import numpy as np
from math import inf
from spotpython.fun.objectivefunctions import Analytical
from spotpython.utils.init import fun_control_init, design_control_init
from spotpython.hyperparameters.values import set_control_key_value
from spotpython.spot import Spot
import matplotlib.pyplot as plt7 Introduction to spotpython
Surrogate model based optimization methods are common approaches in simulation and optimization. SPOT was developed because there is a great need for sound statistical analysis of simulation and optimization algorithms. SPOT includes methods for tuning based on classical regression and analysis of variance techniques. It presents tree-based models such as classification and regression trees and random forests as well as Bayesian optimization (Gaussian process models, also known as Kriging). Combinations of different meta-modeling approaches are possible. SPOT comes with a sophisticated surrogate model based optimization method, that can handle discrete and continuous inputs. Furthermore, any model implemented in scikit-learn can be used out-of-the-box as a surrogate in spotpython.
SPOT implements key techniques such as exploratory fitness landscape analysis and sensitivity analysis. It can be used to understand the performance of various algorithms, while simultaneously giving insights into their algorithmic behavior.
The spot loop consists of the following steps:
- Init: Build initial design \(X\)
- Evaluate initial design on real objective \(f\): \(y = f(X)\)
- Build surrogate: \(S = S(X,y)\)
- Optimize on surrogate: \(X_0 = \text{optimize}(S)\)
- Evaluate on real objective: \(y_0 = f(X_0)\)
- Impute (Infill) new points: \(X = X \cup X_0\), \(y = y \cup y_0\).
- Goto 3.
7.1 Advantages of the spotpython approach
Neural networks and many ML algorithms are non-deterministic, so results are noisy (i.e., depend on the the initialization of the weights). Enhanced noise handling strategies, OCBA (description from HPT-book).
Optimal Computational Budget Allocation (OCBA) is a very efficient solution to solve the “general ranking and selection problem” if the objective function is noisy. It allocates function evaluations in an uneven manner to identify the best solutions and to reduce the total optimization costs. [Chen10a, Bart11b] Given a total number of optimization samples \(N\) to be allocated to \(k\) competing solutions whose performance is depicted by random variables with means \(\bar{y}_i\) (\(i=1, 2, \ldots, k\)), and finite variances \(\sigma_i^2\), respectively, as \(N \to \infty\), the can be asymptotically maximized when \[\begin{align} \frac{N_i}{N_j} & = \left( \frac{ \sigma_i / \delta_{b,i}}{\sigma_j/ \delta_{b,j}} \right)^2, i,j \in \{ 1, 2, \ldots, k\}, \text{ and } i \neq j \neq b,\\ N_b &= \sigma_b \sqrt{ \sum_{i=1, i\neq b}^k \frac{N_i^2}{\sigma_i^2} }, \end{align}\] where \(N_i\) is the number of replications allocated to solution \(i\), \(\delta_{b,i} = \bar{y}_b - \bar{y}_i\), and \(\bar{y}_b \leq \min_{i\neq b} \bar{y}_i\) Bartz-Beielstein and Friese (2011).
Surrogate-based optimization: Better than grid search and random search (Reference to HPT-book)
Visualization
Importance based on the Kriging model
Sensitivity analysis. Exploratory fitness landscape analysis. Provides XAI methods (feature importance, integrated gradients, etc.)
Uncertainty quantification
Flexible, modular meta-modeling handling. spotpython come with a Kriging model, which can be replaced by any model implemented in
scikit-learn.Enhanced metric handling, especially for categorical hyperparameters (any sklearn metric can be used). Default is..
Integration with TensorBoard: Visualization of the hyperparameter tuning process, of the training steps, the model graph. Parallel coordinates plot, scatter plot matrix, and more.
Reproducibility. Results are stored as pickle files. The results can be loaded and visualized at any time and be transferred between different machines and operating systems.
Handles scikit-learn models and pytorch models out-of-the-box. The user has to add a simple wrapper for passing the hyperparemeters to use a pytorch model in spotpython.
Compatible with Lightning.
User can add own models as plain python code.
User can add own data sets in various formats.
Flexible data handling and data preprocessing.
Many examples online (hyperparameter-tuning-cookbook).
spotpython uses a robust optimizer that can even deal with hyperparameter-settings that cause crashes of the algorithms to be tuned.
even if the optimum is not found, HPT with spotpython prevents the user from choosing bad hyperparameters in a systematic way (design of experiments).
7.2 Disadvantages of the spotpython approach
- Time consuming
- Surrogate can be misguiding
- no parallelization implement yet
Central Idea: Evaluation of the surrogate model S is much cheaper (or / and much faster) than running the real-world experiment \(f\). We start with a small example.
7.3 Example: Spot and the Sphere Function
7.3.1 The Objective Function: Sphere
The spotpython package provides several classes of objective functions. We will use an analytical objective function, i.e., a function that can be described by a (closed) formula: \[
f(x) = x^2
\]
fun = Analytical().fun_sphereWe can apply the function fun to input values and plot the result:
x = np.linspace(-1,1,100).reshape(-1,1)
y = fun(x)
plt.figure()
plt.plot(x, y, "k")
plt.show()
7.3.2 The Spot Method as an Optimization Algorithm Using a Surrogate Model
We initialize the fun_control dictionary. The fun_control dictionary contains the parameters for the objective function. The fun_control dictionary is passed to the Spot method.
fun_control=fun_control_init(lower = np.array([-1]),
upper = np.array([1]))
spot_0 = Spot(fun=fun,
fun_control=fun_control)
spot_0.run()spotpython tuning: 6.690918515799129e-09 [#######---] 73.33%
spotpython tuning: 6.719979618922052e-11 [########--] 80.00%
spotpython tuning: 6.719979618922052e-11 [#########-] 86.67%
spotpython tuning: 6.719979618922052e-11 [#########-] 93.33%
spotpython tuning: 6.719979618922052e-11 [##########] 100.00% Done...
Experiment saved to 000_res.pkl<spotpython.spot.spot.Spot at 0x159eb6630>The method print_results() prints the results, i.e., the best objective function value (“min y”) and the corresponding input value (“x0”).
spot_0.print_results()min y: 6.719979618922052e-11
x0: 8.197548181573593e-06[['x0', np.float64(8.197548181573593e-06)]]To plot the search progress, the method plot_progress() can be used. The parameter log_y is used to plot the objective function values on a logarithmic scale.
spot_0.plot_progress(log_y=True)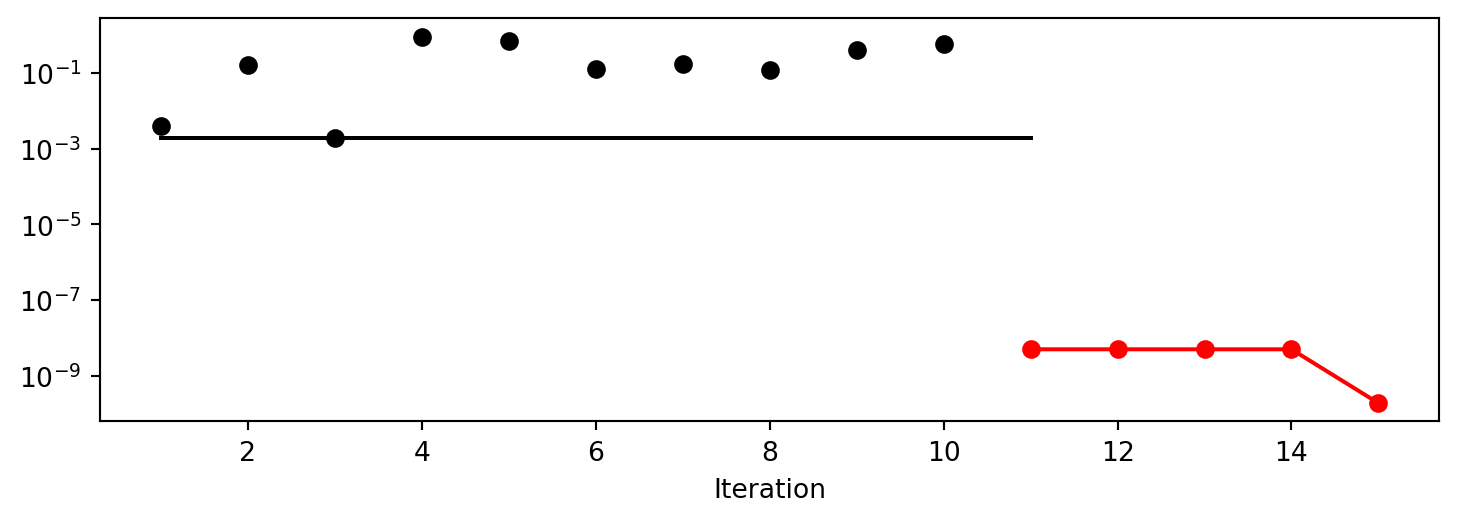
Spot method. The black elements (points and line) represent the initial design, before the surrogate is build. The red elements represent the search on the surrogate.
If the dimension of the input space is one, the method plot_model() can be used to visualize the model and the underlying objective function values.
spot_0.plot_model()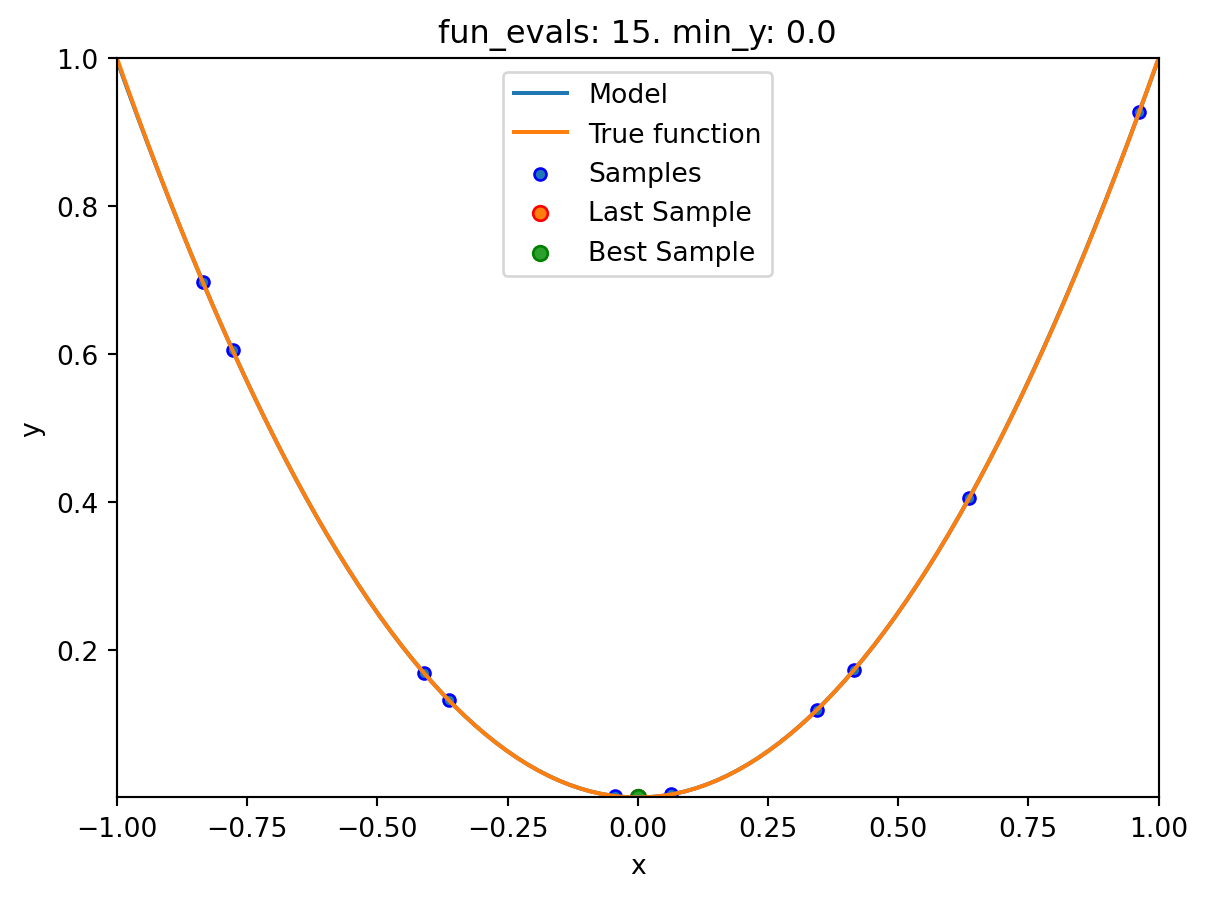
7.4 Spot Parameters: fun_evals, init_size and show_models
We will modify three parameters:
- The number of function evaluations (
fun_evals) will be set to10(instead of 15, which is the default value) in thefun_controldictionary. - The parameter
show_models, which visualizes the search process for each single iteration for 1-dim functions, in thefun_controldictionary. - The size of the initial design (
init_size) in thedesign_controldictionary.
The full list of the Spot parameters is shown in code reference on GitHub, see Spot.
fun_control=fun_control_init(lower = np.array([-1]),
upper = np.array([1]),
fun_evals = 10,
show_models = True)
design_control = design_control_init(init_size=9)
spot_1 = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control)
spot_1.run()
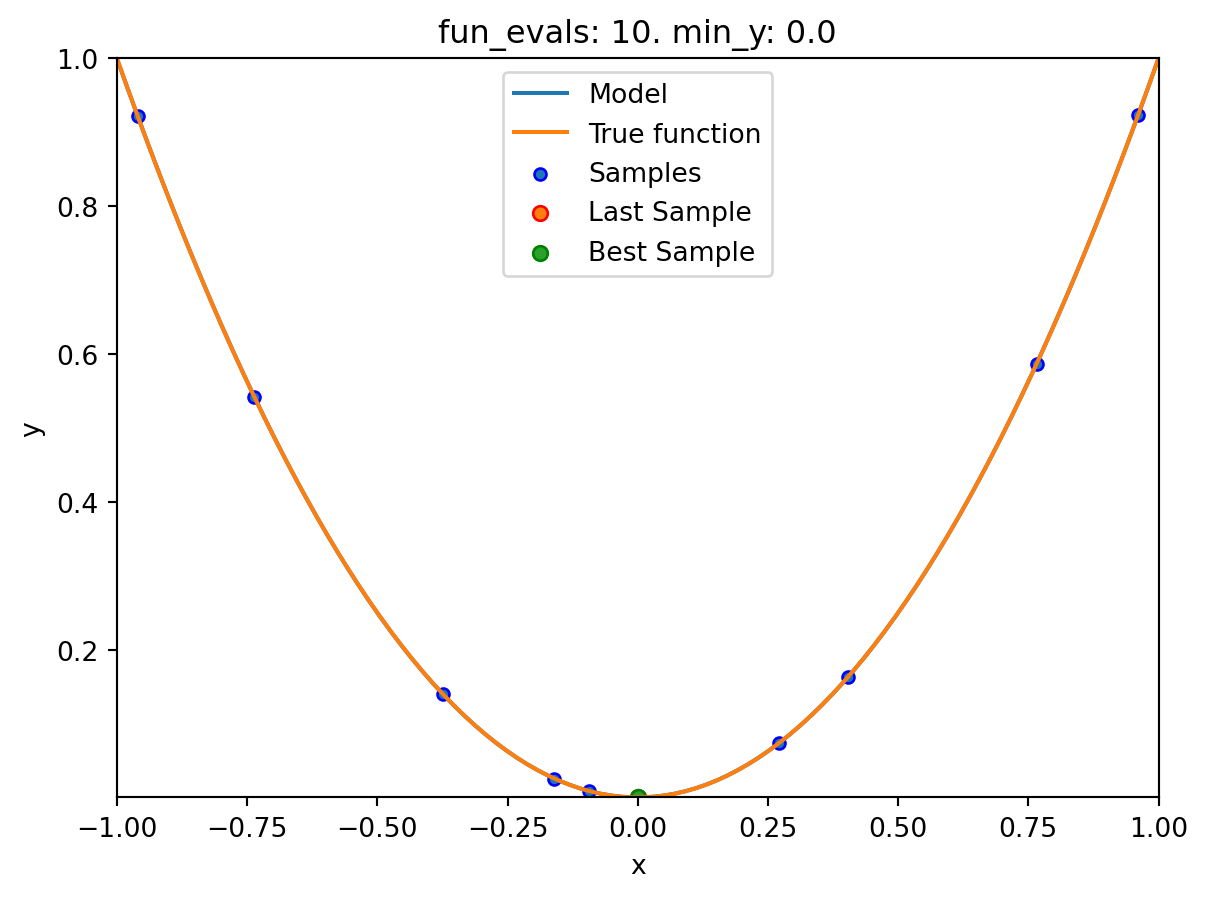
spotpython tuning: 9.7097578737121e-06 [##########] 100.00% Done...
Experiment saved to 000_res.pkl7.5 Print the Results
spot_1.print_results()min y: 9.7097578737121e-06
x0: 0.0031160484389226206[['x0', np.float64(0.0031160484389226206)]]7.6 Show the Progress
spot_1.plot_progress()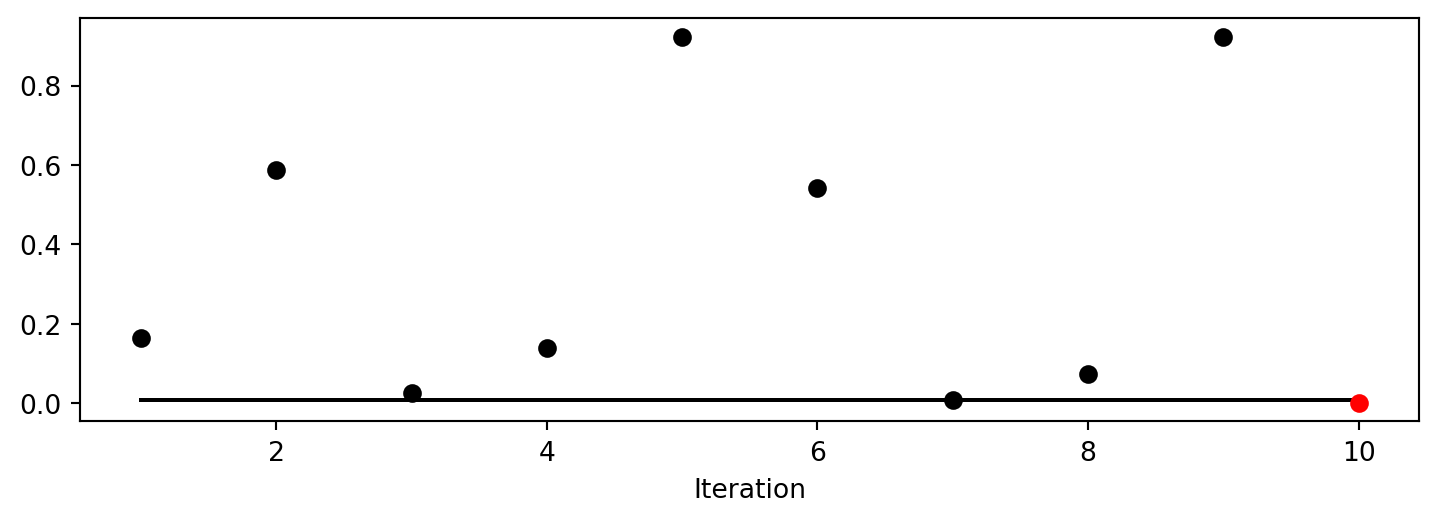
7.7 Visualizing the Optimization and Hyperparameter Tuning Process with TensorBoard
spotpython supports the visualization of the hyperparameter tuning process with TensorBoard. The following example shows how to use TensorBoard with spotpython.
First, we define an “PREFIX” to identify the hyperparameter tuning process. The PREFIX is used to create a directory for the TensorBoard files.
fun_control = fun_control_init(
PREFIX = "01",
lower = np.array([-1]),
upper = np.array([2]),
fun_evals=100,
TENSORBOARD_CLEAN=True,
tensorboard_log=True)
design_control = design_control_init(init_size=5)Moving TENSORBOARD_PATH: runs/ to TENSORBOARD_PATH_OLD: runs_OLD/runs_2025_05_12_22_08_30_0
Created spot_tensorboard_path: runs/spot_logs/01_maans08_2025-05-12_22-08-30 for SummaryWriter()Since the tensorboard_log is True, spotpython will log the optimization process in the TensorBoard files. The argument TENSORBOARD_CLEAN=True will move the TensorBoard files from the previous run to a backup folder, so that TensorBoard files from previous runs are not overwritten and a clean start in the runs folder is guaranteed.
spot_tuner = Spot(fun=fun,
fun_control=fun_control,
design_control=design_control)
spot_tuner.run()
spot_tuner.print_results()spotpython tuning: 0.0005401959712392311 [#---------] 6.00%
spotpython tuning: 0.00017194734221844825 [#---------] 7.00%
spotpython tuning: 0.00012951639447619488 [#---------] 8.00%
spotpython tuning: 0.00011593270967604635 [#---------] 9.00%
spotpython tuning: 8.960832462042882e-05 [#---------] 10.00%
spotpython tuning: 1.1087652041635331e-05 [#---------] 11.00%
spotpython tuning: 1.5733042163261654e-06 [#---------] 12.00%
spotpython tuning: 1.1001891458836728e-08 [#---------] 13.00%
spotpython tuning: 1.1001891458836728e-08 [#---------] 14.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 15.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 16.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 17.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 18.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 19.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 20.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 21.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 22.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 23.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 24.00%
spotpython tuning: 1.1001891458836728e-08 [##--------] 25.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 26.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 27.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 28.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 29.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 30.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 31.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 32.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 33.00%
spotpython tuning: 1.1001891458836728e-08 [###-------] 34.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 35.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 36.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 37.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 38.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 39.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 40.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 41.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 42.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 43.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 44.00%
spotpython tuning: 1.1001891458836728e-08 [####------] 45.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 46.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 47.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 48.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 49.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 50.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 51.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 52.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 53.00%
spotpython tuning: 1.1001891458836728e-08 [#####-----] 54.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 55.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 56.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 57.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 58.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 59.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 60.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 61.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 62.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 63.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 64.00%
spotpython tuning: 1.1001891458836728e-08 [######----] 65.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 66.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 67.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 68.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 69.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 70.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 71.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 72.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 73.00%
spotpython tuning: 1.1001891458836728e-08 [#######---] 74.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 75.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 76.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 77.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 78.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 79.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 80.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 81.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 82.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 83.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 84.00%
spotpython tuning: 1.1001891458836728e-08 [########--] 85.00%
spotpython tuning: 1.1001891458836728e-08 [#########-] 86.00%
spotpython tuning: 1.1001891458836728e-08 [#########-] 87.00%
spotpython tuning: 1.1001891458836728e-08 [#########-] 88.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 89.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 90.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 91.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 92.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 93.00%
spotpython tuning: 1.386815256673593e-09 [#########-] 94.00%
spotpython tuning: 1.386815256673593e-09 [##########] 95.00%
spotpython tuning: 1.386815256673593e-09 [##########] 96.00%
spotpython tuning: 1.386815256673593e-09 [##########] 97.00%
spotpython tuning: 3.952064321854671e-11 [##########] 98.00%
spotpython tuning: 3.952064321854671e-11 [##########] 99.00%
spotpython tuning: 3.952064321854671e-11 [##########] 100.00% Done...
Experiment saved to 01_res.pkl
min y: 3.952064321854671e-11
x0: -6.2865446167625905e-06[['x0', np.float64(-6.2865446167625905e-06)]]Now we can start TensorBoard in the background. The TensorBoard process will read the TensorBoard files and visualize the hyperparameter tuning process. From the terminal, we can start TensorBoard with the following command:
tensorboard --logdir="./runs"logdir is the directory where the TensorBoard files are stored. In our case, the TensorBoard files are stored in the directory ./runs.
TensorBoard will start a web server on port 6006. We can access the TensorBoard web server with the following URL:
http://localhost:6006/The first TensorBoard visualization shows the objective function values plotted against the wall time. The wall time is the time that has passed since the start of the hyperparameter tuning process. The five initial design points are shown in the upper left region of the plot. The line visualizes the optimization process. 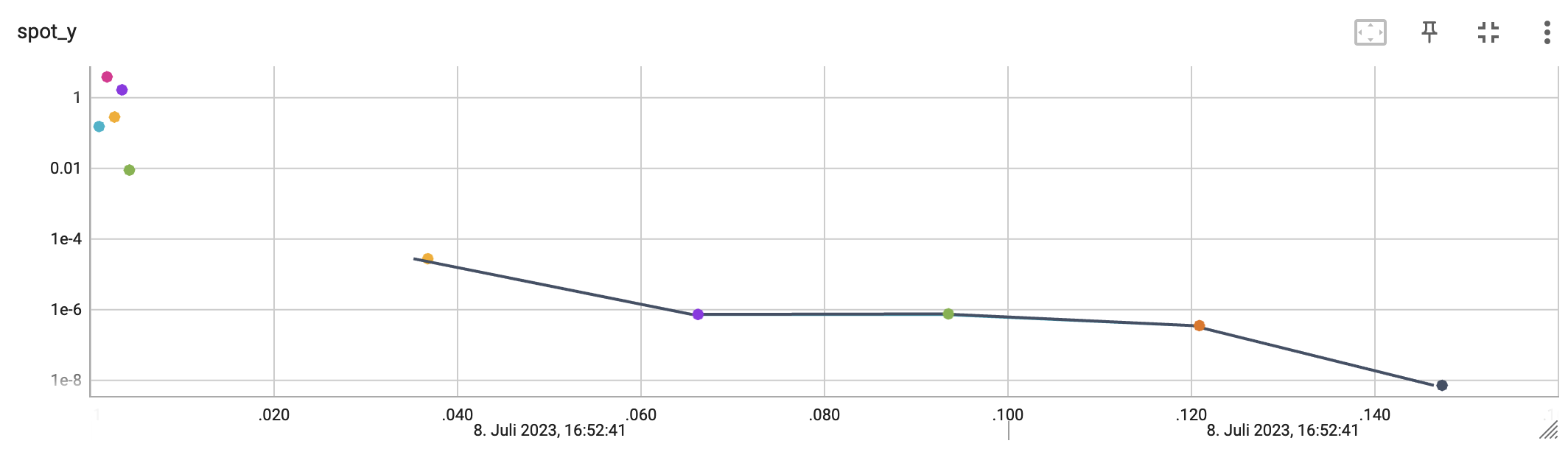
The second TensorBoard visualization shows the input values, i.e., \(x_0\), plotted against the wall time. 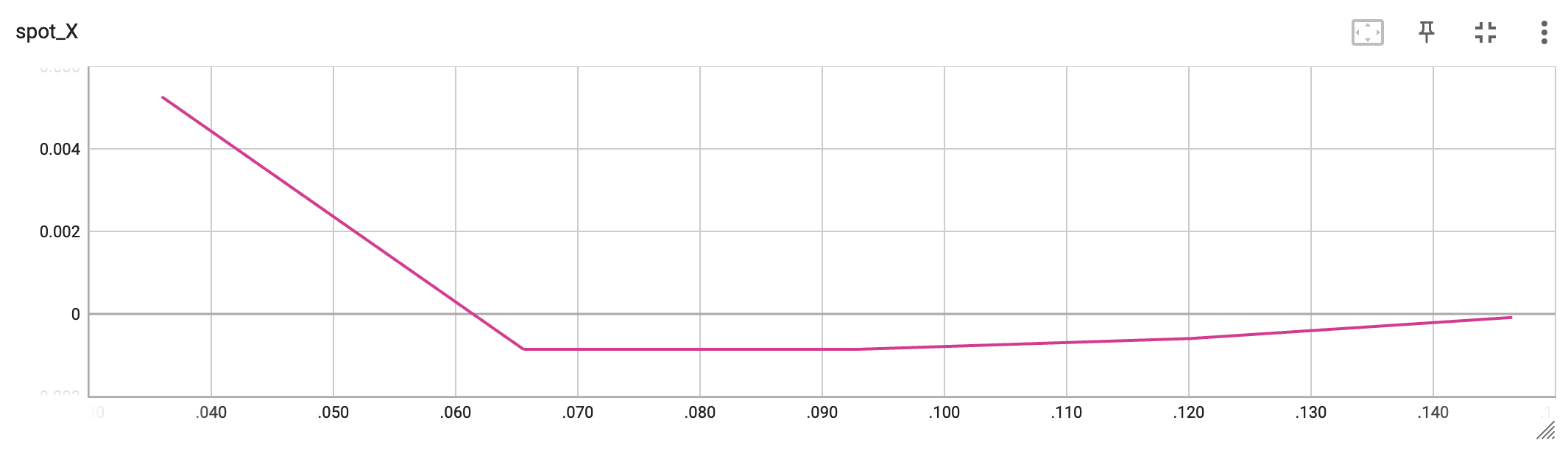
The third TensorBoard plot illustrates how spotpython can be used as a microscope for the internal mechanisms of the surrogate-based optimization process. Here, one important parameter, the learning rate \(\theta\) of the Kriging surrogate is plotted against the number of optimization steps.

7.8 Jupyter Notebook
Note
- The Jupyter-Notebook of this lecture is available on GitHub in the Hyperparameter-Tuning-Cookbook Repository