyperparameters without re-compilation of the Python source code. These functions were described in Section 12.19.1.
35.7.1 Modify hyperparameter of type numeric and integer (boolean)
Numeric and boolean values can be modified using the modify_hyper_parameter_bounds method.
Note
sklearn Model Hyperparameters
The hyperparameters of the sklearn SVC model are described in the sklearn documentation.
- For example, to change the
tolhyperparameter of theSVCmodel to the interval [1e-5, 1e-3], the following code can be used:
modify_hyper_parameter_bounds(fun_control, "tol", bounds=[1e-5, 1e-3])
modify_hyper_parameter_bounds(fun_control, "probability", bounds=[0, 0])
fun_control["core_model_hyper_dict"]["tol"]{'type': 'float',
'default': 0.001,
'transform': 'None',
'lower': 1e-05,
'upper': 0.001}35.7.2 Modify hyperparameter of type factor
Factors can be modified with the modify_hyper_parameter_levels function. For example, to exclude the sigmoid kernel from the tuning, the kernel hyperparameter of the SVC model can be modified as follows:
modify_hyper_parameter_levels(fun_control, "kernel", ["poly", "rbf"])
fun_control["core_model_hyper_dict"]["kernel"]{'levels': ['poly', 'rbf'],
'type': 'factor',
'default': 'rbf',
'transform': 'None',
'core_model_parameter_type': 'str',
'lower': 0,
'upper': 1}35.7.3 Optimizers
Optimizers are described in Section 15.2.
35.8 Step 7: Selection of the Objective (Loss) Function
There are two metrics:
metric_riveris used for the river based evaluation viaeval_oml_iter_progressive.metric_sklearnis used for the sklearn based evaluation.
fun_control.update({
"metric_sklearn": log_loss,
"weights": 1.0,
})
Warning
metric_sklearn: Minimization and Maximization
- Because the
metric_sklearnis used for the sklearn based evaluation, it is important to know whether the metric should be minimized or maximized. - The
weightsparameter is used to indicate whether the metric should be minimized or maximized. - If
weightsis set to-1.0, the metric is maximized. - If
weightsis set to1.0, the metric is minimized, e.g.,weights = 1.0formean_absolute_error, orweights = -1.0forroc_auc_score.
35.8.1 Predict Classes or Class Probabilities
If the key "predict_proba" is set to True, the class probabilities are predicted. False is the default, i.e., the classes are predicted.
fun_control.update({
"predict_proba": False,
})35.9 Step 8: Calling the SPOT Function
35.9.1 The Objective Function
The objective function is selected next. It implements an interface from sklearn’s training, validation, and testing methods to spotpython.
fun = HyperSklearn().fun_sklearnThe following code snippet shows how to get the default hyperparameters as an array, so that they can be passed to the Spot function.
X_start = get_default_hyperparameters_as_array(fun_control)35.9.2 Run the Spot Optimizer
The class Spot [SOURCE] is the hyperparameter tuning workhorse. It is initialized with the following parameters:
fun: the objective functionfun_control: the dictionary with the control parameters for the objective functiondesign: the experimental designdesign_control: the dictionary with the control parameters for the experimental designsurrogate: the surrogate modelsurrogate_control: the dictionary with the control parameters for the surrogate modeloptimizer: the optimizeroptimizer_control: the dictionary with the control parameters for the optimizer
NoteNote: Total run time
The total run time may exceed the specified max_time, because the initial design (here: init_size = INIT_SIZE as specified above) is always evaluated, even if this takes longer than max_time.
design_control = design_control_init()
surrogate_control = surrogate_control_init(method="regression")
spot_tuner = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control,
surrogate_control=surrogate_control)
spot_tuner.run(X_start=X_start)spotpython tuning: 6.436366676628063 [----------] 2.65%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [----------] 4.63%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 6.33%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 7.87%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 9.73%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 11.61%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 13.33%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#---------] 14.93%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 16.62%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 18.26%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 19.76%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 21.36%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 23.23%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##--------] 24.60%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [###-------] 26.59%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [###-------] 28.52%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [###-------] 30.54%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [###-------] 32.39%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [###-------] 34.42%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [####------] 36.59%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [####------] 38.92%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [####------] 41.09%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [####------] 43.11%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#####-----] 45.39%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#####-----] 47.55%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#####-----] 49.31%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#####-----] 51.60%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#####-----] 53.69%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [######----] 55.73%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [######----] 58.02%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [######----] 60.15%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [######----] 62.45%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [######----] 64.84%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#######---] 67.05%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#######---] 69.35%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#######---] 71.51%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#######---] 73.50%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [########--] 75.88%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [########--] 78.33%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [########--] 80.29%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [########--] 82.31%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [########--] 84.35%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#########-] 86.81%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#########-] 88.73%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#########-] 90.69%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#########-] 92.96%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [#########-] 94.98%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##########] 96.96%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##########] 98.86%. Success rate: 0.00%
spotpython tuning: 6.436366676628063 [##########] 100.00%. Success rate: 0.00% Done...
Experiment saved to 401_sklearn_classification_res.pkl<spotpython.spot.spot.Spot at 0x14fca0440>35.9.3 TensorBoard
Now we can start TensorBoard in the background with the following command, where ./runs is the default directory for the TensorBoard log files:
tensorboard --logdir="./runs"
TipTip: TENSORBOARD_PATH
The TensorBoard path can be printed with the following command:
get_tensorboard_path(fun_control)'runs/'We can access the TensorBoard web server with the following URL:
http://localhost:6006/The TensorBoard plot illustrates how spotpython can be used as a microscope for the internal mechanisms of the surrogate-based optimization process. Here, one important parameter, the learning rate \(\theta\) of the Kriging surrogate [SOURCE] is plotted against the number of optimization steps.
35.10 Step 9: Results
After the hyperparameter tuning run is finished, the results can be saved and reloaded with the following commands:
spot_tuner = load_result(PREFIX=PREFIX)Loaded experiment from 401_sklearn_classification_res.pklAfter the hyperparameter tuning run is finished, the progress of the hyperparameter tuning can be visualized. The black points represent the performance values (score or metric) of hyperparameter configurations from the initial design, whereas the red points represents the hyperparameter configurations found by the surrogate model based optimization.
spot_tuner.plot_progress(log_y=True)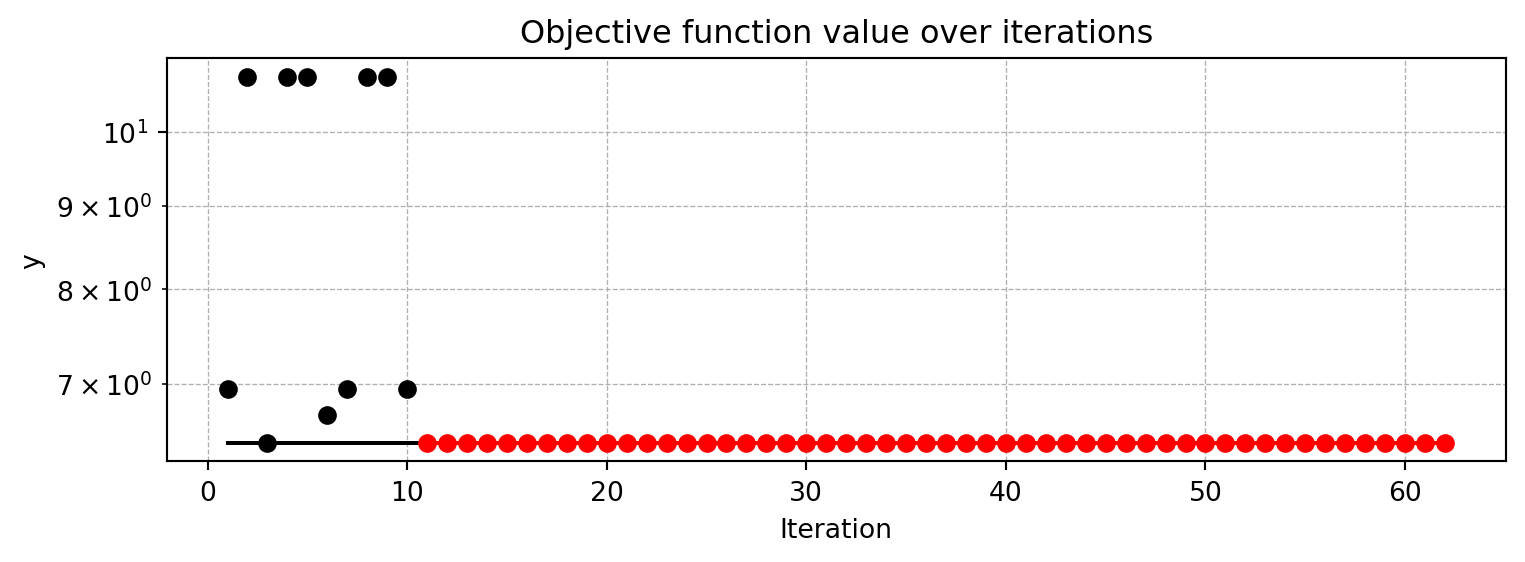
Results can also be printed in tabular form.
print_res_table(spot_tuner)| name | type | default | lower | upper | tuned | transform | importance | stars |
|-------------|--------|-----------|---------|---------|-----------------------|-------------|--------------|---------|
| C | float | 1.0 | 0.1 | 10.0 | 1.3459476182876375 | None | 0.80 | . |
| kernel | factor | rbf | 0.0 | 1.0 | rbf | None | 100.00 | *** |
| degree | int | 3 | 3.0 | 3.0 | 3.0 | None | 0.00 | |
| gamma | factor | scale | 0.0 | 1.0 | scale | None | 0.01 | |
| coef0 | float | 0.0 | 0.0 | 0.0 | 0.0 | None | 0.00 | |
| shrinking | factor | 0 | 0.0 | 1.0 | 1 | None | 0.88 | . |
| probability | factor | 0 | 0.0 | 0.0 | 0 | None | 0.00 | |
| tol | float | 0.001 | 1e-05 | 0.001 | 2.988661226661179e-05 | None | 0.01 | |
| cache_size | float | 200.0 | 100.0 | 400.0 | 174.45504889441855 | None | 0.01 | |
| break_ties | factor | 0 | 0.0 | 1.0 | 0 | None | 0.01 | |A histogram can be used to visualize the most important hyperparameters.
spot_tuner.plot_importance(threshold=0.0025)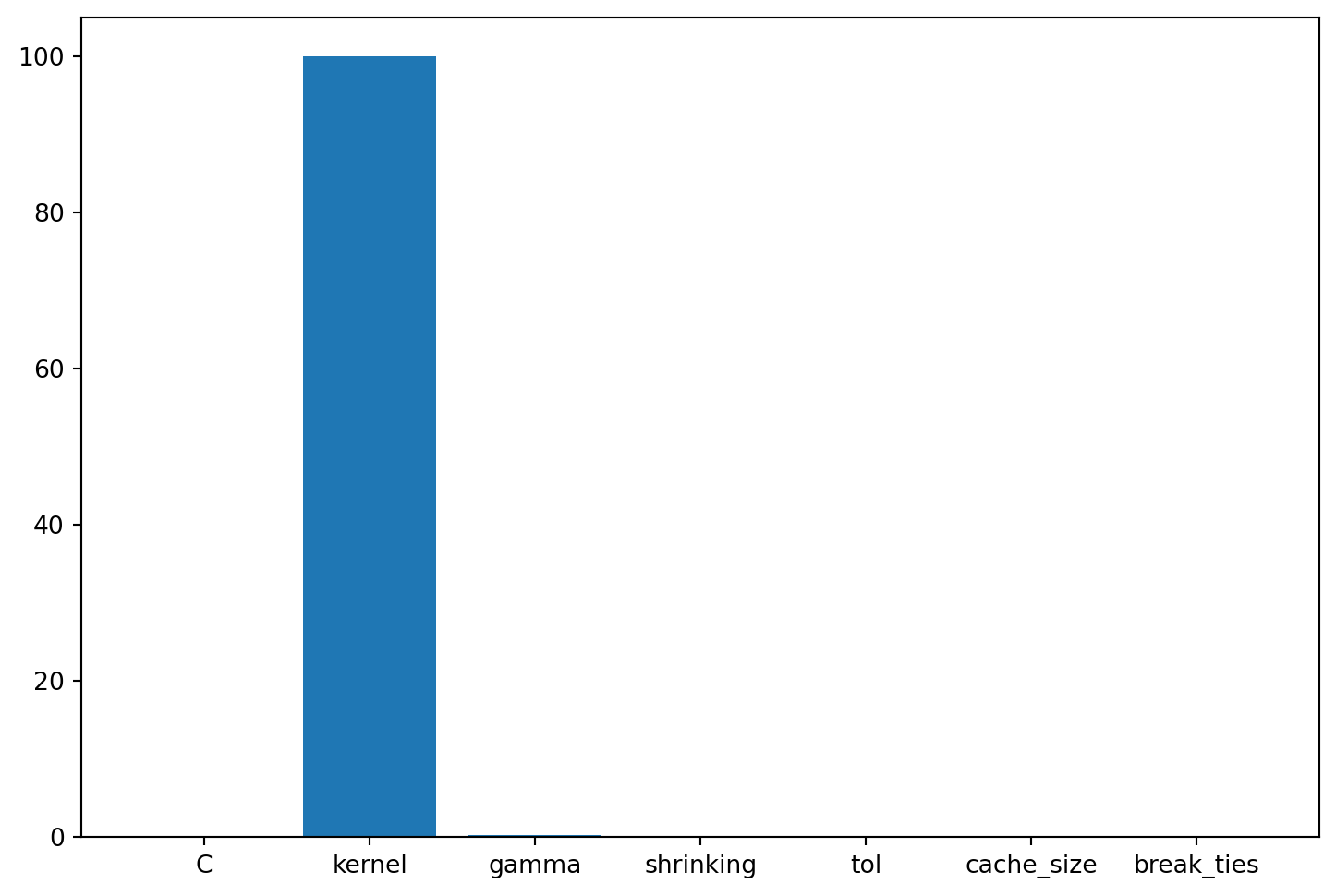
35.11 Get Default Hyperparameters
The default hyperparameters, whihc will be used for a comparion with the tuned hyperparameters, can be obtained with the following commands:
X_start = get_default_hyperparameters_as_array(fun_control)
model_default = get_one_core_model_from_X(X_start, fun_control, default=True)
model_defaultSVC(cache_size=200.0, shrinking=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| C | 1.0 | |
| kernel | 'rbf' | |
| degree | 3 | |
| gamma | 'scale' | |
| coef0 | 0.0 | |
| shrinking | False | |
| probability | False | |
| tol | 0.001 | |
| cache_size | 200.0 | |
| class_weight | None | |
| verbose | False | |
| max_iter | -1 | |
| decision_function_shape | 'ovr' | |
| break_ties | False | |
| random_state | None |
35.12 Get SPOT Results
In a similar way, we can obtain the hyperparameters found by spotpython.
X = spot_tuner.to_all_dim(spot_tuner.min_X.reshape(1,-1))
model_spot = get_one_core_model_from_X(X, fun_control)35.12.1 Plot: Compare Predictions
plot_roc(model_list=[model_default, model_spot], fun_control= fun_control, model_names=["Default", "Spot"])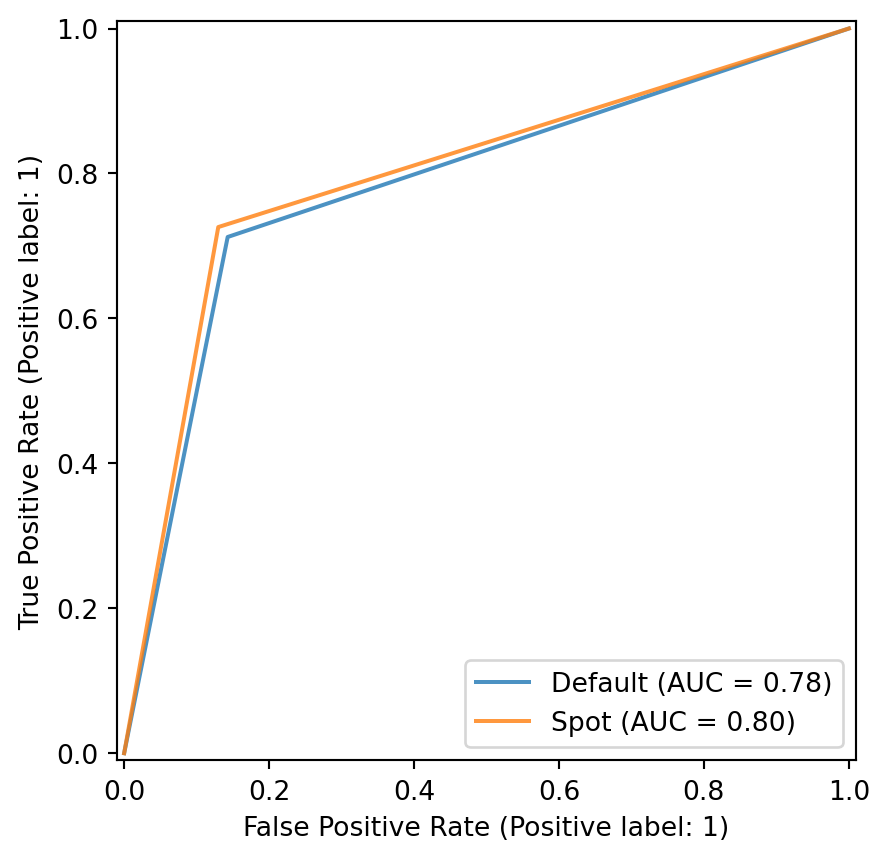
plot_confusion_matrix(model=model_default, fun_control=fun_control, title = "Default")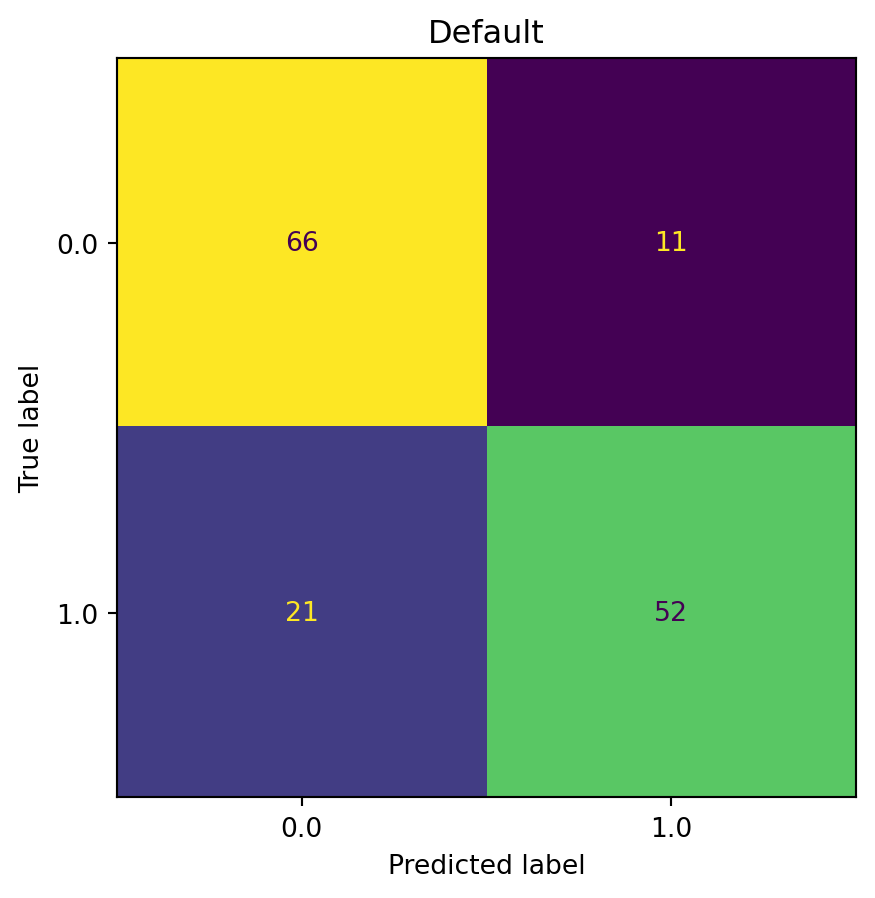
# label: 401_plot_confusion_matrix
plot_confusion_matrix(model=model_spot, fun_control=fun_control, title="SPOT")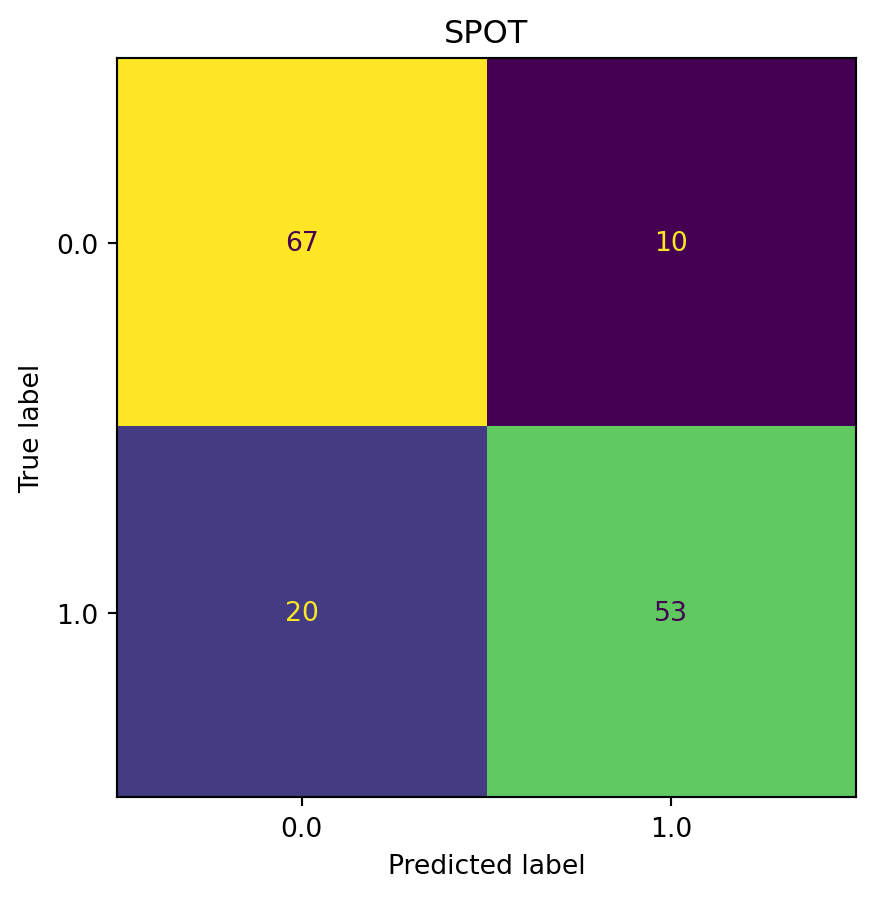
min(spot_tuner.y), max(spot_tuner.y)(np.float64(6.436366676628063), np.float64(10.813096016735146))35.12.2 Detailed Hyperparameter Plots
spot_tuner.plot_important_hyperparameter_contour(max_imp=3)C: 0.7973092918715939
kernel: 100.00000000000001
gamma: 0.007904417006648371
shrinking: 0.8842206579591482
tol: 0.00948291123874377
cache_size: 0.007904417006648371
break_ties: 0.007904417006648371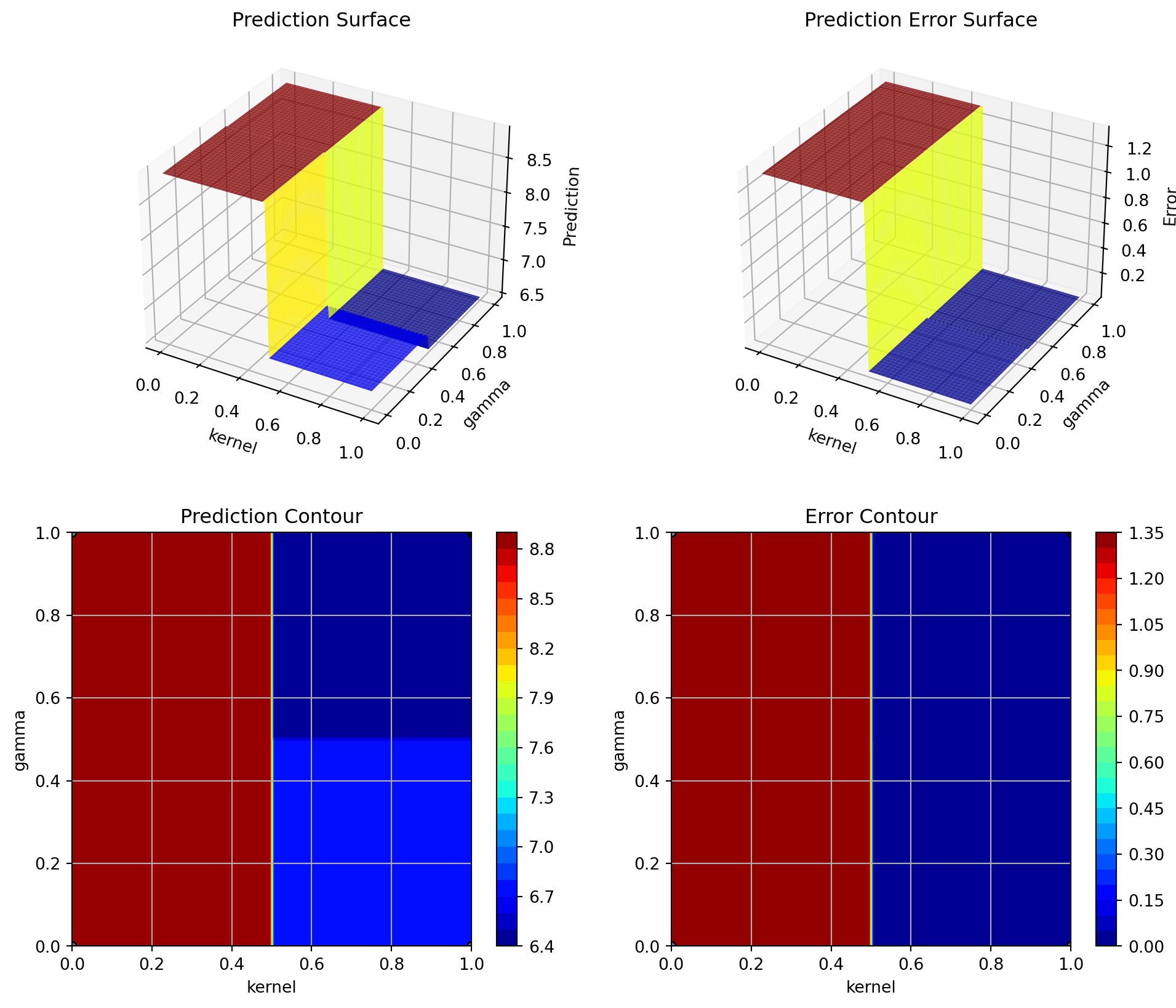
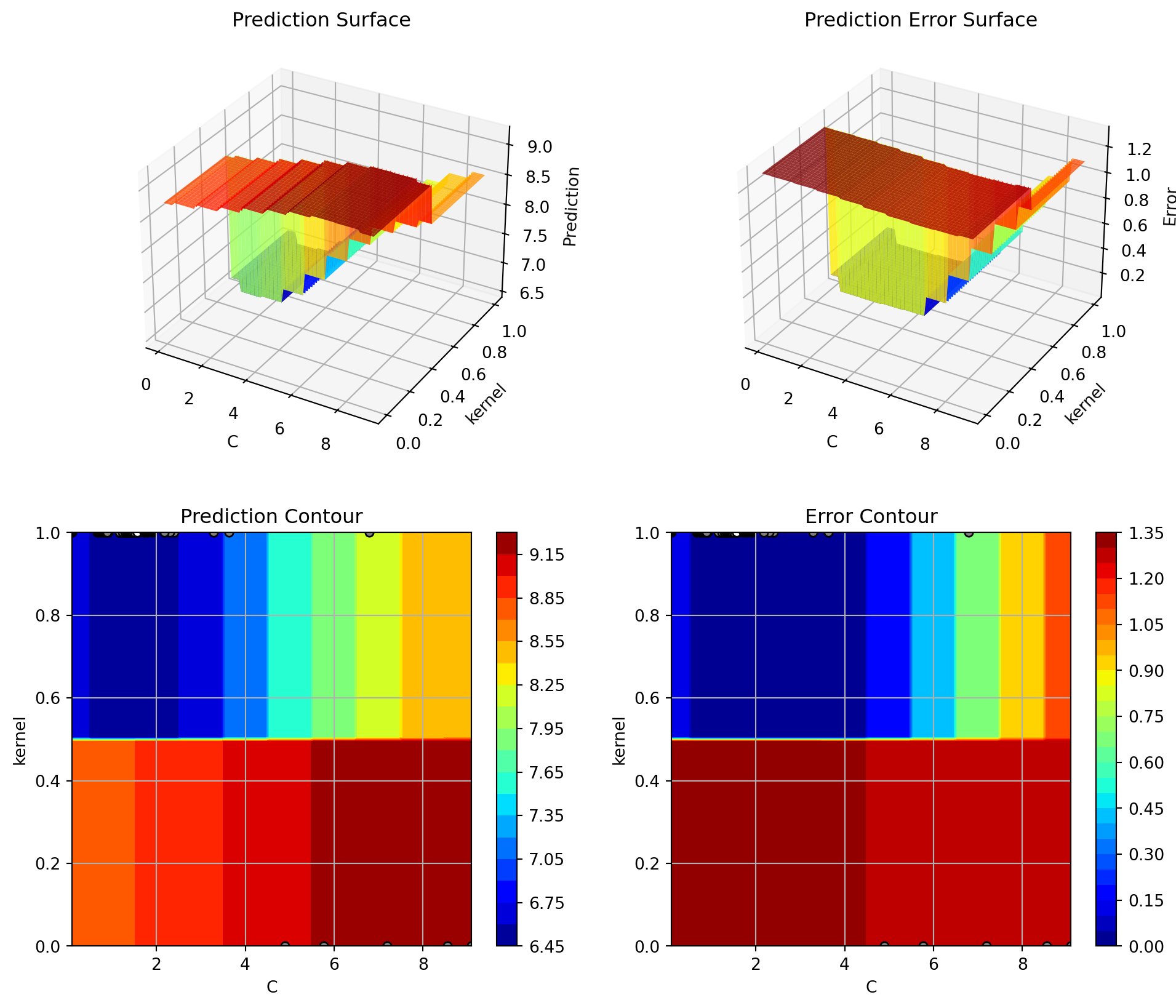
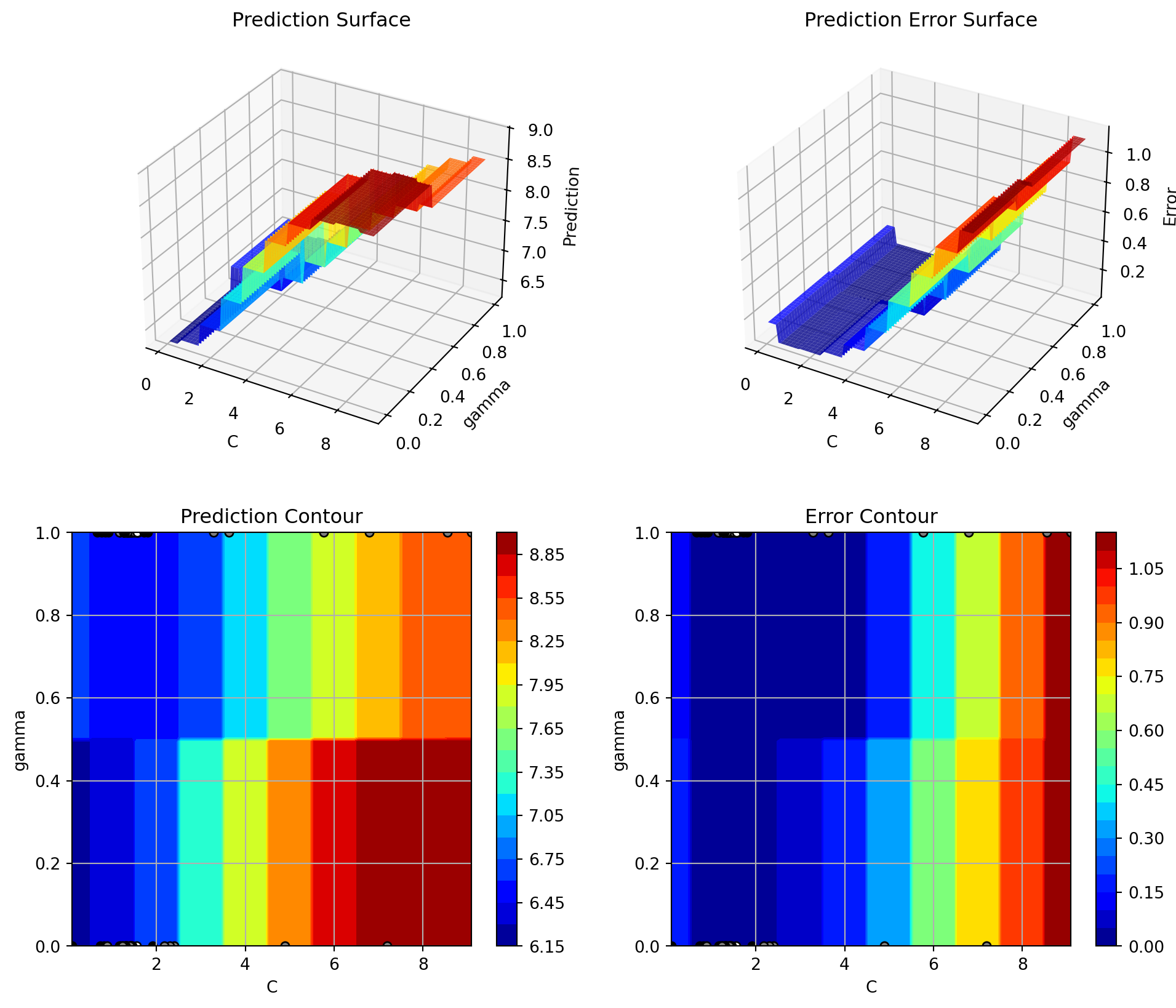
35.12.3 Parallel Coordinates Plot
spot_tuner.parallel_plot()35.12.4 Plot all Combinations of Hyperparameters
- Warning: this may take a while.
PLOT_ALL = False
if PLOT_ALL:
n = spot_tuner.k
for i in range(n-1):
for j in range(i+1, n):
spot_tuner.plot_contour(i=i, j=j, min_z=min_z, max_z = max_z)