import os
from math import inf
import warnings
warnings.filterwarnings("ignore")45 Hyperparameter Tuning with spotpython and PyTorch Lightning for the Diabetes Data Set
In this section, we will show how spotpython can be integrated into the PyTorch Lightning training workflow for a regression task. It demonstrates how easy it is to use spotpython to tune hyperparameters for a PyTorch Lightning model.
45.1 The Basic Setting
After importing the necessary libraries, the fun_control dictionary is set up via the fun_control_init function. The fun_control dictionary contains
PREFIX: a unique identifier for the experimentfun_evals: the number of function evaluationsmax_time: the maximum run time in minutesdata_set: the data set. Here we use theDiabetesdata set that is provided byspotpython.core_model_name: the class name of the neural network model. This neural network model is provided byspotpython.hyperdict: the hyperparameter dictionary. This dictionary is used to define the hyperparameters of the neural network model. It is also provided byspotpython._L_in: the number of input features. Since theDiabetesdata set has 10 features,_L_inis set to 10._L_out: the number of output features. Since we want to predict a single value,_L_outis set to 1.
The HyperLight class is used to define the objective function fun. It connects the PyTorch and the spotpython methods and is provided by spotpython.
from spotpython.data.diabetes import Diabetes
from spotpython.hyperdict.light_hyper_dict import LightHyperDict
from spotpython.fun.hyperlight import HyperLight
from spotpython.utils.init import (fun_control_init, surrogate_control_init, design_control_init)
from spotpython.utils.eda import print_exp_table, print_res_table
from spotpython.spot import Spot
from spotpython.utils.file import get_experiment_filename
PREFIX="601"
data_set = Diabetes()
fun_control = fun_control_init(
PREFIX=PREFIX,
fun_evals=inf,
max_time=1,
data_set = data_set,
core_model_name="light.regression.NNLinearRegressor",
hyperdict=LightHyperDict,
_L_in=10,
_L_out=1)
fun = HyperLight().funmodule_name: light
submodule_name: regression
model_name: NNLinearRegressorThe method set_hyperparameter allows the user to modify default hyperparameter settings. Here we modify some hyperparameters to keep the model small and to decrease the tuning time.
from spotpython.hyperparameters.values import set_hyperparameter
set_hyperparameter(fun_control, "optimizer", [ "Adadelta", "Adam", "Adamax"])
set_hyperparameter(fun_control, "l1", [3,4])
set_hyperparameter(fun_control, "epochs", [3,7])
set_hyperparameter(fun_control, "batch_size", [4,11])
set_hyperparameter(fun_control, "dropout_prob", [0.0, 0.025])
set_hyperparameter(fun_control, "patience", [2,3])
design_control = design_control_init(init_size=10)
print_exp_table(fun_control)| name | type | default | lower | upper | transform |
|----------------|--------|-----------|---------|---------|-----------------------|
| l1 | int | 3 | 3 | 4 | transform_power_2_int |
| epochs | int | 4 | 3 | 7 | transform_power_2_int |
| batch_size | int | 4 | 4 | 11 | transform_power_2_int |
| act_fn | factor | ReLU | 0 | 5 | None |
| optimizer | factor | SGD | 0 | 2 | None |
| dropout_prob | float | 0.01 | 0 | 0.025 | None |
| lr_mult | float | 1.0 | 0.1 | 10 | None |
| patience | int | 2 | 2 | 3 | transform_power_2_int |
| batch_norm | factor | 0 | 0 | 1 | None |
| initialization | factor | Default | 0 | 4 | None |Finally, a Spot object is created. Calling the method run() starts the hyperparameter tuning process.
S = Spot(fun=fun,fun_control=fun_control, design_control=design_control)
S.run()┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 826 M │ [2048, 10] │ [2048, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 826 M
train_model result: {'val_loss': 23075.09765625, 'hp_metric': 23075.09765625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 3466.626220703125, 'hp_metric': 3466.626220703125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 4775.9482421875, 'hp_metric': 4775.9482421875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 23975.263671875, 'hp_metric': 23975.263671875}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 22921.740234375, 'hp_metric': 22921.740234375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 4060.3369140625, 'hp_metric': 4060.3369140625}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 52.5 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 52.5 M
train_model result: {'val_loss': 20739.09375, 'hp_metric': 20739.09375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 3873.864990234375, 'hp_metric': 3873.864990234375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 13.1 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 13.1 M
train_model result: {'val_loss': 20911.953125, 'hp_metric': 20911.953125}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 413 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 413 M
train_model result: {'val_loss': 23951.484375, 'hp_metric': 23951.484375}┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3849.736083984375, 'hp_metric': 3849.736083984375}
spotpython tuning: 3466.626220703125 [----------] 3.04%. Success rate: 0.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 2951.248291015625, 'hp_metric': 2951.248291015625}
spotpython tuning: 2951.248291015625 [#---------] 6.03%. Success rate: 50.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3231.650634765625, 'hp_metric': 3231.650634765625}
spotpython tuning: 2951.248291015625 [#---------] 9.47%. Success rate: 33.33% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 4529.53173828125, 'hp_metric': 4529.53173828125}
spotpython tuning: 2951.248291015625 [#---------] 13.58%. Success rate: 25.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3681.19580078125, 'hp_metric': 3681.19580078125}
spotpython tuning: 2951.248291015625 [##--------] 16.76%. Success rate: 20.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3431.694580078125, 'hp_metric': 3431.694580078125}
spotpython tuning: 2951.248291015625 [##--------] 20.60%. Success rate: 16.67% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3088.29150390625, 'hp_metric': 3088.29150390625}
spotpython tuning: 2951.248291015625 [##--------] 23.73%. Success rate: 14.29% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 206 M │ [512, 10] │ [512, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 206 M
train_model result: {'val_loss': 23220.31640625, 'hp_metric': 23220.31640625}
spotpython tuning: 2951.248291015625 [###-------] 26.69%. Success rate: 12.50% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3073.880859375, 'hp_metric': 3073.880859375}
spotpython tuning: 2951.248291015625 [###-------] 30.15%. Success rate: 11.11% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3184.729736328125, 'hp_metric': 3184.729736328125}
spotpython tuning: 2951.248291015625 [###-------] 33.99%. Success rate: 10.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 103 M │ [256, 10] │ [256, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 103 M
train_model result: {'val_loss': 14631.6435546875, 'hp_metric': 14631.6435546875}
spotpython tuning: 2951.248291015625 [####------] 36.12%. Success rate: 9.09% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3149.479248046875, 'hp_metric': 3149.479248046875}
spotpython tuning: 2951.248291015625 [####------] 38.83%. Success rate: 8.33% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 3920.870849609375, 'hp_metric': 3920.870849609375}
spotpython tuning: 2951.248291015625 [####------] 42.50%. Success rate: 7.69% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 51.6 M │ [128, 10] │ [128, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 51.6 M
train_model result: {'val_loss': 8323.37890625, 'hp_metric': 8323.37890625}
spotpython tuning: 2951.248291015625 [#####-----] 45.54%. Success rate: 7.14% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 3683.1748046875, 'hp_metric': 3683.1748046875}
spotpython tuning: 2951.248291015625 [#####-----] 48.76%. Success rate: 6.67% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 3.3 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 3.3 M
train_model result: {'val_loss': 22978.158203125, 'hp_metric': 22978.158203125}
spotpython tuning: 2951.248291015625 [#####-----] 51.02%. Success rate: 6.25% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 20163.91015625, 'hp_metric': 20163.91015625}
spotpython tuning: 2951.248291015625 [#####-----] 53.55%. Success rate: 5.88% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3537.125244140625, 'hp_metric': 3537.125244140625}
spotpython tuning: 2951.248291015625 [######----] 56.69%. Success rate: 5.56% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 9505.927734375, 'hp_metric': 9505.927734375}
spotpython tuning: 2951.248291015625 [######----] 59.74%. Success rate: 5.26% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 205 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 205 K Non-trainable params: 0 Total params: 205 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 23010.025390625, 'hp_metric': 23010.025390625}
spotpython tuning: 2951.248291015625 [#######---] 65.18%. Success rate: 5.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3156.76513671875, 'hp_metric': 3156.76513671875}
spotpython tuning: 2951.248291015625 [#######---] 66.86%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 67.97%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 69.03%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 70.06%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 71.12%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 72.17%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 73.20%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [#######---] 74.26%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [########--] 75.29%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [########--] 76.37%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [########--] 77.43%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': nan, 'hp_metric': nan}
spotpython tuning: 2951.248291015625 [########--] 78.49%. Success rate: 4.76% Using spacefilling design as fallback.┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 104 M │ [1024, 10] │ [1024, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 104 M
train_model result: {'val_loss': 14037.4052734375, 'hp_metric': 14037.4052734375}
spotpython tuning: 2951.248291015625 [########--] 79.42%. Success rate: 4.55% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 4839.69775390625, 'hp_metric': 4839.69775390625}
spotpython tuning: 2951.248291015625 [########--] 82.20%. Success rate: 4.35% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 3723.298095703125, 'hp_metric': 3723.298095703125}
spotpython tuning: 2951.248291015625 [#########-] 85.77%. Success rate: 4.17% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 12.9 M │ [32, 10] │ [32, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 12.9 M
train_model result: {'val_loss': 4467.46923828125, 'hp_metric': 4467.46923828125}
spotpython tuning: 2951.248291015625 [#########-] 88.45%. Success rate: 4.00% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 51.9 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 51.9 K Non-trainable params: 0 Total params: 51.9 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 3218.08349609375, 'hp_metric': 3218.08349609375}
spotpython tuning: 2951.248291015625 [#########-] 91.16%. Success rate: 3.85% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 25.8 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 25.8 M
train_model result: {'val_loss': 18673.591796875, 'hp_metric': 18673.591796875}
spotpython tuning: 2951.248291015625 [##########] 95.40%. Success rate: 3.70% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 6.6 M │ [64, 10] │ [64, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 6.6 M
train_model result: {'val_loss': 22501.916015625, 'hp_metric': 22501.916015625}
spotpython tuning: 2951.248291015625 [##########] 97.90%. Success rate: 3.57% ┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 53.2 K │ train │ 1.6 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 53.2 K Non-trainable params: 0 Total params: 53.2 K Total estimated model params size (MB): 0 Modules in train mode: 24 Modules in eval mode: 0 Total FLOPs: 1.6 M
train_model result: {'val_loss': 3526.53564453125, 'hp_metric': 3526.53564453125}
spotpython tuning: 2951.248291015625 [##########] 100.00%. Success rate: 3.45% Done...
Experiment saved to 601_res.pkl<spotpython.spot.spot.Spot at 0x10c4070e0>45.2 Looking at the Results
45.2.1 Tuning Progress
After the hyperparameter tuning run is finished, the progress of the hyperparameter tuning can be visualized with spotpython’s method plot_progress. The black points represent the performace values (score or metric) of hyperparameter configurations from the initial design, whereas the red points represents the hyperparameter configurations found by the surrogate model based optimization.
S.plot_progress()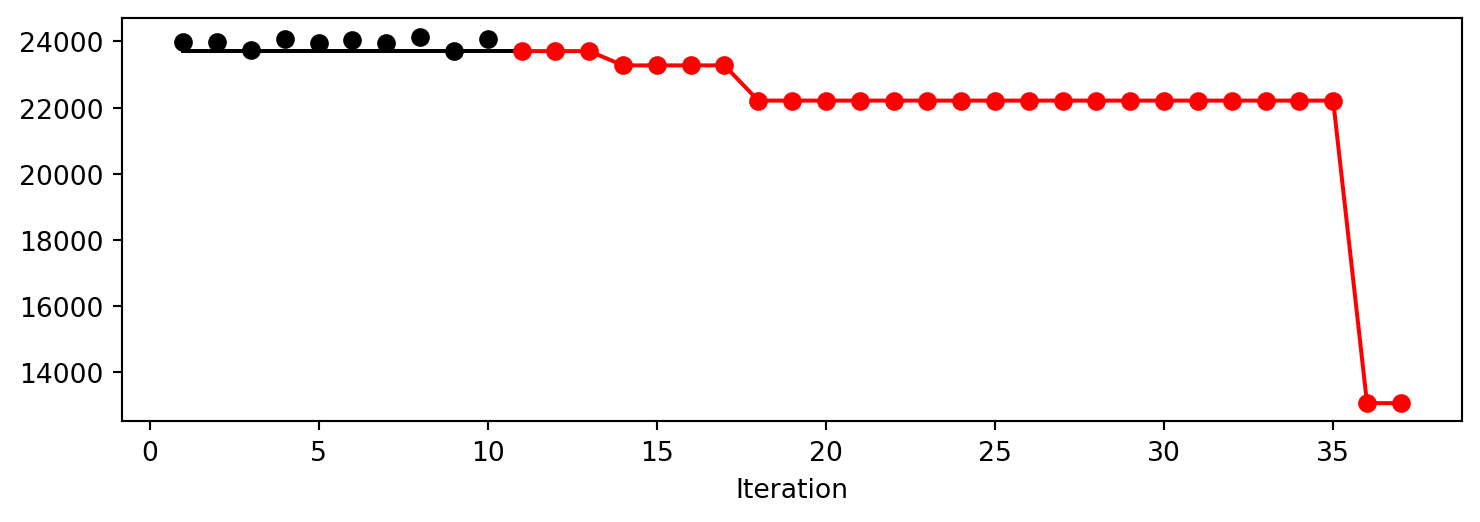
45.2.2 Tuned Hyperparameters and Their Importance
Results can be printed in tabular form.
print_res_table(S)| name | type | default | lower | upper | tuned | transform | importance | stars |
|----------------|--------|-----------|---------|---------|-------------------|-----------------------|--------------|---------|
| l1 | int | 3 | 3.0 | 4.0 | 4.0 | transform_power_2_int | 50.92 | ** |
| epochs | int | 4 | 3.0 | 7.0 | 6.0 | transform_power_2_int | 0.20 | . |
| batch_size | int | 4 | 4.0 | 11.0 | 4.0 | transform_power_2_int | 2.59 | * |
| act_fn | factor | ReLU | 0.0 | 5.0 | Swish | None | 46.62 | * |
| optimizer | factor | SGD | 0.0 | 2.0 | Adamax | None | 48.16 | * |
| dropout_prob | float | 0.01 | 0.0 | 0.025 | 0.025 | None | 0.76 | . |
| lr_mult | float | 1.0 | 0.1 | 10.0 | 5.159276791225372 | None | 0.06 | |
| patience | int | 2 | 2.0 | 3.0 | 3.0 | transform_power_2_int | 0.06 | |
| batch_norm | factor | 0 | 0.0 | 1.0 | 0 | None | 100.00 | *** |
| initialization | factor | Default | 0.0 | 4.0 | xavier_normal | None | 43.84 | * |A histogram can be used to visualize the most important hyperparameters.
S.plot_importance(threshold=1.0)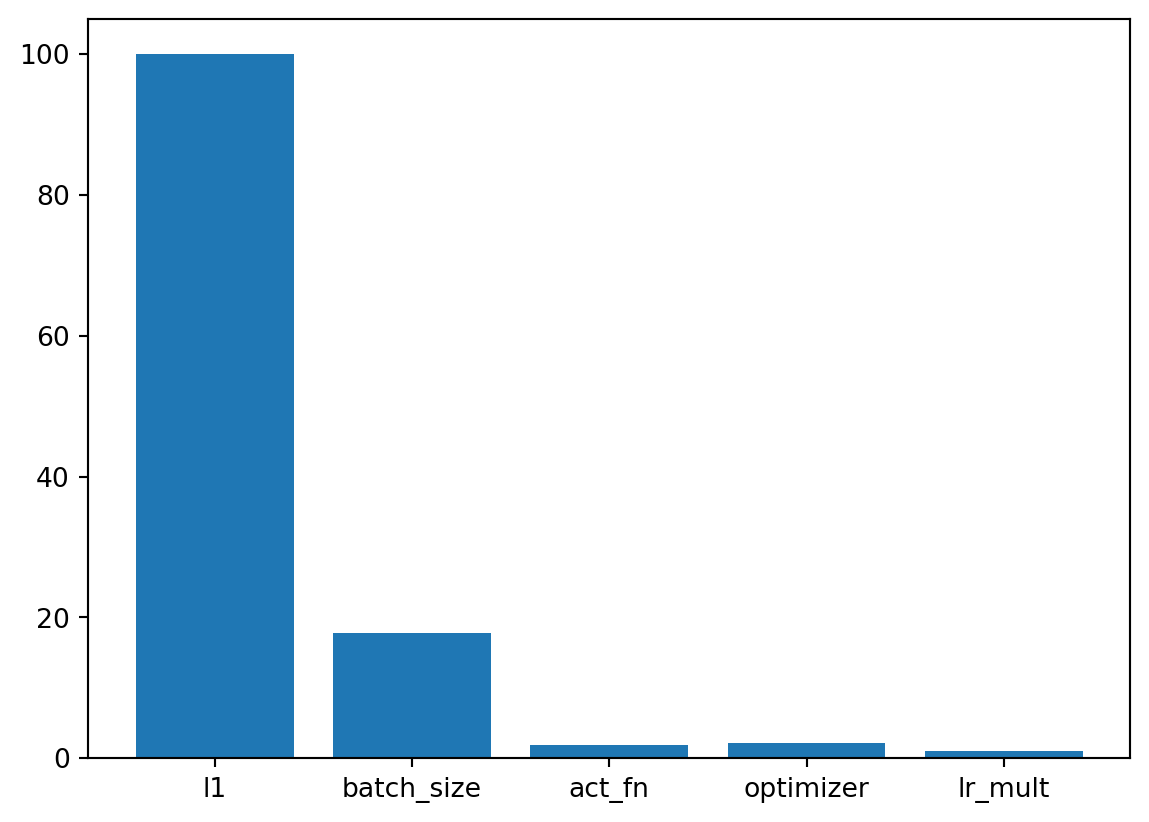
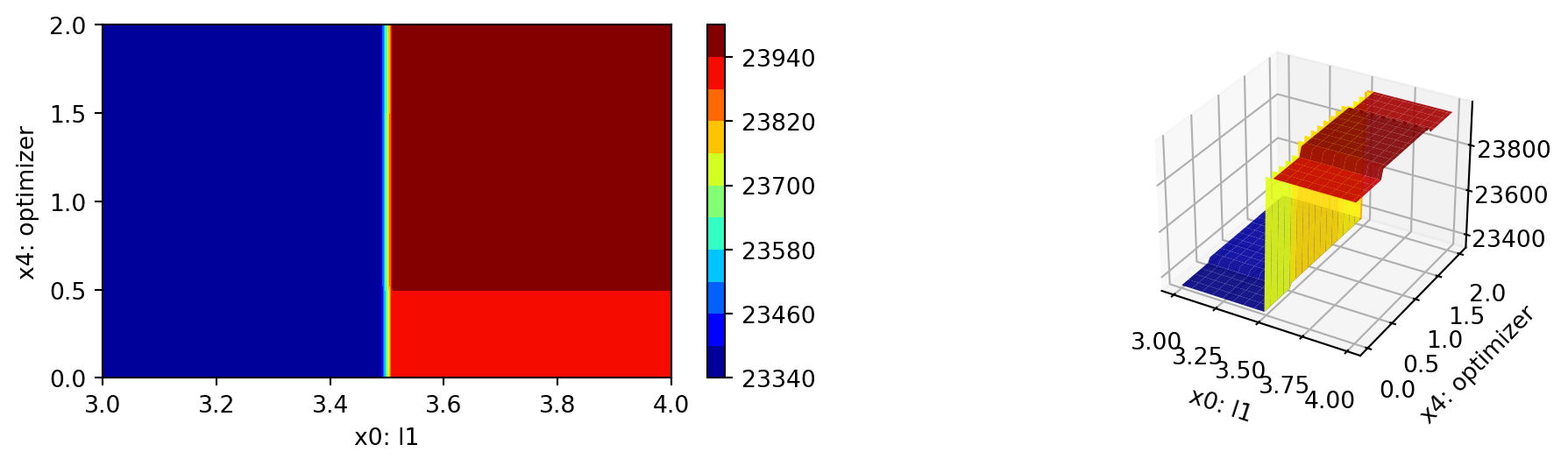
S.plot_important_hyperparameter_contour(max_imp=3)l1: 50.91556329257147
epochs: 0.20008042990698388
batch_size: 2.5922275993291755
act_fn: 46.61926797122009
optimizer: 48.155844478234236
dropout_prob: 0.7645543976398174
lr_mult: 0.0629238653975717
patience: 0.0629238653975717
batch_norm: 100.0
initialization: 43.844337411799785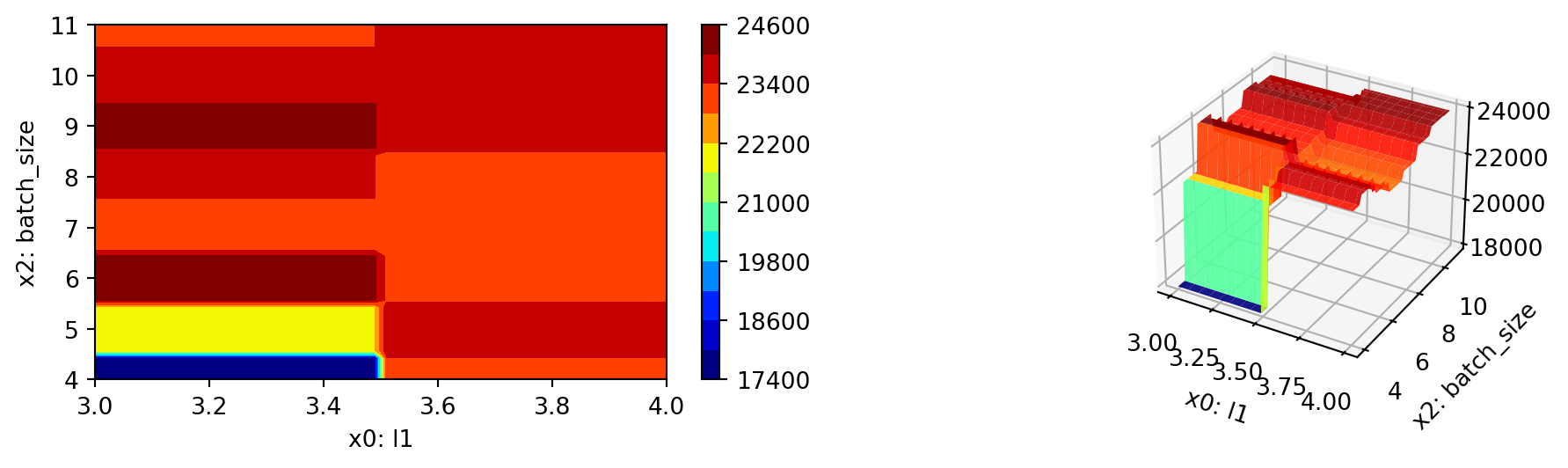
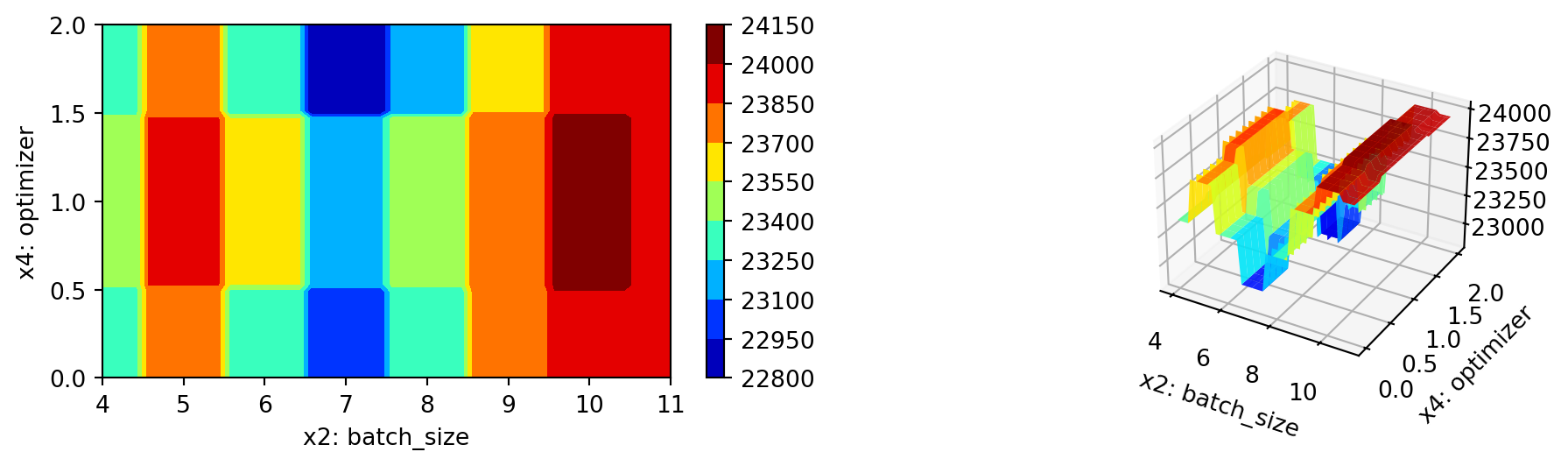
45.2.3 Get the Tuned Architecture
import pprint
from spotpython.hyperparameters.values import get_tuned_architecture
config = get_tuned_architecture(S)
pprint.pprint(config){'act_fn': Swish(),
'batch_norm': False,
'batch_size': 16,
'dropout_prob': 0.025,
'epochs': 64,
'initialization': 'xavier_normal',
'l1': 16,
'lr_mult': 5.159276791225372,
'optimizer': 'Adamax',
'patience': 8}45.2.4 Test on the full data set
# set the value of the key "TENSORBOARD_CLEAN" to True in the fun_control dictionary and use the update() method to update the fun_control dictionary
fun_control.update({"TENSORBOARD_CLEAN": True})
fun_control.update({"tensorboard_log": True})from spotpython.light.testmodel import test_model
from spotpython.utils.init import get_feature_names
test_model(config, fun_control)
get_feature_names(fun_control)┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ hp_metric │ 4396.61572265625 │ │ val_loss │ 4396.61572265625 │ └───────────────────────────┴───────────────────────────┘
test_model result: {'val_loss': 4396.61572265625, 'hp_metric': 4396.61572265625}['age',
'sex',
'bmi',
'bp',
's1_tc',
's2_ldl',
's3_hdl',
's4_tch',
's5_ltg',
's6_glu']45.3 Cross Validation With Lightning
- The
KFoldclass fromsklearn.model_selectionis used to generate the folds for cross-validation. - These mechanism is used to generate the folds for the final evaluation of the model.
- The
CrossValidationDataModuleclass [SOURCE] is used to generate the folds for the hyperparameter tuning process. - It is called from the
cv_modelfunction [SOURCE].
config{'l1': 16,
'epochs': 64,
'batch_size': 16,
'act_fn': Swish(),
'optimizer': 'Adamax',
'dropout_prob': 0.025,
'lr_mult': 5.159276791225372,
'patience': 8,
'batch_norm': False,
'initialization': 'xavier_normal'}from spotpython.light.cvmodel import cv_model
fun_control.update({"k_folds": 2})
fun_control.update({"test_size": 0.6})
cv_model(config, fun_control)k: 0┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 4136.17431640625, 'hp_metric': 4136.17431640625}
k: 1┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ layers │ Sequential │ 202 K │ train │ 6.5 M │ [16, 10] │ [16, 1] │ └───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 202 K Non-trainable params: 0 Total params: 202 K Total estimated model params size (MB): 0 Modules in train mode: 17 Modules in eval mode: 0 Total FLOPs: 6.5 M
train_model result: {'val_loss': 3132.096923828125, 'hp_metric': 3132.096923828125}3634.135620117187545.4 Extending the Basic Setup
This basic setup can be adapted to user-specific needs in many ways. For example, the user can specify a custom data set, a custom model, or a custom loss function. The following sections provide more details on how to customize the hyperparameter tuning process. Before we proceed, we will provide an overview of the basic settings of the hyperparameter tuning process and explain the parameters used so far.
45.4.1 General Experiment Setup
To keep track of the different experiments, we use a PREFIX for the experiment name. The PREFIX is used to create a unique experiment name. The PREFIX is also used to create a unique TensorBoard folder, which is used to store the TensorBoard log files.
spotpython allows the specification of two different types of stopping criteria: first, the number of function evaluations (fun_evals), and second, the maximum run time in seconds (max_time). Here, we will set the number of function evaluations to infinity and the maximum run time to one minute.
max_time is set to one minute for demonstration purposes. For real experiments, this value should be increased. Note, the total run time may exceed the specified max_time, because the initial design is always evaluated, even if this takes longer than max_time.
45.4.2 Data Setup
Here, we have provided the Diabetes data set class, which is a subclass of torch.utils.data.Dataset. Data preprocessing is handled by Lightning and PyTorch. It is described in the LIGHTNINGDATAMODULE documentation.
The data splitting, i.e., the generation of training, validation, and testing data, is handled by Lightning.
45.4.3 Objective Function fun
The objective function fun from the class HyperLight [SOURCE] is selected next. It implements an interface from PyTorch’s training, validation, and testing methods to spotpython.
45.4.4 Core-Model Setup
By using core_model_name = "light.regression.NNLinearRegressor", the spotpython model class NetLightRegression [SOURCE] from the light.regression module is selected.
45.4.5 Hyperdict Setup
For a given core_model_name, the corresponding hyperparameters are automatically loaded from the associated dictionary, which is stored as a JSON file. The JSON file contains hyperparameter type information, names, and bounds. For spotpython models, the hyperparameters are stored in the LightHyperDict, see [SOURCE] Alternatively, you can load a local hyper_dict. The hyperdict uses the default hyperparameter settings. These can be modified as described in Section 12.19.1.
45.4.6 Other Settings
There are several additional parameters that can be specified, e.g., since we did not specify a loss function, mean_squared_error is used, which is the default loss function. These will be explained in more detail in the following sections.
45.5 Tensorboard
The textual output shown in the console (or code cell) can be visualized with Tensorboard, if the argument tensorboard_log to fun_control_init() is set to True. The Tensorboard log files are stored in the runs folder. To start Tensorboard, run the following command in the terminal:
tensorboard --logdir="runs/"Further information can be found in the PyTorch Lightning documentation for Tensorboard.
45.6 Loading the Saved Experiment and Getting the Hyperparameters of the Tuned Model
To get the tuned hyperparameters as a dictionary, the get_tuned_architecture function can be used.
from spotpython.utils.file import load_result
spot_tuner = load_result(PREFIX=PREFIX)
config = get_tuned_architecture(spot_tuner)
configLoaded experiment from 601_res.pkl{'l1': 16,
'epochs': 64,
'batch_size': 16,
'act_fn': Swish(),
'optimizer': 'Adamax',
'dropout_prob': 0.025,
'lr_mult': 5.159276791225372,
'patience': 8,
'batch_norm': False,
'initialization': 'xavier_normal'}45.7 Using the spotgui
The spotgui [github] provides a convenient way to interact with the hyperparameter tuning process. To obtain the settings from Section 45.1, the spotgui can be started as shown in Figure 46.1.
45.8 Summary
This section presented an introduction to the basic setup of hyperparameter tuning with spotpython and PyTorch Lightning.