58Hyperparameter Tuning with spotpython and PyTorch Lightning for the Diabetes Data Set Using a ResNet Model
In this section, we will show how spotpython can be integrated into the PyTorch Lightning training workflow for a regression task. It demonstrates how easy it is to use spotpython to tune hyperparameters for a PyTorch Lightning model.
After importing the necessary libraries, the fun_control dictionary is set up via the fun_control_init function. The fun_control dictionary contains
PREFIX: a unique identifier for the experiment
fun_evals: the number of function evaluations
max_time: the maximum run time in minutes
data_set: the data set. Here we use the Diabetes data set that is provided by spotpython.
core_model_name: the class name of the neural network model. This neural network model is provided by spotpython.
hyperdict: the hyperparameter dictionary. This dictionary is used to define the hyperparameters of the neural network model. It is also provided by spotpython.
_L_in: the number of input features. Since the Diabetes data set has 10 features, _L_in is set to 10.
_L_out: the number of output features. Since we want to predict a single value, _L_out is set to 1.
The HyperLight class is used to define the objective function fun. It connects the PyTorch and the spotpython methods and is provided by spotpython.
Note, the divergence_threshold is set to 5,000, which is based on some pre-experiments with the Diabetes data set.
The method set_hyperparameter allows the user to modify default hyperparameter settings. Here we modify some hyperparameters to keep the model small and to decrease the tuning time.
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 95.7 K │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴───────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 95.7 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 310 K │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 310 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 1.2 M │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 1.2 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 38.8 K │ [16, 10] │ [16, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 38.8 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 2.5 M │ [1024, 10] │ [1024, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 2.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 191 K │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 191 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 382 K │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 382 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 23.9 K │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 23.9 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 155 K │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 155 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 77.7 K │ [32, 10] │ [32, 1] │
└───┴────────┴────────────┴────────┴───────┴────────┴──────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 77.7 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 382 K │ [512, 10] │ [512, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 382 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 155 K │ [64, 10] │ [64, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 155 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 2.5 M │ [1024, 10] │ [1024, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 2.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 621 K │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 621 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 621 K │ [256, 10] │ [256, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 621 K
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 1.8 K │ train │ 310 K │ [128, 10] │ [128, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴───────────┴───────────┘
Trainable params: 1.8 K
Non-trainable params: 0
Total params: 1.8 K
Total estimated model params size (MB): 0
Modules in train mode: 101
Modules in eval mode: 0
Total FLOPs: 310 K
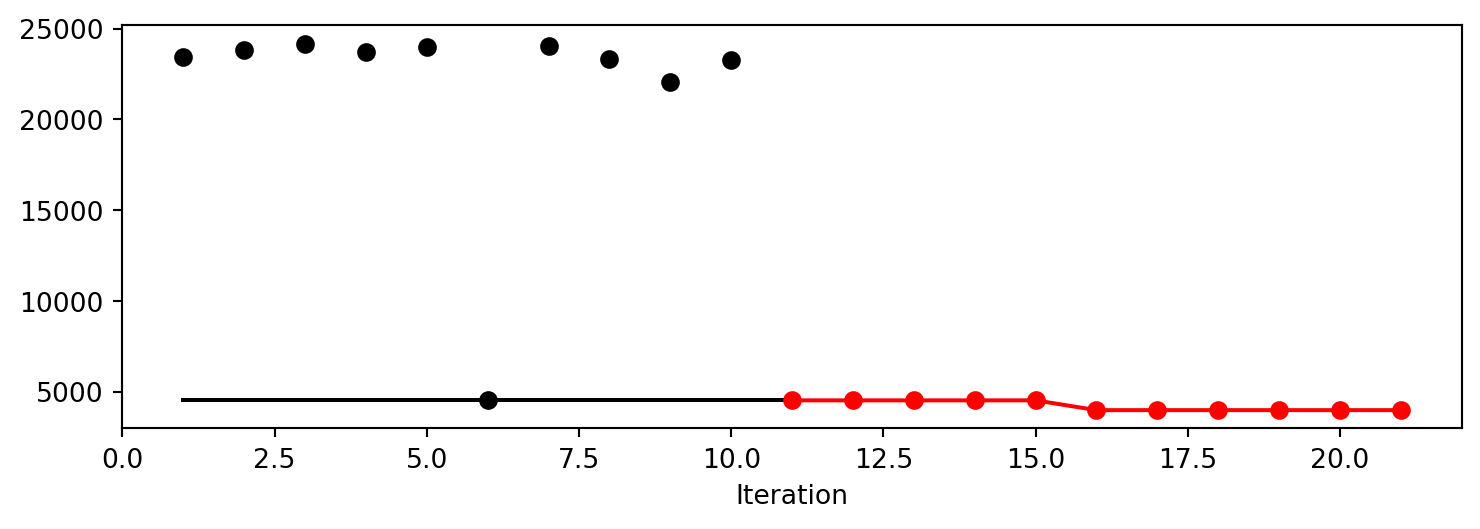
After the hyperparameter tuning run is finished, the progress of the hyperparameter tuning can be visualized with spotpython’s method plot_progress. The black points represent the performace values (score or metric) of hyperparameter configurations from the initial design, whereas the red points represents the hyperparameter configurations found by the surrogate model based optimization.
spot_tuner.plot_progress()
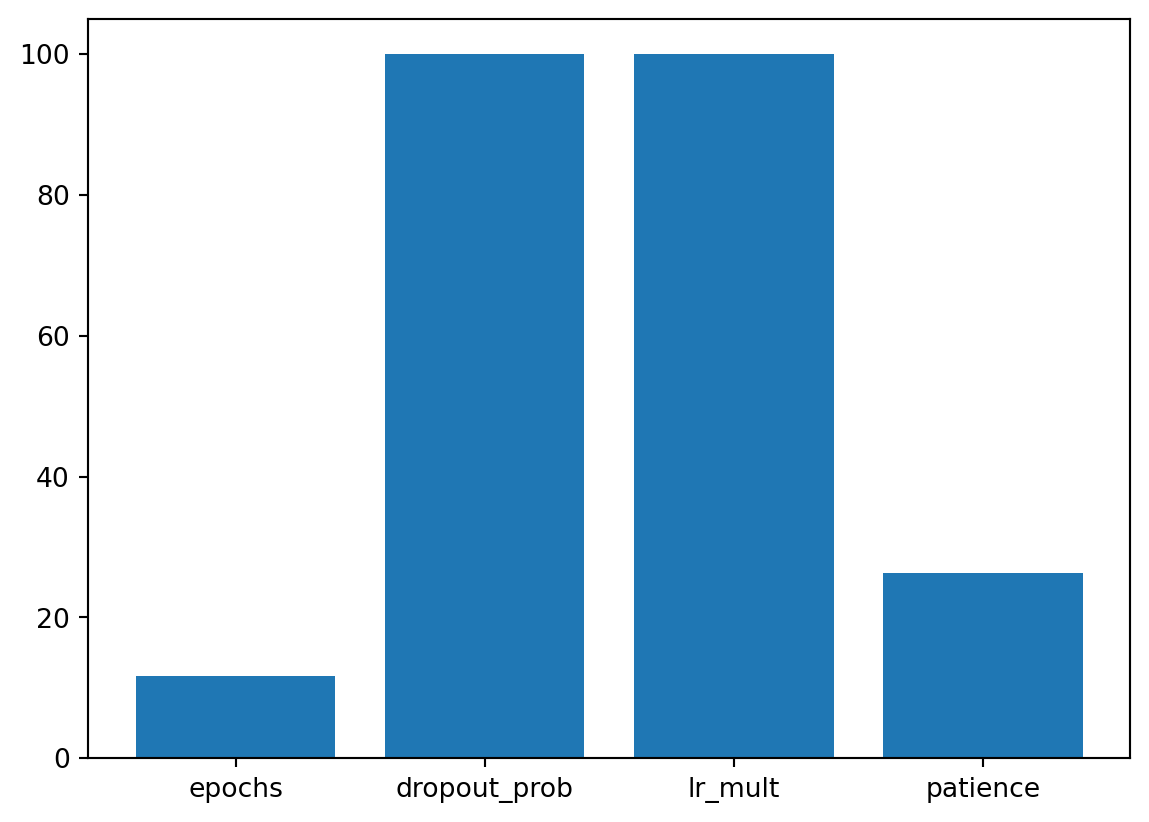
58.1.2 Tuned Hyperparameters and Their Importance
Results can be printed in tabular form.
from spotpython.utils.eda import print_res_tableprint_res_table(spot_tuner)
# set the value of the key "TENSORBOARD_CLEAN" to True in the fun_control dictionary and use the update() method to update the fun_control dictionaryimport os# if the directory "./runs" exists, delete itif os.path.exists("./runs"): os.system("rm -r ./runs")fun_control.update({"tensorboard_log": True})
from spotpython.light.testmodel import test_modelfrom spotpython.utils.init import get_feature_namestest_model(config, fun_control)get_feature_names(fun_control)
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
from spotpython.light.cvmodel import cv_modelfun_control.update({"k_folds": 2})fun_control.update({"test_size": 0.6})cv_model(config, fun_control)
k: 0
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
┏━━━┳━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━┓
┃┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃
┡━━━╇━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ layers │ Sequential │ 637 │ train │ 1.5 M │ [2048, 10] │ [2048, 1] │
└───┴────────┴────────────┴────────┴───────┴───────┴────────────┴───────────┘
Trainable params: 637
Non-trainable params: 0
Total params: 637
Total estimated model params size (MB): 0
Modules in train mode: 63
Modules in eval mode: 0
Total FLOPs: 1.5 M
This section presented an introduction to the basic setup of hyperparameter tuning with spotpython and PyTorch Lightning using a ResNet model for the Diabetes data set.