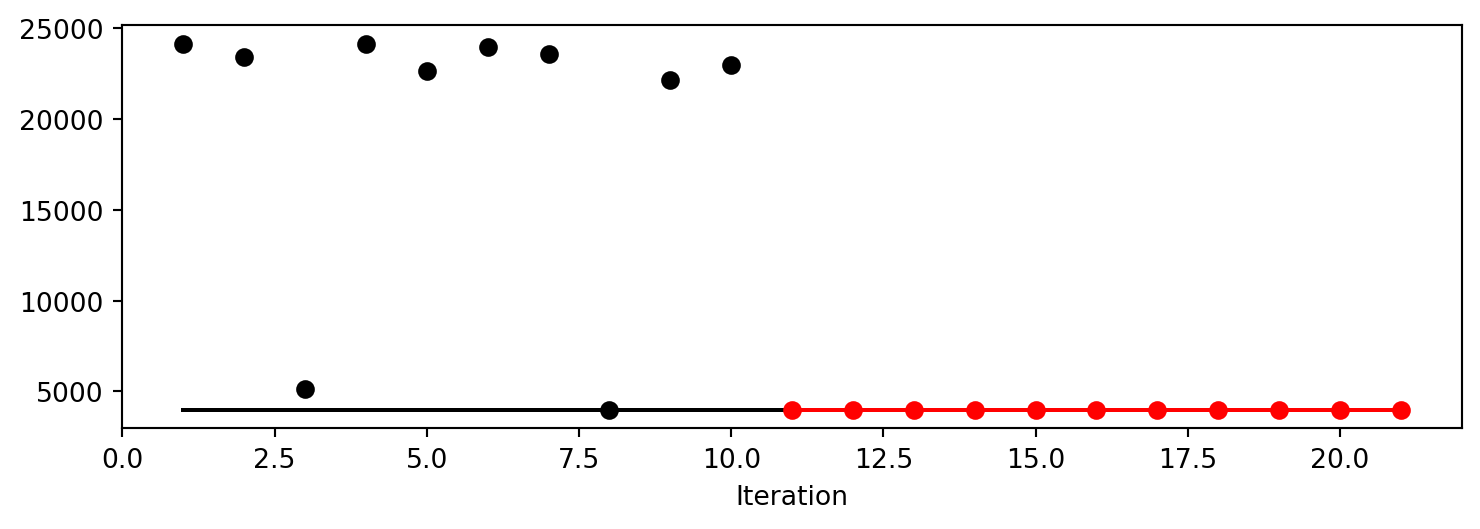
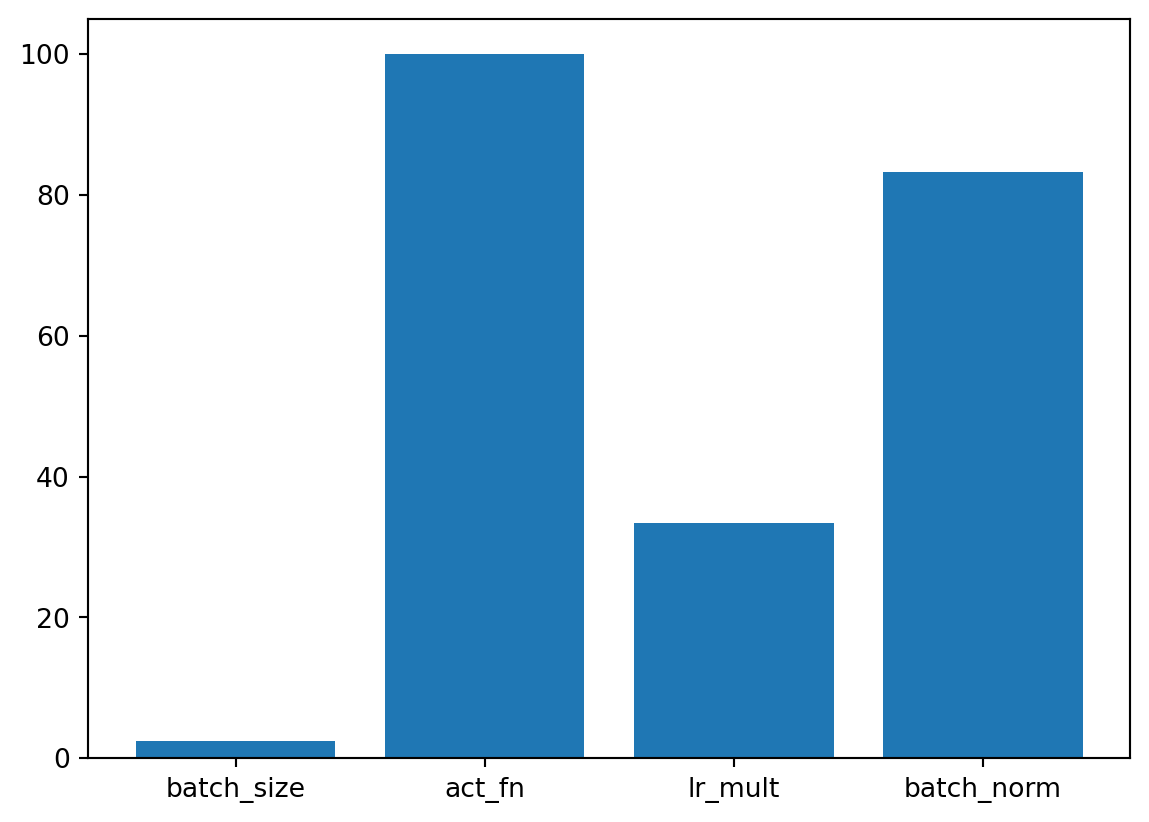
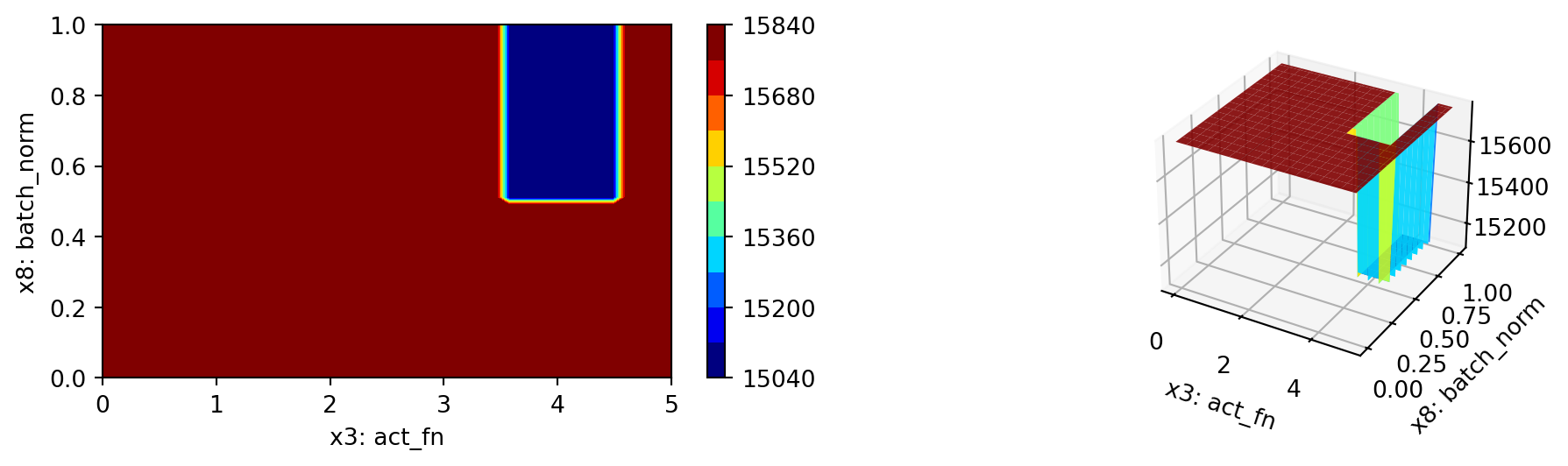
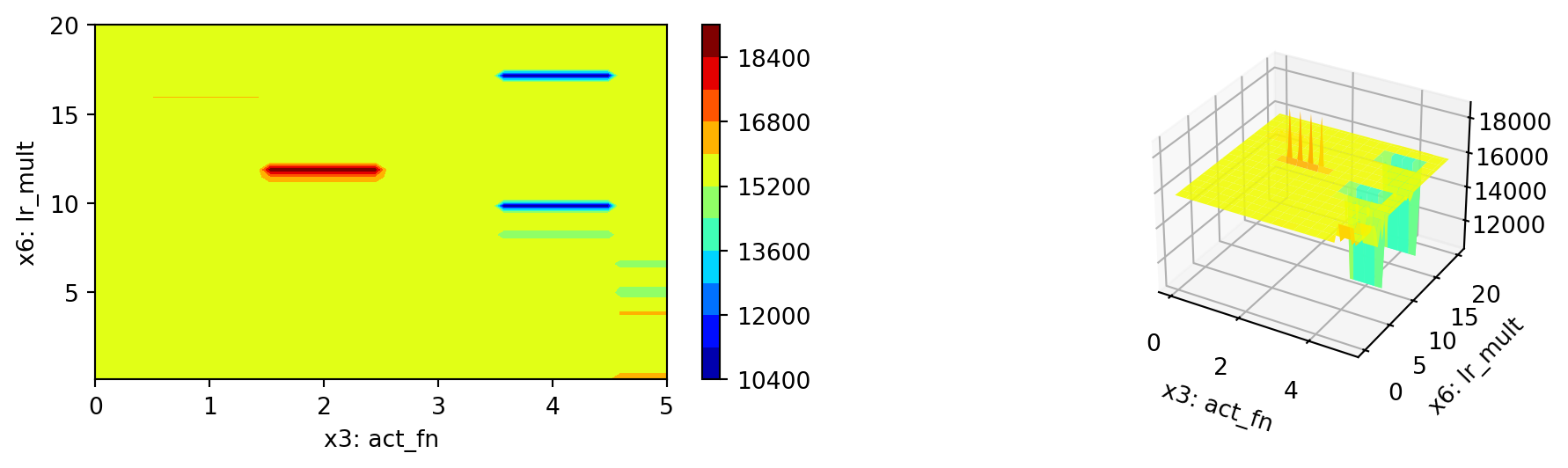
= Spot(fun= fun,fun_control= fun_control, design_control= design_control)= spot_tuner.run()
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24266.927734375, 'hp_metric': 24266.927734375}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 24001.298828125, 'hp_metric': 24001.298828125}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 21142.806640625, 'hp_metric': 21142.806640625}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 24029.455078125, 'hp_metric': 24029.455078125}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 23382.876953125, 'hp_metric': 23382.876953125}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 24010.201171875, 'hp_metric': 24010.201171875}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23698.623046875, 'hp_metric': 23698.623046875}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 23921.322265625, 'hp_metric': 23921.322265625}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 23699.216796875, 'hp_metric': 23699.216796875}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24038.666015625, 'hp_metric': 24038.666015625}
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23752.283203125, 'hp_metric': 23752.283203125}
spotpython tuning: 21142.806640625 [----------] 0.59%. Success rate: 0.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 22542.3828125, 'hp_metric': 22542.3828125}
spotpython tuning: 21142.806640625 [----------] 1.13%. Success rate: 0.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 21875.419921875, 'hp_metric': 21875.419921875}
spotpython tuning: 21142.806640625 [----------] 2.15%. Success rate: 0.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 22236.15234375, 'hp_metric': 22236.15234375}
spotpython tuning: 21142.806640625 [----------] 3.13%. Success rate: 0.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 16283.1318359375, 'hp_metric': 16283.1318359375}
spotpython tuning: 16283.1318359375 [----------] 4.07%. Success rate: 20.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 22554.375, 'hp_metric': 22554.375}
spotpython tuning: 16283.1318359375 [----------] 4.73%. Success rate: 16.67%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 20658.12890625, 'hp_metric': 20658.12890625}
spotpython tuning: 16283.1318359375 [#---------] 5.47%. Success rate: 14.29%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 8588.830078125, 'hp_metric': 8588.830078125}
spotpython tuning: 8588.830078125 [#---------] 6.03%. Success rate: 25.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23619.22265625, 'hp_metric': 23619.22265625}
spotpython tuning: 8588.830078125 [#---------] 6.63%. Success rate: 22.22%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23825.615234375, 'hp_metric': 23825.615234375}
spotpython tuning: 8588.830078125 [#---------] 7.12%. Success rate: 20.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23993.693359375, 'hp_metric': 23993.693359375}
spotpython tuning: 8588.830078125 [#---------] 7.85%. Success rate: 18.18%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23921.734375, 'hp_metric': 23921.734375}
spotpython tuning: 8588.830078125 [#---------] 8.61%. Success rate: 16.67%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24051.060546875, 'hp_metric': 24051.060546875}
spotpython tuning: 8588.830078125 [#---------] 9.37%. Success rate: 15.38%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23882.166015625, 'hp_metric': 23882.166015625}
spotpython tuning: 8588.830078125 [#---------] 10.06%. Success rate: 14.29%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 22620.6328125, 'hp_metric': 22620.6328125}
spotpython tuning: 8588.830078125 [#---------] 10.78%. Success rate: 13.33%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24091.826171875, 'hp_metric': 24091.826171875}
spotpython tuning: 8588.830078125 [#---------] 11.42%. Success rate: 12.50%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 24000.14453125, 'hp_metric': 24000.14453125}
spotpython tuning: 8588.830078125 [#---------] 12.07%. Success rate: 11.76%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 23777.0234375, 'hp_metric': 23777.0234375}
spotpython tuning: 8588.830078125 [#---------] 12.91%. Success rate: 11.11%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23824.72265625, 'hp_metric': 23824.72265625}
spotpython tuning: 8588.830078125 [#---------] 13.62%. Success rate: 10.53%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 16348.5556640625, 'hp_metric': 16348.5556640625}
spotpython tuning: 8588.830078125 [#---------] 14.99%. Success rate: 10.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 542253.5625, 'hp_metric': 542253.5625}
spotpython tuning: 8588.830078125 [##--------] 15.79%. Success rate: 9.52%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 21935.23046875, 'hp_metric': 21935.23046875}
spotpython tuning: 8588.830078125 [##--------] 18.39%. Success rate: 9.09%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24014.890625, 'hp_metric': 24014.890625}
spotpython tuning: 8588.830078125 [##--------] 20.99%. Success rate: 8.70%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 21583.421875, 'hp_metric': 21583.421875}
spotpython tuning: 8588.830078125 [##--------] 23.72%. Success rate: 8.33%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24219.591796875, 'hp_metric': 24219.591796875}
spotpython tuning: 8588.830078125 [###-------] 26.47%. Success rate: 8.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 23552.76171875, 'hp_metric': 23552.76171875}
spotpython tuning: 8588.830078125 [###-------] 28.70%. Success rate: 7.69%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23819.322265625, 'hp_metric': 23819.322265625}
spotpython tuning: 8588.830078125 [###-------] 29.31%. Success rate: 7.41%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 24035.205078125, 'hp_metric': 24035.205078125}
spotpython tuning: 8588.830078125 [###-------] 30.98%. Success rate: 7.14%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24020.1328125, 'hp_metric': 24020.1328125}
spotpython tuning: 8588.830078125 [####------] 35.31%. Success rate: 6.90%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 23895.53125, 'hp_metric': 23895.53125}
spotpython tuning: 8588.830078125 [####------] 37.66%. Success rate: 6.67%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24009.51171875, 'hp_metric': 24009.51171875}
spotpython tuning: 8588.830078125 [####------] 39.80%. Success rate: 6.45%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 24054.033203125, 'hp_metric': 24054.033203125}
spotpython tuning: 8588.830078125 [####------] 41.62%. Success rate: 6.25%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 24168.806640625, 'hp_metric': 24168.806640625}
spotpython tuning: 8588.830078125 [####------] 44.22%. Success rate: 6.06%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 24035.931640625, 'hp_metric': 24035.931640625}
spotpython tuning: 8588.830078125 [#####-----] 47.13%. Success rate: 5.88%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23980.1328125, 'hp_metric': 23980.1328125}
spotpython tuning: 8588.830078125 [#####-----] 47.95%. Success rate: 5.71%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24006.662109375, 'hp_metric': 24006.662109375}
spotpython tuning: 8588.830078125 [#####-----] 52.16%. Success rate: 5.56%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 23640.08984375, 'hp_metric': 23640.08984375}
spotpython tuning: 8588.830078125 [######----] 55.99%. Success rate: 5.41%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 24108.263671875, 'hp_metric': 24108.263671875}
spotpython tuning: 8588.830078125 [######----] 59.61%. Success rate: 5.26%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 8761.345703125, 'hp_metric': 8761.345703125}
spotpython tuning: 8588.830078125 [######----] 62.02%. Success rate: 5.13%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23936.365234375, 'hp_metric': 23936.365234375}
spotpython tuning: 8588.830078125 [#######---] 66.77%. Success rate: 5.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23658.79296875, 'hp_metric': 23658.79296875}
spotpython tuning: 8588.830078125 [#######---] 67.59%. Success rate: 4.88%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 21879.568359375, 'hp_metric': 21879.568359375}
spotpython tuning: 8588.830078125 [#######---] 68.80%. Success rate: 4.76%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 23994.609375, 'hp_metric': 23994.609375}
spotpython tuning: 8588.830078125 [#######---] 70.74%. Success rate: 4.65%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 22487.458984375, 'hp_metric': 22487.458984375}
spotpython tuning: 8588.830078125 [#######---] 73.44%. Success rate: 4.55%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 22477.447265625, 'hp_metric': 22477.447265625}
spotpython tuning: 8588.830078125 [#######---] 74.03%. Success rate: 4.44%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 13692.08984375, 'hp_metric': 13692.08984375}
spotpython tuning: 8588.830078125 [########--] 78.93%. Success rate: 4.35%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24043.455078125, 'hp_metric': 24043.455078125}
spotpython tuning: 8588.830078125 [########--] 81.04%. Success rate: 4.26%
Using spacefilling design as fallback.
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 2.6 K │ [[16, 8], [16, 2]] │ [16, 8] │
│ 1 │ layers │ Sequential │ 153 │ train │ 4.2 K │ [16, 8] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 249
Non-trainable params : 0
Total params : 249
Total estimated model params size (MB) : 0
Modules in train mode : 18
Modules in eval mode : 0
Total FLOPs : 6.7 K
train_model result: {'val_loss': 23562.740234375, 'hp_metric': 23562.740234375}
spotpython tuning: 8588.830078125 [########--] 81.62%. Success rate: 4.17%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23973.388671875, 'hp_metric': 23973.388671875}
spotpython tuning: 8588.830078125 [########--] 84.28%. Success rate: 4.08%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 23741.322265625, 'hp_metric': 23741.322265625}
spotpython tuning: 8588.830078125 [#########-] 88.13%. Success rate: 4.00%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 52557.8828125, 'hp_metric': 52557.8828125}
spotpython tuning: 8588.830078125 [#########-] 91.41%. Success rate: 3.92%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 23981.197265625, 'hp_metric': 23981.197265625}
spotpython tuning: 8588.830078125 [#########-] 92.16%. Success rate: 3.85%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 10.2 K │ [[32, 8], [32, 2]] │ [32, 16] │
│ 1 │ layers │ Sequential │ 691 │ train │ 34.2 K │ [32, 16] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 883
Non-trainable params : 0
Total params : 883
Total estimated model params size (MB) : 0
Modules in train mode : 36
Modules in eval mode : 0
Total FLOPs : 44.4 K
train_model result: {'val_loss': 24007.826171875, 'hp_metric': 24007.826171875}
spotpython tuning: 8588.830078125 [#########-] 93.96%. Success rate: 3.77%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 24064.419921875, 'hp_metric': 24064.419921875}
spotpython tuning: 8588.830078125 [##########] 95.29%. Success rate: 3.70%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 5181.326171875, 'hp_metric': 5181.326171875}
spotpython tuning: 5181.326171875 [##########] 96.04%. Success rate: 5.45%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 96 │ train │ 5.1 K │ [[32, 8], [32, 2]] │ [32, 8] │
│ 1 │ layers │ Sequential │ 197 │ train │ 8.3 K │ [32, 8] │ [32, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴───────┴────────────────────┴───────────┘
Trainable params : 293
Non-trainable params : 0
Total params : 293
Total estimated model params size (MB) : 0
Modules in train mode : 24
Modules in eval mode : 0
Total FLOPs : 13.4 K
train_model result: {'val_loss': 20914.025390625, 'hp_metric': 20914.025390625}
spotpython tuning: 5181.326171875 [##########] 99.37%. Success rate: 5.36%
┏━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ cond_layer │ ConditionalLayer │ 192 │ train │ 5.1 K │ [[16, 8], [16, 2]] │ [16, 16] │
│ 1 │ layers │ Sequential │ 587 │ train │ 17.1 K │ [16, 16] │ [16, 1] │
└───┴────────────┴──────────────────┴────────┴───────┴────────┴────────────────────┴───────────┘
Trainable params : 779
Non-trainable params : 0
Total params : 779
Total estimated model params size (MB) : 0
Modules in train mode : 26
Modules in eval mode : 0
Total FLOPs : 22.2 K
train_model result: {'val_loss': 182654.625, 'hp_metric': 182654.625}
spotpython tuning: 5181.326171875 [##########] 100.00%. Success rate: 5.26% Done...
Experiment saved to CondNet_01_res.pkl