Exercise 18.61 (RegressionVsClassification) What is the difference between regression and classification?
18.1.5 Maximum Likelihood
Maximum likelihood estimation is a method used to estimate the parameters of a statistical model. It is based on the principle of choosing the parameter values that maximize the likelihood of the observed data. The likelihood function represents the probability of observing the data given the model parameters. By maximizing this likelihood, we can find the parameter values that best explain the observed data.
Example 18.1 (Maximum Likelihood Estimation: Bernoulli Experiment) Bernoulli experiment for the event \(A\), repeated \(n\) times, with the probability of success \(p\). Result given as \(n\) tuple with entries \(A\) and \(\overline{A}\). \(A\) appears \(k\) times. The probability of this event is given by \[\begin{equation}
L(p) = p^k (1-p)^{n-k}
\end{equation}\] Applying maximum likelihood estimation, we find the maximum of the likelihood function \(L(p)\), i.e., we are trying to find the value of \(p\) that maximizes the probability of observing the data. This value will be denoted as \(\hat{p}\).
Differentiating the likelihood function with respect to \(p\) and setting the derivative to zero, we find the maximum likelihood estimate \(\hat{p}\). We get \[\begin{align}
\frac{d}{dp} L(p) & = k p^{k-1} (1-p)^{n-k} - p^k (n-k) (1-p)^{n-k-1}\\
& = p^{k-1} (1-p)^{n-k-1} \left(k(1-p) - p(n-k)\right) = 0
\end{align}\]
Because \[
p \neq 0 \text{ and } (1-p) p \neq 0,
\] we can divide by \(p^{k-1} (1-p)^{n-k-1}\) and get \[\begin{equation}
k(1-p) - p(n-k) = 0.
\end{equation}\] Solving for \(p\) gives \[\begin{equation}
\hat{p} = \frac{k}{n}
\end{equation}\]
Therefore, the maximum likelihood estimate for the probability of success in a Bernoulli experiment is the ratio of the number of successes to the total number of trials.
\(\Box\)
Example 18.2 (Maximum Likelihood Estimation: Normal Distribution) Random variable \(X \sim \mathcal{N}(\mu, \sigma^2)\) with \(n\) observations \(x_1, x_2, \ldots, x_n\). The likelihood function is given by \[\begin{equation}
L(x_1, x_2, \ldots, x_n, \mu, \sigma^2) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi \sigma^2}} \exp\left(-\frac{(x_i - \mu)^2}{2\sigma^2}\right)
\end{equation}\]
Taking the logarithm of the likelihood function, we get \[\begin{equation}
\log L(x_1, x_2, \ldots, x_n, \mu, \sigma^2) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i - \mu)^2
\end{equation}\]
Partial derivative with respect to \(\mu\) is \[\begin{align}
\frac{\partial}{\partial \mu} \log L(x_1, x_2, \ldots, x_n, \mu, \sigma^2) & = \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \mu) = 0
\end{align}\] We obtain the maximum likelihood estimate for \(\mu\) as \[\begin{equation}
\hat{\mu} = \frac{1}{n} \sum_{i=1}^n x_i
\end{equation}\]
The partial derivative with respect to \(\sigma^2\) is \[\begin{align}
\frac{\partial}{\partial \sigma^2} \log L(x_1, x_2, \ldots, x_n, \mu, \sigma^2) & = -\frac{n}{2\sigma^2} + \frac{1}{2(\sigma^2)^2} \sum_{i=1}^n (x_i - \mu)^2 = 0
\end{align}\] This can be simplified to \[\begin{align}
-n + \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \mu)^2 = 0\\
\Rightarrow n \sigma^2 = \sum_{i=1}^n (x_i - \mu)^2
\end{align}\] Using the maximum likelihood estimate for \(\mu\), we get \[\begin{equation}
\hat{\sigma}^2 = \frac{1}{n} \sum_{i=1}^n (x_i - \hat{\mu})^2
\end{equation}\]\[\begin{equation}
= \frac{n-1}{n} \frac{\sum_{i=1}^n (x_i - \hat{\mu})^2{n-1}} = \frac{n-1}{n} s^2,
\end{equation}\] where \[\begin{equation}
s = \sqrt{\frac{\sum_{i=1}^n (x_i- \overline{x})}{n-1}}
\end{equation}\] is the sample standard deviation. We obtain the maximum likelihood estimate for \(\sigma^2\) as \[\begin{equation}
\hat{\sigma}^2 = \frac{n-1}{n} s^2
\end{equation}\]
Parts of this course are based on the book An Introduction to Statistical Learning, James et al. (2014). Some of the figures in this presentation are taken from An Introduction to Statistical Learning (Springer, 2013) with permission from the authors: G. James, D. Witten, T. Hastie and R. Tibshirani.
18.2.1 Opening Remarks and Examples
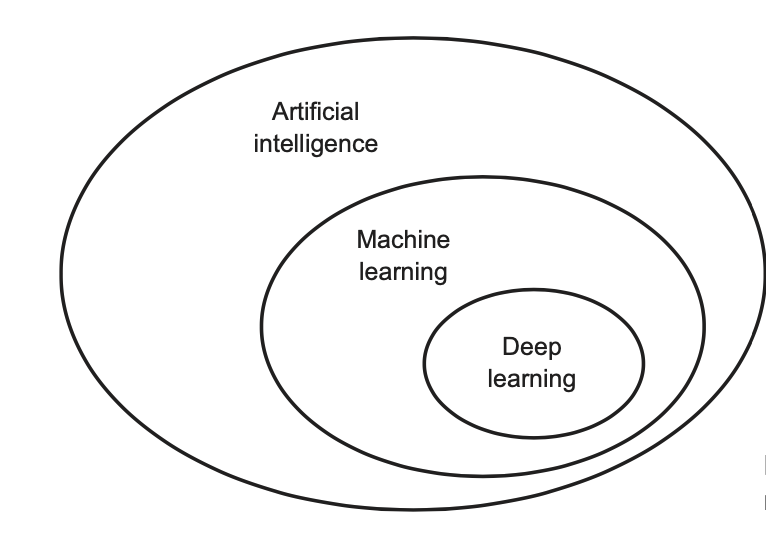
Artificial Intelligence (AI)
Machine learning (ML)
Deep Learning (DL)
AI, ML, and DL. Taken fron Chollet and Allaire (2018)
1980’s neural networks.
Statistical learning.
IBM Watson supercomputer.
Statistical learning problems include:
Identification of prostate cancer through PSA and other measurements such as age, Gleason score, etc. Scatter plots help reveal the nature of the data and its correlations. Using transformed data (log scale) can highlight typos in the data; for example, a patient with a 449-gram prostate. Recommendation: Always examine the data before conducting any sophisticated analysis.
Classification of phonemes, specifically between “aa” and “ao.”
Prediction of heart attacks, which can be visualized through colored scatter plots.
Detection of email spam, based on the frequency of words within the messages, using 57 features.
Identification of numbers in handwritten zip codes, which involves pattern recognition.
Classification of tissue samples into cancer classes based on gene expression profiles, utilizing heat maps for visualization.
Establishing the relationship between salary and demographic variables like income (wage) versus age, year, and education level, employing regression models.
Classification of pixels in LANDSAT images by their usage, using nearest neighbor methods.
18.2.1.1 Supervised and Unsupervised Learning
Two important types: supervised and unsupervised learning. There is even more, e.g., semi-supervised learning.
Training data \((x_1, y1), \ldots ,(x_N, y_N)\). These are observations (examples, instances) of these measurements.
In the regression problem, \(Y\) is quantitative (e.g., price, blood pressure). In the classification problem, \(Y\) takes values in a finite, unordered set (e.g., survived/died, digit 0-9, cancer class of tissue sample).
18.2.1.1.2 Philosophy
It is important to understand the ideas behind the various techniques, in order to know how and when to use them. One has to understand the simpler methods first, in order to grasp the more sophisticated ones. It is important to accurately assess the performance of a method, to know how well or how badly it is working (simpler methods often perform as well as fancier ones!) This is an exciting research area, having important applications in science, industry and finance. Statistical learning is a fundamental ingredient in the training of a modern data scientist.
18.3 Basics
18.3.1 Histograms
Creating a histogram and calculating the probabilities from a dataset can be approached with scientific precision
Data Collection: Obtain the dataset you wish to analyze. This dataset could represent any quantitative measure, such to examine its distribution.
Decide on the Number of Bins: The number of bins influences the histogram’s granularity. There are several statistical rules to determine an optimal number of bins:
Square-root rule: suggests using the square root of the number of data points as the number of bins.
Sturges’ formula: \(k = 1 + 3.322 \log_{10}(n)\), where \(n\) is the number of data points and \(k\) is the suggested number of bins.
Freedman-Diaconis rule: uses the interquartile range (IQR) and the cube root of the number of data points \(n\) to calculate bin width as \(2 \dfrac{IQR}{n^{1/3}}\).
Determine Range and Bin Width: Calculate the range of data by subtracting the minimum data point value from the maximum. Divide this range by the number of bins to determine the width of each bin.
Allocate Data Points to Bins: Iterate through the data, sorting each data point into the appropriate bin based on its value.
Draw the Histogram: Use a histogram to visualize the frequency or relative frequency (probability) of data points within each bin.
Calculate Probabilities: The relative frequency of data within each bin represents the probability of a randomly selected data point falling within that bin’s range.
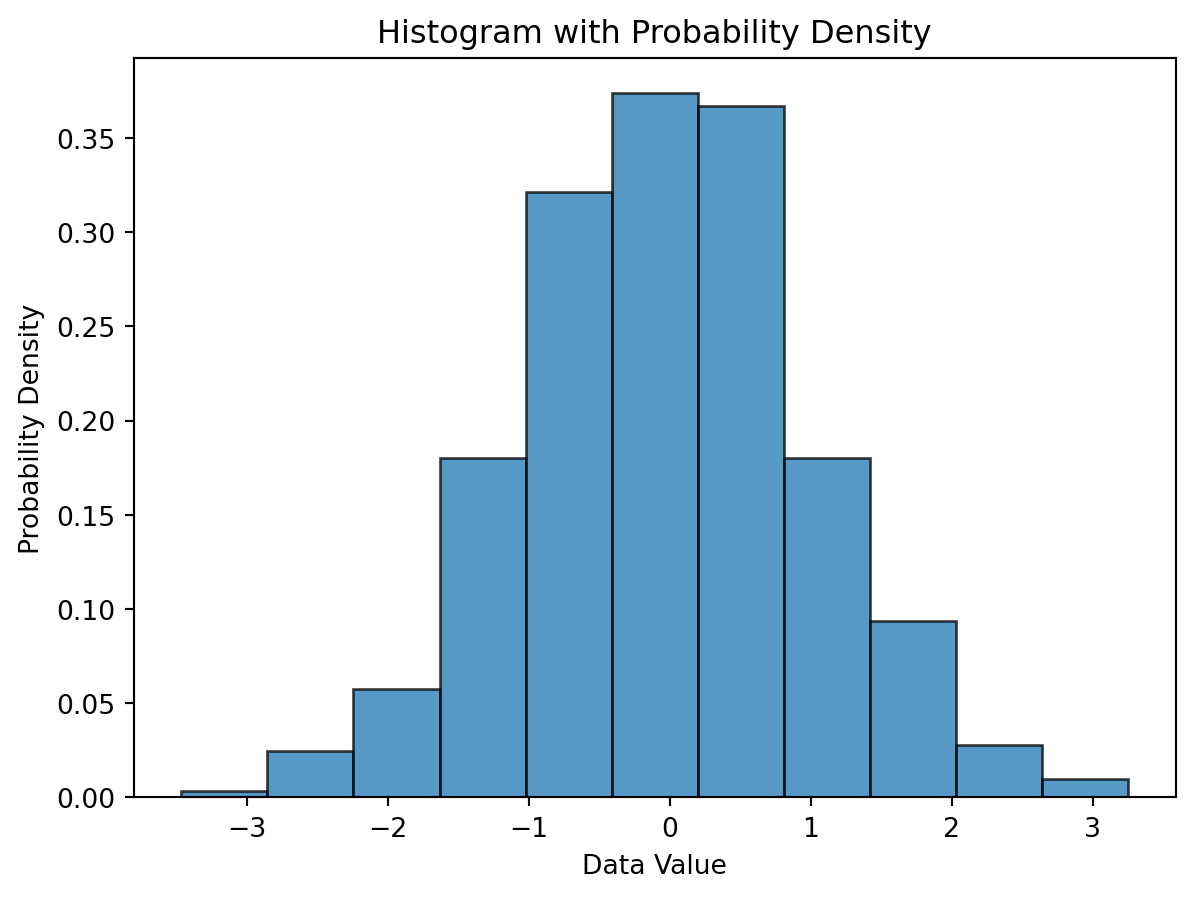
Below is a Python script that demonstrates how to generate a histogram and compute probabilities using the matplotlib library for visualization and numpy for data manipulation.
import numpy as npimport matplotlib.pyplot as plt%matplotlib inline# Sample data: Randomly generated for demonstrationdata = np.random.normal(0, 1, 1000) # 1000 data points with a normal distribution# Step 2: Decide on the number of binsnum_bins =int(np.ceil(1+3.322* np.log10(len(data)))) # Sturges' formula# Step 3: Determine range and bin width -- handled internally by matplotlib# Steps 4 & 5: Sort data into bins and draw the histogramfig, ax = plt.subplots()n, bins, patches = ax.hist(data, bins=num_bins, density=True, alpha=0.75, edgecolor='black')# Calculate probabilities (relative frequencies) manually, if neededbin_width = np.diff(bins) # np.diff finds the difference between adjacent bin boundariesprobabilities = n * bin_width # n is already normalized to form a probability density if `density=True`# Adding labels and title for clarityax.set_xlabel('Data Value')ax.set_ylabel('Probability Density')ax.set_title('Histogram with Probability Density')
Text(0.5, 1.0, 'Histogram with Probability Density')
(a) Histogram with Probability Density
(b)
Figure 18.1
for i, prob inenumerate(probabilities):print(f"Bin {i+1} Probability: {prob:.4f}")# Ensure probabilities sum to 1 (or very close, due to floating-point arithmetic)print(f"Sum of probabilities: {np.sum(probabilities)}")
Bin 1 Probability: 0.0030
Bin 2 Probability: 0.0210
Bin 3 Probability: 0.0410
Bin 4 Probability: 0.1040
Bin 5 Probability: 0.1920
Bin 6 Probability: 0.2310
Bin 7 Probability: 0.2050
Bin 8 Probability: 0.1250
Bin 9 Probability: 0.0470
Bin 10 Probability: 0.0230
Bin 11 Probability: 0.0080
Sum of probabilities: 1.0
This code segment goes through the necessary steps to generate a histogram and calculate probabilities for a synthetic dataset. It demonstrates important scientific and computational practices including binning, visualization, and probability calculation in Python.
Key Points: - The histogram represents the distribution of data, with the histogram’s bins outlining the data’s spread and density. - The option density=True in ax.hist() normalizes the histogram so that the total area under the histogram sums to 1, thereby converting frequencies to probability densities. - The choice of bin number and width has a significant influence on the histogram’s shape and the insights that can be drawn from it, highlighting the importance of selecting appropriate binning strategies based on the dataset’s characteristics and the analysis objectives.
18.3.2 Probability Distributions
What happens when we use smaller bins in a histogram? The histogram becomes more detailed, revealing the distribution of data points with greater precision. However, as the bin size decreases, the number of data points within each bin may decrease, leading to sparse or empty bins. This sparsity can make it challenging to estimate probabilities accurately, especially for data points that fall within these empty bins.
Advantages, when using a probability distribution, include:
Blanks can be filled
Probabilities can be calculated
Parameters are sufficiemnt to describe the distribution, e.g., mean and variance for the normal distribution
Probability distributions offer a powerful solution to the challenges posed by limited data in estimating probabilities. When data is scarce, constructing a histogram to determine the probability of certain outcomes can lead to inaccurate or unreliable results due to the lack of detail in the dataset. However, collecting vast amounts of data to populate a histogram for more precise estimates can often be impractical, time-consuming, and expensive.
A probability distribution is a mathematical function that provides the probabilities of occurrence of different possible outcomes for an experiment. It is a more efficient approach to understanding the likelihood of various outcomes than relying solely on extensive data collection. For continuous data, this is often represented graphically by a smooth curve.
18.3.2.1 The Normal Distribution: A Common Example
A commonly encountered probability distribution is the normal distribution, known for its characteristic bell-shaped curve. This curve represents how the values of a variable are distributed: most of the observations cluster around the mean (or center) of the distribution, with frequencies gradually decreasing as values move away from the mean.
The normal distribution is particularly useful because of its defined mathematical properties. It is determined entirely by its mean (mu, \(\mu\)) and its standard deviation (sigma, \(\sigma\)). The area under the curve represents probability, making it possible to calculate the likelihood of a random variable falling within a specific range.
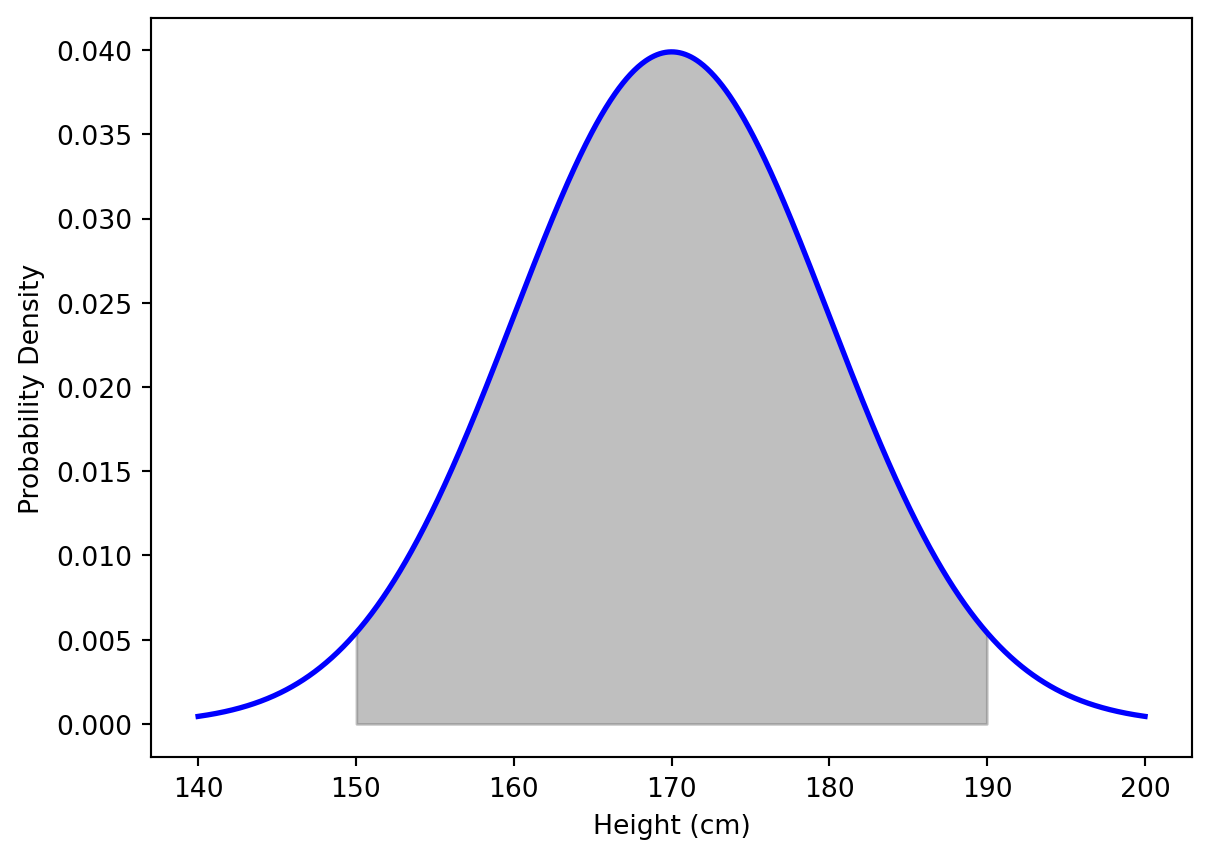
Consider we are interested in the heights of adults in a population. Instead of measuring the height of every adult (which would be impractical), we can use the normal distribution to estimate the probability of adults’ heights falling within certain intervals, assuming we know the mean and standard deviation of the heights.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import normmu =170# e.g., mu height of adults in cmsd =10# e.g., standard deviation of heights in cmheights = np.linspace(mu -3*sd, mu +3*sd, 1000)# Calculate the probability density function for the normal distributionpdf = norm.pdf(heights, mu, sd)# Plot the normal distribution curveplt.plot(heights, pdf, color='blue', linewidth=2)plt.fill_between(heights, pdf, where=(heights >= mu -2* sd) & (heights <= mu +2*sd), color='grey', alpha=0.5)plt.xlabel('Height (cm)')plt.ylabel('Probability Density')plt.show()
Figure 18.2: Normal Distribution Curve with Highlighted Probability Area. 95 percent of the data falls within two standard deviations of the mean.
This Python code snippet generates a plot of the normal distribution for adult heights, with a mean of 170 cm and a standard deviation of 10 cm. It visually approximates a histogram with a blue bell-shaped curve, and highlights (in grey) the area under the curve between \(\mu \pm 2 \times \sigma\). This area corresponds to the probability of randomly selecting an individual whose height falls within this range.
By using the area under the curve, we can efficiently estimate probabilities without needing to collect and analyze a vast amount of data. This method not only saves time and resources but also provides a clear and intuitive way to understand and communicate statistical probabilities.
18.3.3 Discrete Distributions
Discrete probability distributions are essential tools in statistics, providing a mathematical foundation to model and analyze situations with discrete outcomes. Histograms, which can be seen as discrete distributions with data organized into bins, offer a way to visualize and estimate probabilities based on the collected data. However, they come with limitations, especially when data is scarce or when we encounter gaps in the data (blank spaces in histograms). These gaps can make it challenging to accurately estimate probabilities.
A more efficient approach, especially for discrete data, is to use mathematical equations—particularly those defining discrete probability distributions—to calculate probabilities directly, thus bypassing the intricacies of data collection and histogram interpretation.
18.3.3.1 Bernoulli Distribution
The Bernoulli distribution, named after Swiss scientist Jacob Bernoulli, is a discrete probability distribution, which takes value \(1\) with success probability \(p\) and value \(0\) with failure probability \(q = 1-p\). So if \(X\) is a random variable with this distribution, we have: \[
P(X=1) = 1-P(X=0) = p = 1-q.
\]
18.3.3.2 Binomial Distribution
The Binomial Distribution is a prime example of a discrete probability distribution that is particularly useful for binary outcomes (e.g., success/failure, yes/no, pumpkin pie/blueberry pie). It leverages simple mathematical principles to calculate the probability of observing a specific number of successes (preferred outcomes) in a fixed number of trials, given the probability of success in each trial.
18.3.3.3 An Illustrative Example: Pie Preference
Consider a scenario from “StatLand” where 70% of people prefer pumpkin pie over blueberry pie. The question is: What is the probability that, out of three people asked, the first two prefer pumpkin pie and the third prefers blueberry pie?
Using the concept of the Binomial Distribution, the probability of such an outcome can be calculated without the need to layout every possible combination by hand. This process not only simplifies calculations but also provides a clear and precise method to determine probabilities in scenarios involving discrete choices. We will use Python to calculate the probability of observing exactly two out of three people prefer pumpkin pie, given the 70% preference rate:
from scipy.stats import binomn =3# Number of trials (people asked)p =0.7# Probability of success (preferring pumpkin pie)x =2# Number of successes (people preferring pumpkin pie)# Probability calculation using Binomial Distributionprob = binom.pmf(x, n, p)print(f"The probability that exactly 2 out of 3 people prefer pumpkin pie is: {prob:.3f}")
The probability that exactly 2 out of 3 people prefer pumpkin pie is: 0.441
This code uses the binom.pmf() function from scipy.stats to calculate the probability mass function (PMF) of observing exactly x successes in n trials, where each trial has a success probability of p.
A Binomial random variable is the sum of \(n\) independent, identically distributed Bernoulli random variables, each with probability \(p\) of success. We may indicate a random variable \(X\) with Bernoulli distribution using the notation \(X \sim \mathrm{Bi}(1,\theta)\). Then, the notation for the Binomial is \(X \sim \mathrm{Bi}(n,\theta)\). Its probability and distribution functions are, respectively, \[
p_X(x) = {n\choose x}\theta^x(1-\theta)^{n-x}, \qquad F_X(x) = \Pr\{X \le x\} = \sum_{i=0}^{x} {n\choose i}\theta^i(1-\theta)^{n-i}.
\]
The mean of the binomial distribution is \(\text{E}[X] = n\theta\). The variance of the distribution is \(\text{Var}[X] = n\theta(1-\theta)\) (see next section).
A process consists of a sequence of \(n\) independent trials, i.e., the outcome of each trial does not depend on the outcome of previous trials. The outcome of each trial is either a success or a failure. The probability of success is denoted as \(p\), and \(p\) is constant for each trial. Coin tossing is a classical example for this setting.
The binomial distribution is a statistical distribution giving the probability of obtaining a specified number of successes in a binomial experiment; written Binomial(n, p), where \(n\) is the number of trials, and \(p\) the probability of success in each.
Definition 18.1 (Binomial Distribution) The binomial distribution with parameters \(n\) and \(p\), where \(n\) is the number of trials, and \(p\) the probability of success in each, is \[\begin{equation}
p(x) = { n \choose k } p^x(1-p)^{n-x} \qquad x = 0,1, \ldots, n.
\end{equation}\] The mean \(\mu\) and the variance \(\sigma^2\) of the binomial distribution are \[\begin{equation}
\mu = np
\end{equation}\] and \[\begin{equation}
\sigma^2 = np(1-p).
\end{equation}\]
Note, the Bernoulli distribution is simply Binomial(1,p).
18.4 Continuous Distributions
Our considerations regarding probability distributions, expectations, and standard deviations will be extended from discrete distributions to continuous distributions. One simple example of a continuous distribution is the uniform distribution. Continuous distributions are defined by probability density functions.
18.4.1 Distribution functions: PDFs and CDFs
The density for a continuous distribution is a measure of the relative probability of “getting a value close to \(x\).” Probability density functions \(f\) and cumulative distribution function \(F\) are related as follows. \[\begin{equation}
f(x) = \frac{d}{dx} F(x)
\end{equation}\]
Definition 18.3 (Variance (Continuous)) Variance can be calculated with \(\text{E}(X)\) and \[\begin{equation}
\text{E}(X^2) = \int_{-\infty}^\infty x^2 f(x) \, dx
\end{equation}\] as \[\begin{equation*}
\text{Var}(X) = \text{E}(X^2) - [ E(X)]^2.
\end{equation*}\]\(\Box\)
Definition 18.4 (Standard Deviation (Continuous)) Standard deviation can be calculated as \[\begin{equation*}
\text{sd}(X) = \sqrt{\text{Var}(X)}.
\end{equation*}\]\(\Box\)
18.6 Uniform Distribution
This variable is defined in the interval \([a,b]\). We write it as \(X \sim U[a,b]\). Its density and cumulative distribution functions are, respectively, \[
f_X(x) = \frac{I_{[a,b]}(x)}{b-a}, \quad\quad F_X(x) = \frac{1}{b-a}\int\limits_{-\infty}\limits^x I_{[a,b]}(t) \mathrm{d}t = \frac{x-a}{b-a},
\] where \(I_{[a,b]}(\cdot)\) is the indicator function of the interval \([a,b]\). Note that, if we set \(a=0\) and \(b=1\), we obtain \(F_X(x) = x\), \(x\)\(\in\)\([0,1]\).
A typical example is the following: the cdf of a continuous r.v. is uniformly distributed in \([0,1]\). The proof of this statement is as follows: For \(u\)\(\in\)\([0,1]\), we have \[\begin{eqnarray*}
\Pr\{F_X(X) \leq u\} &=& \Pr\{F_X^{-1}(F_X(X)) \leq F_X^{-1}(u)\} = \Pr\{X \leq F_X^{-1}(u)\} \\
&=& F_X(F_X^{-1}(u)) = u.
\end{eqnarray*}\] This means that, when \(X\) is continuous, there is a one-to-one relationship (given by the cdf) between \(x\)\(\in\)\(D_X\) and \(u\)\(\in\)\([0,1]\).
The has a constant density over a specified interval, say \([a,b]\). The uniform \(U(a,b)\) distribution has density \[\begin{equation}
f(x) =
\left\{
\begin{array}{ll}
1/(b-a) & \textrm{ if } a < x < b,\\
0 & \textrm{ otherwise}
\end{array}
\right.
\end{equation}\]
18.7 Normal Distribution
Definition 18.5 (Normal Distribution) This variable is defined on the support \(D_X = \mathbb{R}\) and its density function is given by \[
f_X(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left \{-\frac{1}{2\sigma^2}(x-\mu)^2 \right \}.
\] The density function is identified by the pair of parameters \((\mu,\sigma^2)\), where \(\mu\)\(\in\)\(\mathbb{R}\) is the mean (or location parameter) and \(\sigma^2 > 0\) is the variance (or dispersion parameter) of \(X\). \(\Box\)
The density function is symmetric around \(\mu\). The normal distribution belongs to the location-scale family distributions. This means that, if \(Z \sim N(0,1)\) (read, \(Z\) has a standard normal distribution; i.e., with \(\mu=0\) and \(\sigma^2=1\)), and we consider the linear transformation \(X = \mu + \sigma Z\), then \(X \sim N(\mu,\sigma^2)\) (read, \(X\) has a normal distribution with mean \(\mu\) and variance \(\sigma^2\)). This means that one can obtain the probability of any interval \((-\infty,x]\), \(x\)\(\in\)\(R\) for any normal distribution (i.e., for any pair of the parameters \(\mu\) and \(\sigma\)) once the quantiles of the standard normal distribution are known. Indeed \[\begin{eqnarray*}
F_X(x) &=& \Pr\left\{X \leq x \right\} = \Pr\left\{\frac{X-\mu}{\sigma} \leq \frac{x-\mu}{\sigma} \right\} \\
&=& \Pr\left\{Z \leq \frac{x-\mu}{\sigma}\right\} = F_Z\left(\frac{x-\mu}{\sigma}\right) \qquad x \in \mathbb{R}.
\end{eqnarray*}\] The quantiles of the standard normal distribution are available in any statistical program. The density and cumulative distribution function of the standard normal r.v.~at point \(x\) are usually denoted by the symbols \(\phi(x)\) and \(\Phi(x)\).
The standard normal distribution is based on the \[
\varphi(z) = \frac{1}{\sqrt{2\pi}} \exp \left(- \frac{z^2}{2} \right).
\tag{18.1}\]
An important application of the standardization introduced in Equation 18.1 reads as follows. In case the distribution of \(X\) is approximately normal, the distribution of X^{*} is approximately standard normal. That is \[\begin{equation*}
P(X\leq b) = P( \frac{X-\mu}{\sigma} \leq \frac{b-\mu}{\sigma}) = P(X^{*} \leq \frac{b-\mu}{\sigma})
\end{equation*}\] The probability \(P(X\leq b)\) can be approximated by \(\Phi(\frac{b-\mu}{\sigma})\), where \(\Phi\) is the standard normal cumulative distribution function.
If \(X\) is a normal random variable with mean \(\mu\) and variance \(\sigma^2\), i.e., \(X \sim \cal{N} (\mu, \sigma^2)\), then \[\begin{equation}
X = \mu + \sigma Z \textrm{ where } Z \sim \cal{N}(0,1).
\end{equation}\]
If \(Z \sim \cal{N}(0,1)\) and \(X\sim \cal{N}(\mu, \sigma^2)\), then \[\begin{equation*}
X = \mu + \sigma Z.
\end{equation*}\]
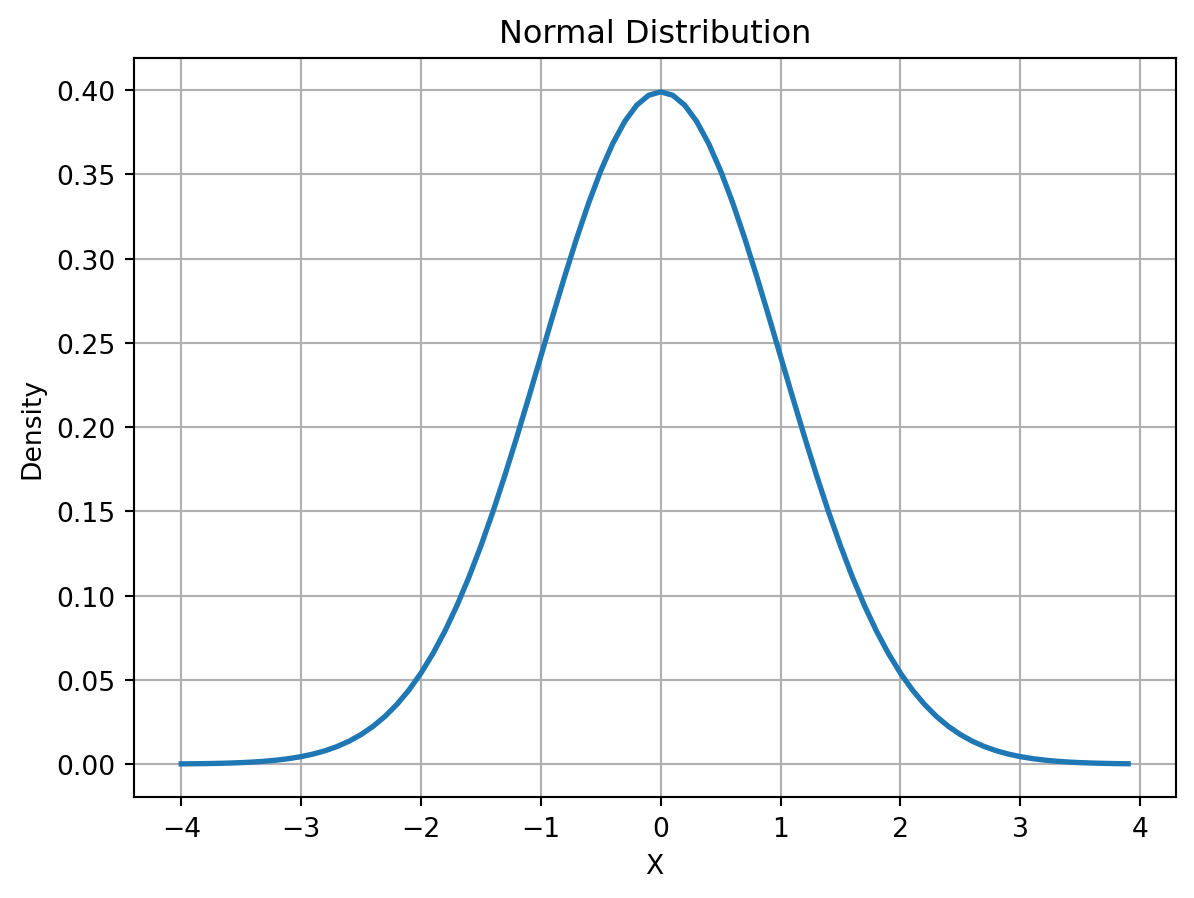
The probability of getting a value in a particular interval is the area under the corresponding part of the curve. Consider the density function of the normal distribution. It can be plotted using the following commands. The result is shown in Figure 18.3.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import normx = np.arange(-4, 4, 0.1)# Calculating the normal distribution's density function values for each point in xy = norm.pdf(x, 0, 1)plt.plot(x, y, linestyle='-', linewidth=2)plt.title('Normal Distribution')plt.xlabel('X')plt.ylabel('Density')plt.grid(True)plt.show()
Figure 18.3: Normal Distribution Density Function
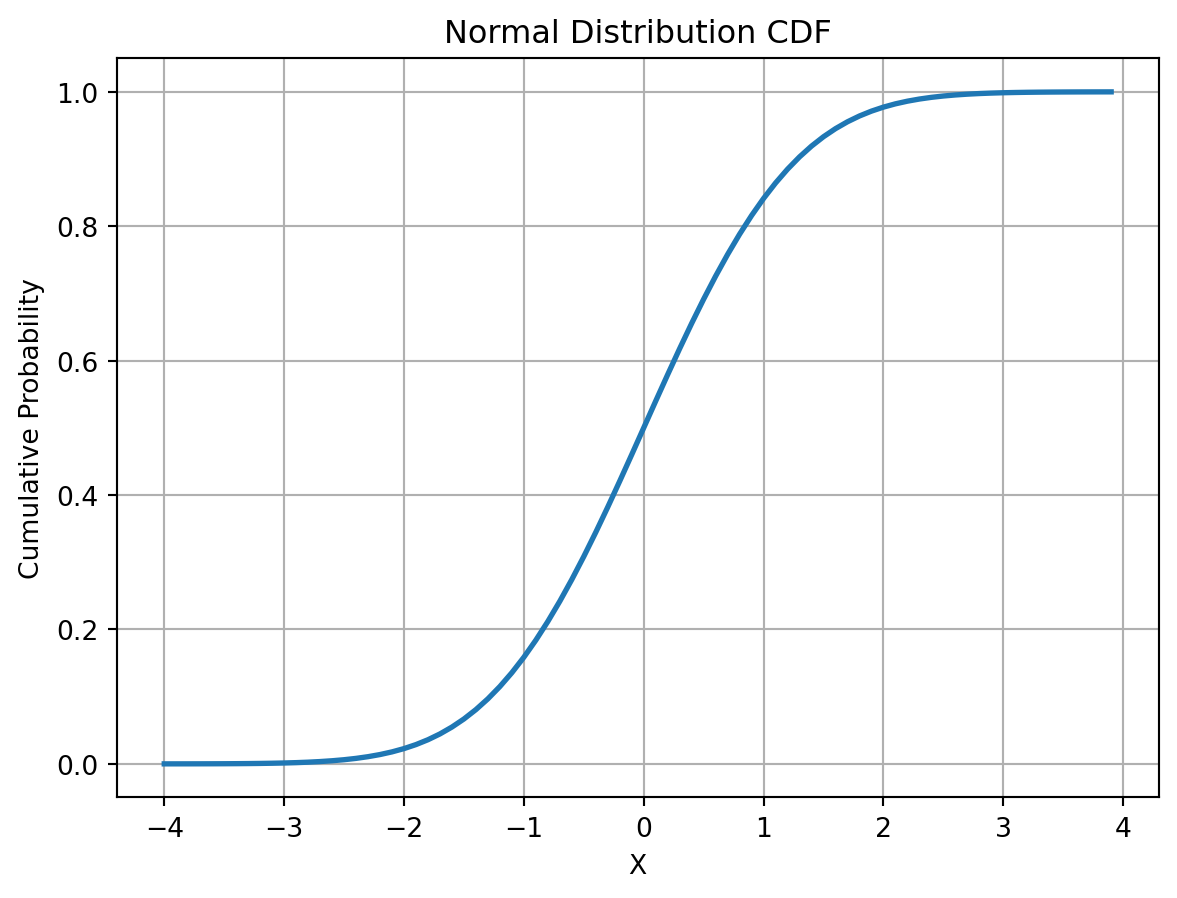
The (CDF) describes the probability of “hitting” \(x\) or less in a given distribution. We consider the CDF function of the normal distribution. It can be plotted using the following commands. The result is shown in Figure 18.4.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import norm# Generating a sequence of numbers from -4 to 4 with 0.1 intervalsx = np.arange(-4, 4, 0.1)# Calculating the cumulative distribution function value of the normal distribution for each point in xy = norm.cdf(x, 0, 1) # mean=0, stddev=1# Plotting the results. The equivalent of 'type="l"' in R (line plot) becomes the default plot type in matplotlib.plt.plot(x, y, linestyle='-', linewidth=2)plt.title('Normal Distribution CDF')plt.xlabel('X')plt.ylabel('Cumulative Probability')plt.grid(True)plt.show()
Figure 18.4: Normal Distribution Cumulative Distribution Function
18.8 The Mean, the Median, and the Mode
18.9 The Exponential Distribution
The exponential distribution is a continuous probability distribution that describes the time between events in a Poisson process, where events occur continuously and independently at a constant average rate. It is characterized by a single parameter, the rate parameter \(\lambda\), which represents the average number of events per unit time.
18.10 Population and Estimated Parameters
18.11 Calculating the Mean, Variance, and Standard Deviation
18.12 What is a Mathematical Model?
18.13 Sampling from a Distribution
18.14 Hypothesis Testing and the Null Hypothesis
18.14.1 Alternative Hypotheses
18.15 p-values: What They Are and How to Interpret Them
18.16 How to Calculate p-values
18.17 p-hacking: What It Is and How to Avoid It
18.18 Covariance
18.19 Pearson’s Correlation
18.19.1 Interpreting the Correlation: Correlation Squared
Rummel (1976) describes how to interpret correlations as follows:
Seldom, indeed, will a correlation be zero or perfect. Usually, the covariation between things will be something like \(.56\) or \(-.16\). Clearly \(.56\) is positive, indicating positive covariation; \(-.16\) is negative, indicating some negative covariation. Moreover, we can say that the positive correlation is greater than the negative. But, we require more than. If we have a correlation of \(.56\) between two variables, for example, what precisely can we say other than the correlation is positive and \(.56\)? The squared correlation describes the proportion of variance in common between the two variables. If we multiply this by 100 we then get the percent of variance in common between two variables. That is:
\[
r^2_{XY} \times 100 = \text{percent of variance in common between} X \text{ and } Y.
\]
For example, we found that the correlation between a nation’s power and its defense budget was \(.66\). This correlation squared is \(.45\), which means that across the fourteen nations constituting the sample \(45\) percent of their variance on the two variables is in common (or \(55\) percent is not in common). In thus squaring correlations and transforming covariance to percentage terms we have an easy to understand meaning of correlation. And we are then in a position to evaluate a particular correlation. As a matter of routine it is the squared correlations that should be interpreted. This is because the correlation coefficient is misleading in suggesting the existence of more covariation than exists, and this problem gets worse as the correlation approaches zero.
Example 18.3 (The relationship between study time and test scores) Imagine we are examining the relationship between the number of hours students study for a subject (Variable \(A\)) and their scores on a test (Variable \(B\)). After analyzing the data, we calculate a correlation of 0.8 between study time and test scores. When we square this correlation coefficient (\(0.8^2\) = 0.64), we get 0.64 or 64%. This means that 64% of the variability in test scores can be accounted for by the variability in study hours. This indicates that a substantial part of why students score differently on the test can be explained by how much they studied. However, there remains 36% of the variability in test scores that needs to be explained by other factors, such as individual abilities, the difficulty of the test, or other external influences.
18.20 Partial Correlation
Often, a correlation between two variables \(X\) and \(Y\) can be found only because both variables are correlated with a third variable \(Z\). The correlation between \(X\) and \(Y\) is then a spurious correlation. Therefore, it is often of interest to determine the correlation between \(X\) and \(Y\) while partializing a variable \(Z\), i.e., the correlation between \(X\) and \(Y\) that exists without the influence of \(Z\). Such a correlation \(\rho_{(X,Y)/Z}\) is called the partial correlation of \(X\) and \(Y\) while holding \(Z\) constant. It is given by \[\begin{equation}
\rho_{(X,Y)/Z} = \frac{\rho_{XY} - \rho_{XZ}\rho_{YZ}}{\sqrt{(1-\rho_{XZ}^2)(1-\rho_{YZ}^2)}},
\end{equation}\] where \(\rho_{XY}\) is the correlation between \(X\) and \(Y\), \(\rho_{XZ}\) is the correlation between \(X\) and \(Z\), and \(\rho_{YZ}\) is the correlation between \(Y\) and \(Z\)(Hartung, Elpert, and Klösener 1995).
If the variables \(X\), \(Y\) and \(Z\) are jointly normally distributed in the population of interest, one can estimate \(\rho_{(X,Y)/Z}\) based on \(n\) realizations \(x_1, \ldots, x_n\), \(y_1, \ldots, y_n\) and \(z_1, \ldots, z_n\) of the random variables \(X\), \(Y\) and \(Z\) by replacing the simple correlations \(\rho_{XY}\), \(\rho_{XZ}\) and \(\rho_{YZ}\) with the empirical correlations \(\hat{\rho}_{XY}\), \(\hat{\rho}_{XZ}\) and \(\hat{\rho}_{YZ}\). The partial correlation coefficient \(\hat{\rho}_{(X,Y)/Z}\) is then estimated using \[\begin{equation}
r_{(X,Y)/Z} = \frac{r_{XY} - r_{XZ}r_{YZ}}{\sqrt{(1-r_{XZ}^2)(1-r_{YZ}^2)}}.
\end{equation}\] Based on this estimated value for the partial correlation, a test at the \(\alpha\) level for partial uncorrelatedness or independence of \(X\) and \(Y\) under \(Z\) can also be carried out. The hypothesis
\[\begin{equation}
H_0: \rho_{(X,Y)/Z} = 0
\end{equation}\] is tested against the alternative \[\begin{equation}
H_1: \rho_{(X,Y)/Z} \neq 0
\end{equation}\] at the level \(\alpha\) is discarded if \[
\left|
\frac{r_{(X,Y)/Z} \sqrt{n-3}}{\sqrt{1-r_{(X,Y)/Z}^2}}
\right| > t_{n-3, 1-\alpha/2}
\] applies. Here \(t_{n-3, 1-\alpha/2}\) is the (\(1-\alpha/2\))-quantile of the \(t\)-distribution with \(n-3\) degrees of freedom.
Example 18.4 For example, given economic data on the consumption \(X\), income \(Y\), and wealth \(Z\) of various individuals, consider the relationship between consumption and income. Failing to control for wealth when computing a correlation coefficient between consumption and income would give a misleading result, since income might be numerically related to wealth which in turn might be numerically related to consumption; a measured correlation between consumption and income might actually be contaminated by these other correlations. The use of a partial correlation avoids this problem (Wikipedia contributors 2024).
Example 18.5 (Partial Correlation. Numerical Example) Given the following data, calculate the partial correlation between \(A\) and \(B\), controlling for \(C\). \[
A = \begin{pmatrix}
2\\
4\\
15\\
20
\end{pmatrix}, \quad B = \begin{pmatrix}
1\\
2\\
3\\
4
\end{pmatrix}, \quad C = \begin{pmatrix}
0\\
0\\
1\\
1
\end{pmatrix}
\]
from spotpython.utils.stats import partial_correlationimport numpy as npimport pandas as pddata = pd.DataFrame({'A': [2, 4, 15, 20],'B': [1, 2, 3, 4],'C': [0, 0, 1, 1]})print(f"Correlation between A and B: {data['A'].corr(data['B'])}")pc = partial_correlation(data, method='pearson')print(f"Partial Correlation between A and B: {pc["estimate"][0, 1]}")
Correlation between A and B: 0.9695015519208121
Partial Correlation between A and B: 0.9191450300180576
Instead of considering only one variable \(Z\), multiple variables \(Z_i\) can be considered. The formal definiton of partial correlation reads as follows:
Definition 18.6 Formally, the partial correlation between \(X\) and \(Y\) given a set of \(n\) controlling variables \(\mathbf{Z} = \{Z_1, Z_2, \ldots, Z_n\}\), written \(\rho_{XY \cdot \mathbf{Z}}\), is the correlation between the residuals \(e_X\) and \(e_Y\) resulting from the linear regression of \(X\) with \(\mathbf{Z}\) and of \(Y\) with \(\mathbf{Z}\), respectively. The first-order partial correlation (i.e., when \(n = 1\)) is the difference between a correlation and the product of the removable correlations divided by the product of the coefficients of alienation of the removable correlations (Wikipedia contributors 2024).
Like the correlation coefficient, the partial correlation coefficient takes on a value in the range from -1 to 1. The value -1 conveys a perfect negative correlation controlling for some variables (that is, an exact linear relationship in which higher values of one variable are associated with lower values of the other); the value 1 conveys a perfect positive linear relationship, and the value 0 conveys that there is no linear relationship (Wikipedia contributors 2024).
Lemma 18.1 (Matrix Representation of the Partial Correlation) The partial correlation can also be written in terms of the joint precision matrix (Wikipedia contributors 2024). Consider a set of random variables, \(\mathbf{V} = \{X_1,\dots, X_n\}\) of cardinality \(n\). We want the partial correlation between two variables \(X_i\) and \(X_j\) given all others, i.e., \(\mathbf{V} \setminus \{X_i, X_j\}\). Suppose the (joint/full) covariance matrix \(\Sigma = (\sigma_{ij})\) is positive definite and therefore invertible. If the precision matrix is defined as \(\Omega = (p_{ij}) = \Sigma^{-1}\), then \[\begin{equation}
\rho_{X_i X_j \cdot \mathbf{V} \setminus \{X_i,X_j\}} = - \frac{p_{ij}}{\sqrt{p_{ii}p_{jj}}}
\end{equation}\]
The semipartial correlation statistic is similar to the partial correlation statistic; both compare variations of two variables after certain factors are controlled for. However, to calculate the semipartial correlation, one holds the third variable constant for either X or Y but not both; whereas for the partial correlation, one holds the third variable constant for both (Wikipedia contributors 2024).
18.21 Boxplots
18.22 R-squared
18.23 The Main Ideas of Fitting a Line to Data
18.24 Linear Regression
18.25 Multiple Regression
18.26 Assessing Confounding Effects in Multiple Regression
Confounding is a bias introduced by the imbalanced distribution of extraneous risk factors among comparison groups (Wang 2007). spotpython provides tools for assessing confounding effects in multiple regression models.
Example 18.6 (Assessing Confounding Effects in Multiple Regression with spotpython) Consider the following data generation function generate_data and the fit_ols_model function to fit an ordinary least squares (OLS) regression model.
import numpy as npimport pandas as pdimport statsmodels.formula.api as smfdef generate_data(n_samples=100, b0=0, b1=-1, b2=0, b3=10, b12=0, b13=0, b23=0, b123=0, noise_std=1) -> pd.DataFrame:""" Generate data for the linear formula y ~ b0 + b1*x1 + b2*x2 + b3*x3 + b12*x1*x2 + b13*x1*x3 + b23*x2*x3 + b123*x1*x2*x3. Args: n_samples (int): Number of samples to generate. b0 (float): Coefficient for the intercept. b1 (float): Coefficient for x1. b2 (float): Coefficient for x2. b3 (float): Coefficient for x3. b12 (float): Coefficient for the interaction term x1*x2. b13 (float): Coefficient for the interaction term x1*x3. b23 (float): Coefficient for the interaction term x2*x3. b123 (float): Coefficient for the interaction term x1*x2*x3. noise_std (float): Standard deviation of the Gaussian noise added to y. Returns: pd.DataFrame: A DataFrame containing the generated data with columns ['x1', 'x2', 'x3', 'y']. """ np.random.seed(42) # For reproducibility x1 = np.random.uniform(0, 1, n_samples) x2 = np.random.uniform(0, 1, n_samples) x3 = np.random.uniform(0, 1, n_samples) y = (b0 + b1*x1 + b2*x2 + b3*x3 + b12*x1*x2 + b13*x1*x3 + b23*x2*x3 + b123*x1*x2*x3 + np.random.normal(0, noise_std, n_samples)) data = pd.DataFrame({'y': y, 'x1': x1, 'x2': x2, 'x3': x3})return datadef fit_ols_model(formula, data) ->dict:""" Fit an OLS model using the given formula and data, and print the results. Args: formula (str): The formula for the OLS model. data (pd.DataFrame): The data frame containing the variables. Returns: dict: A dictionary containing the p-values, estimates, confidence intervals, and AIC value. """ mod_0 = smf.ols(formula=formula, data=data).fit() p = mod_0.pvalues.iloc[1] estimate = mod_0.params.iloc[1] conf_int = mod_0.conf_int().iloc[1] aic_value = mod_0.aicprint(f"p-values: {p}")print(f"estimate: {estimate}")print(f"conf_int: {conf_int}")print(f"aic: {aic_value}")
These functions can be used to generate data and fit an OLS model. Here we use the model \[
y = f(x_1, x_2, x_3) + \epsilon = x_1 + 10 x_3 + \epsilon.
\] We set up the basic model \(y_0 = f_0(x_1)\) and analyze how the model fit changes when adding \(x_2\) and \(x_3\) to the model. If the \(p\)-values are decreasing by adding a variable, this indicates that the variable is relevant for the model. Similiarly, if the \(p\)-values are increasing by removing a variable, this indicates that the variable is not relevant for the model.
The function fit_all_lm() simplifies this procedure. It can be used to fit all possible linear models with the given data and print the results in a systematic way for various combinations of variables.
The basic model is: y ~ x1
The following features will be used for fitting the basic model: Index(['x3', 'x1', 'y', 'x2'], dtype='object')
p-values: 0.34343741859526267
estimate: 1.025306391110114
conf_int: 0 -1.111963
1 3.162575
Name: x1, dtype: float64
aic: 517.6397392012537
Combinations: [('x2',), ('x3',), ('x2', 'x3')]
variables estimate conf_low conf_high p aic n
0 basic 1.025306 -1.111963 3.162575 0.343437 517.639739 100
1 x2 0.981050 -1.152698 3.114798 0.363751 518.142651 100
2 x3 1.407792 0.750106 2.065479 0.000049 282.735245 100
3 x2, x3 1.415929 0.755494 2.076364 0.000048 284.346654 100
Interpreting the results, we can see that the \(p\)-values decrease when adding \(x_3\) (as well as both \(x_2\) and $x_3) to the model, indicating that \(x_3\) is relevant for the model. Adding only \(x_2\) does not significantly improve the model fit.
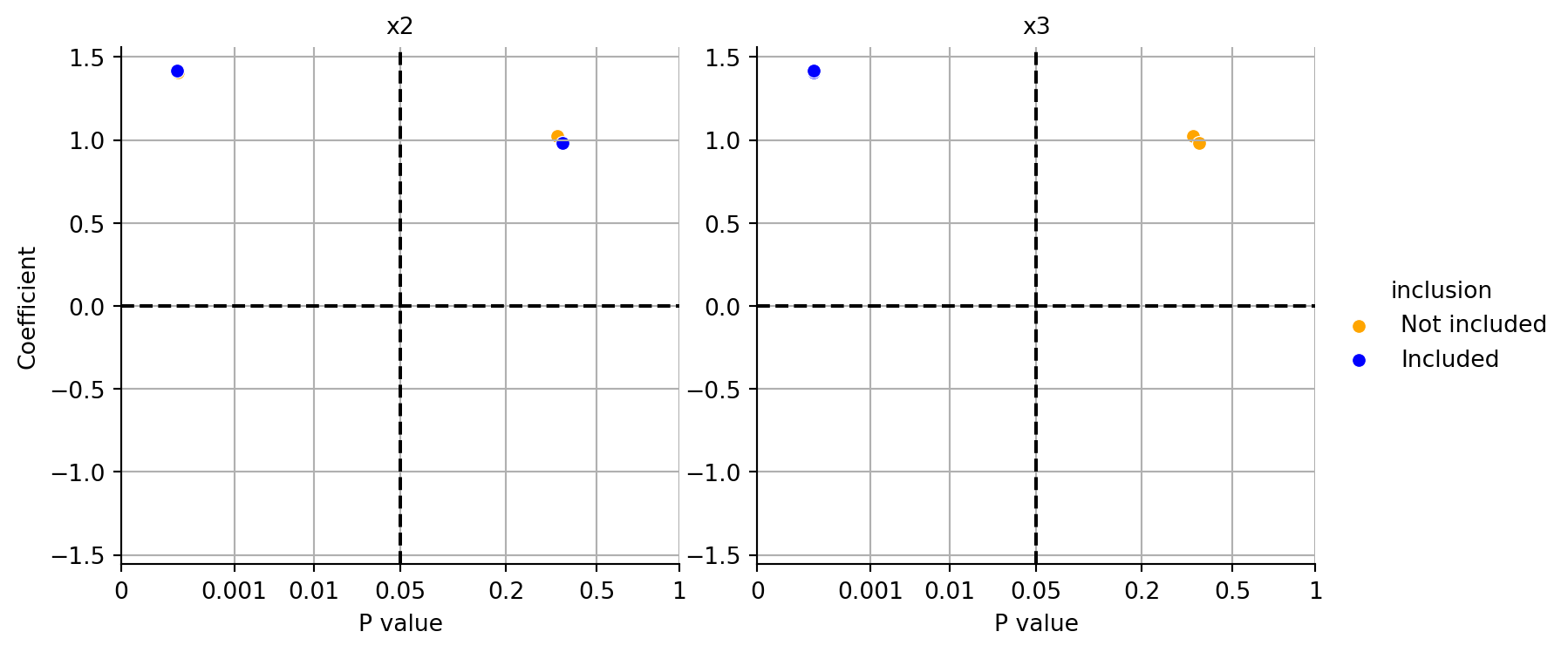
In addition to the textural output, the function plot_coeff_vs_pvals_by_included() can be used to visualize the coefficients and p-values of the fitted models.
plot_coeff_vs_pvals_by_included(res)
Figure 18.5: Coefficients vs. p-values for different models. The right plot indicates that x3 should be included in the model, whereas the left plot shows that x2 is not relevant.
Figure 18.5 shows the coefficients and p-values for different models. Because \(y\) depends on \(x1\) and \(x3\), the p-value much smaller if \(x3\) is included in the model as can be seen in the right plot in Figure 18.5. The left plot shows that including \(x2\) in the model does not significantly improve the model fit.
18.27 Supervised Learning
Objectives of supervised learning: On the basis of the training data we would like to:
Accurately predict unseen test cases.
Understand which inputs affect the outcome, and how.
Assess the quality of our predictions and inferences.
Note: Supervised means \(Y\) is known.
Exercise 18.105
Do children learn supervised?
When do you learn supervised?
Can learning be unsupervised?
18.27.0.0.1 Unsupervised Learning
No outcome variable, just a set of predictors (features) measured on a set of samples. The objective is more fuzzy—find groups of samples that behave similarly, find features that behave similarly, find linear combinations of features with the most variation. It is difficult to know how well your are doing. Unsupervised learning different from supervised learning, but can be useful as a pre-processing step for supervised learning. Clustering and principle component analysis are important techniques.
Unsupervised: \(Y\) is unknown, there is no \(Y\), no trainer, no teacher, but: distances between the inputs values (features). A distance (or similarity) measure is necessary.
18.27.0.0.2 Statistical Learning
We consider supervised learning first.
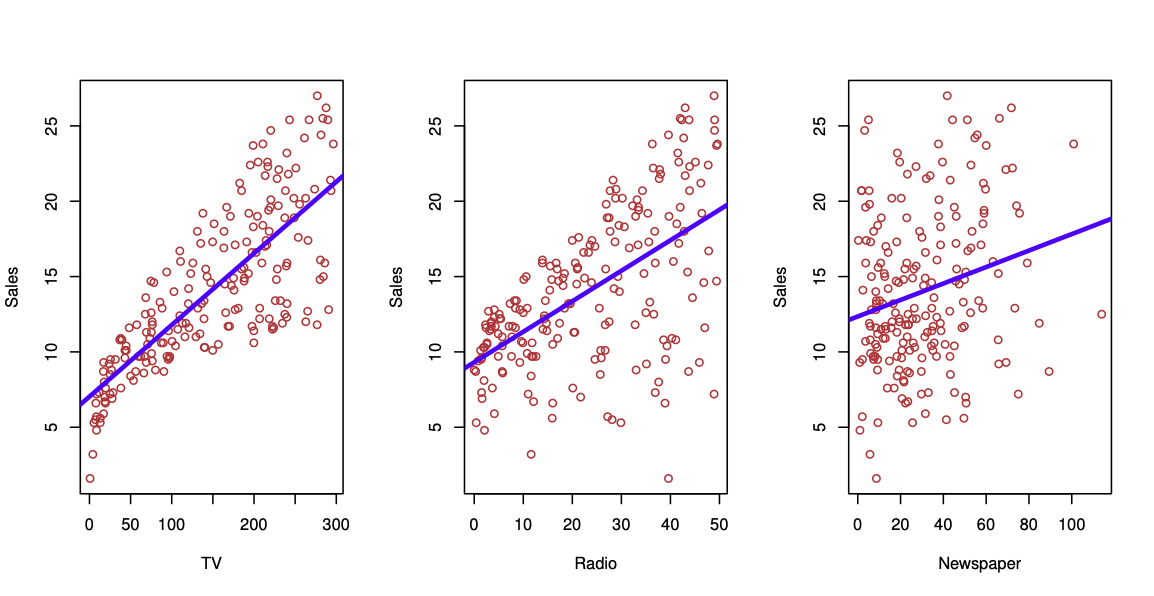
Figure 18.6: Sales as a function of TV, radio and newspaper. Taken from James et al. (2014)
Sales figures from a marketing campaign, see Figure 18.6. Trend shown using regression. First seems to be stronger than the third.
Can we predict \(Y\) = Sales using these three? Perhaps we can do better using a model \[
Y = Sales \approx f(X_1 = TV, X_2 = Radio, X_3= Newspaper)
\] modeling the joint relationsship.
Here Sales is a response or target that we wish to predict. We generically refer to the response as \(Y\). TV is a feature, or input, or predictor; we name it \(X_1\). Likewise name Radio as \(X_2\), and so on. We can refer to the input vector collectively as \[
X =
\begin{pmatrix}
X_1\\
X_2\\
X_3
\end{pmatrix}
\]
Now we write our model as \[
Y = f(X) + \epsilon
\] where \(\epsilon\) captures measurement errors and other discrepancies.
What is \(f\) good for? With a good \(f\) we can make predictions of \(Y\) at new points \(X = x\). We can understand which components of \(X = (X_1, X_2, \ldots X_p)\) are important in explaining \(Y\), and which are irrelevant.
For example, Seniority and Years of Education have a big impact on Income, but Marital Status typically does not. Depending on the complexity of \(f\), we may be able to understand how each component \(X_j\) of \(X\) affects \(Y\).
18.27.1 Statistical Learning and Regression
18.27.1.1 Regression Function
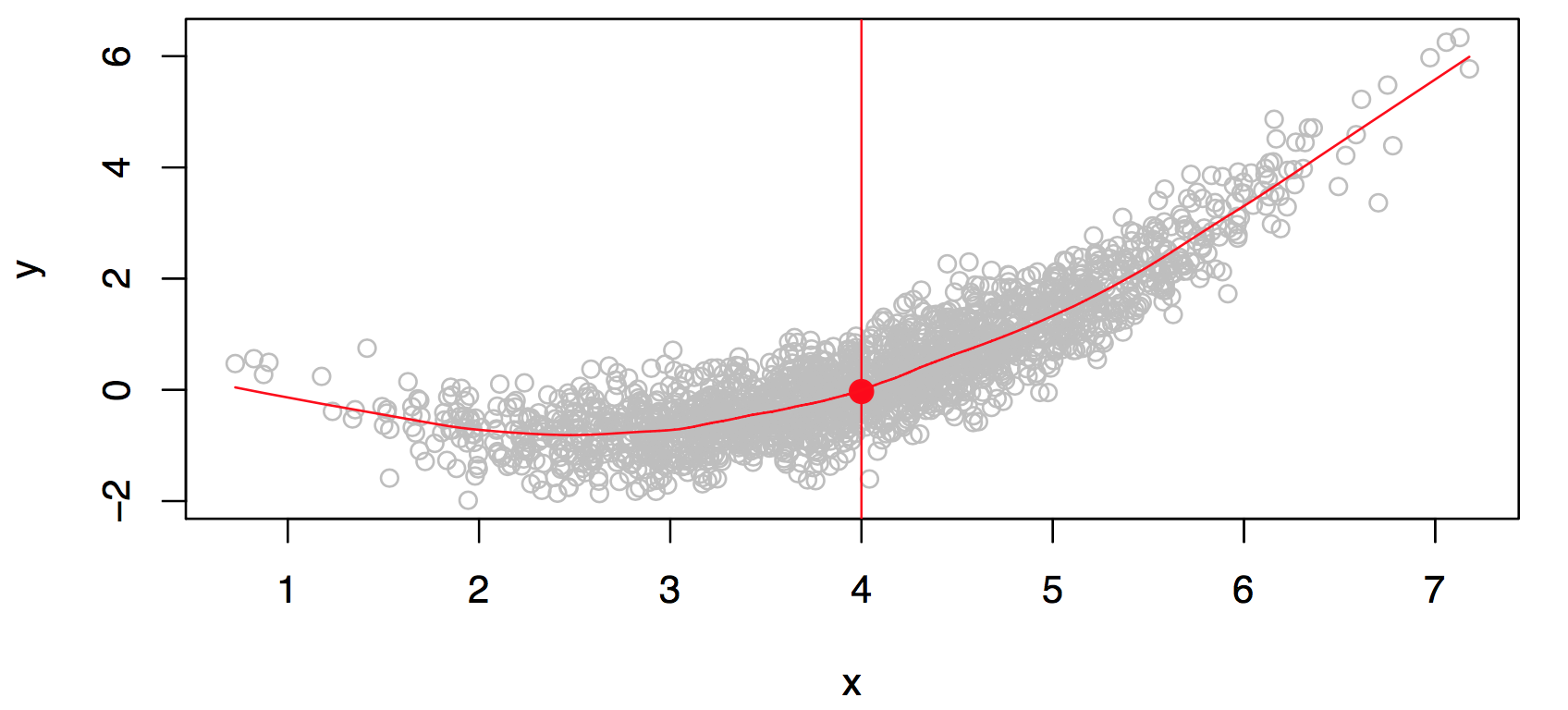
Figure 18.7: Scatter plot of 2000 points (population). What is a good function \(f\)? There are many function values at \(X=4\). A function can return only one value. We can take the mean from these values as a return value. Taken from James et al. (2014)
Consider Figure 18.7. Is there an ideal \(f(X)\)? In particular, what is a good value for \(f(X)\) at any selected value of \(X\), say \(X = 4\)? There can be many \(Y\) values at \(X=4\). A good value is \[
f(4) = E(Y |X = 4).
\]
\(E(Y |X = 4)\) means expected value (average) of \(Y\) given \(X = 4\).
The ideal \(f(x) = E(Y |X = x)\) is called the regression function. Read: The regression function gives the conditional expectation of \(Y\) given \(X\).
The regression function \(f(x)\) is also defined for the vector \(X\); e.g., \(f(x) = f(x_1, x_2, x_3) = E(Y | X_1 =x_1, X_2 =x_2, X_3 =x_3).\)
18.27.2 Optimal Predictor
The regression function is the ideal or optimal predictor of \(Y\) with regard to mean-squared prediction error: It means that \(f(x) = E(Y | X = x)\) is the function that minimizes \[
E[(Y - g(X))^2|X = x]
\] over all functions \(g\) at all points \(X = x\).
18.27.2.1 Residuals, Reducible and Irreducible Error
At each point \(X\) we make mistakes: \[
\epsilon = Y-f(x)
\] is the residual. Even if we knew \(f(x)\), we would still make errors in prediction, since at each \(X=x\) there is typically a distribution of possible \(Y\) values as is illustrated in Figure 18.7.
For any estimate \(\hat{f}(x)\) of \(f(x)\), we have \[
E\left[ ( Y - \hat{f}(X))^2 | X = x\right] = \left[ f(x) - \hat{f}(x) \right]^2 + \text{var}(\epsilon),
\] and \(\left[ f(x) - \hat{f}(x) \right]^2\) is the reducible error, because it depends on the model (changing the model \(f\) might reduce this error), and \(\text{var}(\epsilon)\) is the irreducible error.
18.27.2.2 Local Regression (Smoothing)
Typically we have few if any data points with \(X = 4\) exactly. So we cannot compute \(E(Y |X = x)\)! Idea: Relax the definition and let \[
\hat{f}(x)= Ave(Y|X \in \cal{N}(x)),
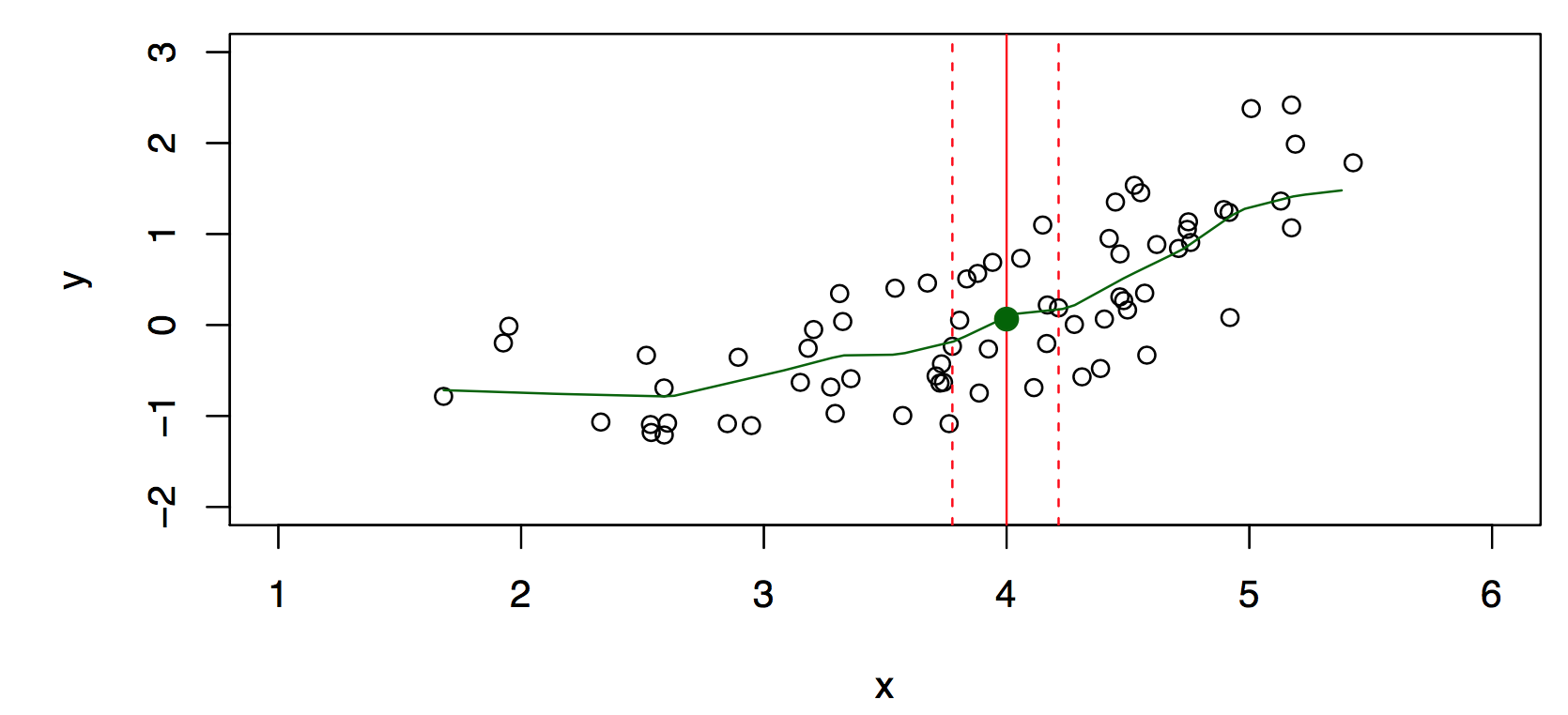
\] where \(\cal{N} (x)\) is some neighborhood of \(x\), see Figure 18.8.
Figure 18.8: Relaxing the definition. There is no \(Y\) value at \(X=4\). Taken from James et al. (2014)
Nearest neighbor averaging can be pretty good for small \(p\), i.e., \(p \leq 4\) and large-ish \(N\). We will discuss smoother versions, such as kernel and spline smoothing later in the course.
18.27.3 Curse of Dimensionality and Parametric Models
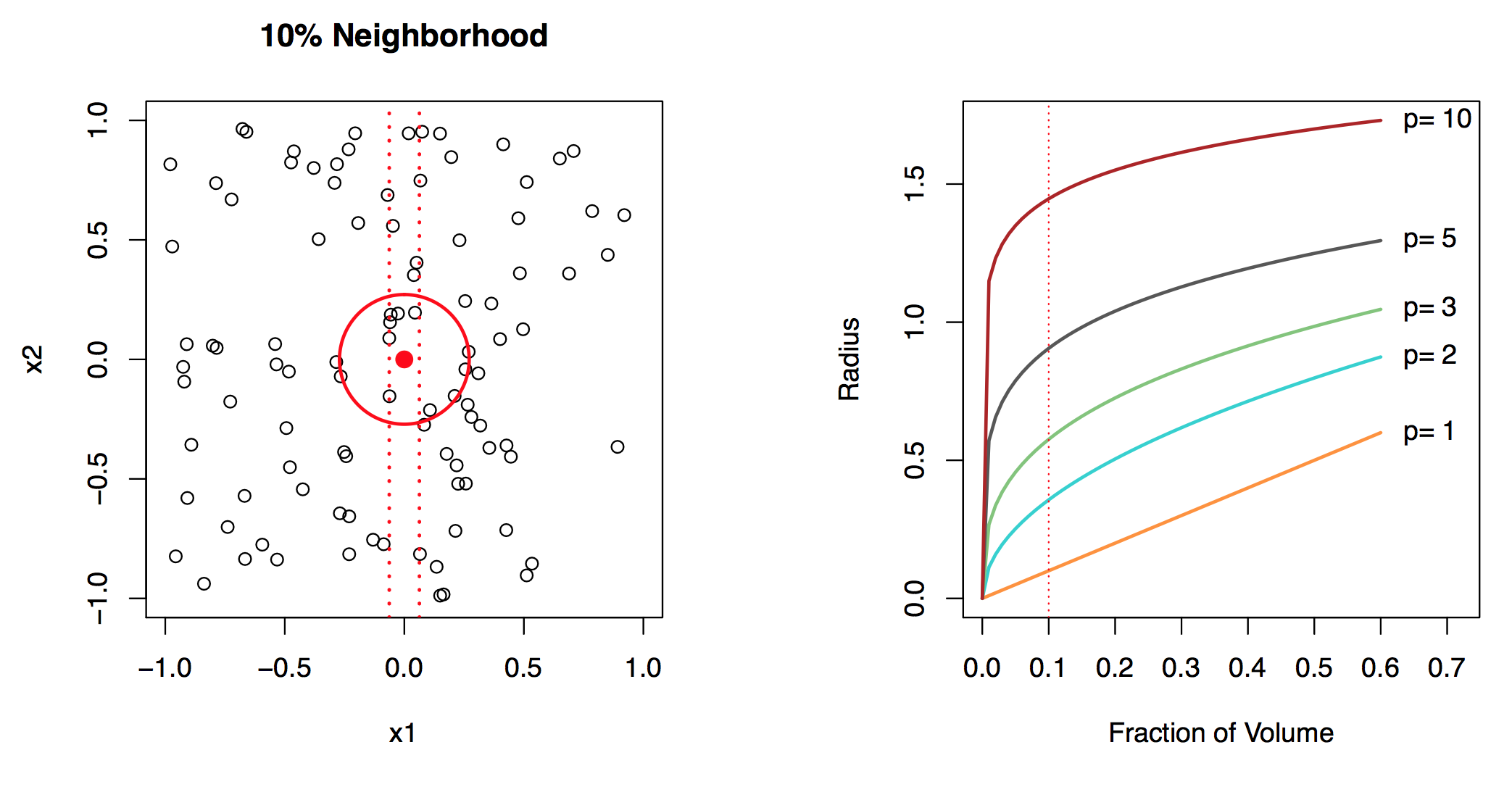
Figure 18.9: A 10% neighborhood in high dimensions need no longer be local. Left: Values of two variables \(x_1\) and \(x_2\), uniformly distributed. Form two 10% neighborhoods: (a) the first is just involving \(x_1\) ignoring \(x_2\). (b) is the neighborhood in two dimension. Notice that the radius of the circle is much larger than the lenght of the interval in one dimension. Right: radius plotted against fraction of the volume. In 10 dim, you have to break out the interval \([-1;+1]\) to get 10% of the data. Taken from James et al. (2014)
Local, e.g., nearest neighbor, methods can be lousy when \(p\) is large. Reason: the curse of dimensionality, i.e., nearest neighbors tend to be far away in high dimensions. We need to get a reasonable fraction of the \(N\) values of \(y_i\) to average to bring the variance down—e.g., 10%. A 10% neighborhood in high dimensions need no longer be local, so we lose the spirit of estimating \(E(Y |X = x)\) by local averaging, see Figure 18.9. If the curse of dimensionality does not exist, nearest neighbor models would be perfect prediction models.
We will use structured (parametric) models to deal with the curse of dimensionality. The linear model is an important example of a parametric model: \[
f_L(X) = \beta_0 + \beta_1 X_1 + \ldots + \beta_p X_p.
\] A linear model is specified in terms of \(p + 1\) parameters $ _1, _2, , _p$. We estimate the parameters by fitting the model to . Although it is almost never correct, a linear model often serves as a good and interpretable approximation to the unknown true function \(f(X)\).
The linear model is avoiding the curse of dimensionality, because it is not relying on any local properties. Linear models belong to the class of approaches: they replace the problem of estimating \(f\) with estimating a fixed set of coefficients \(\beta_i\), with \(i=1,2, \ldots, p\).
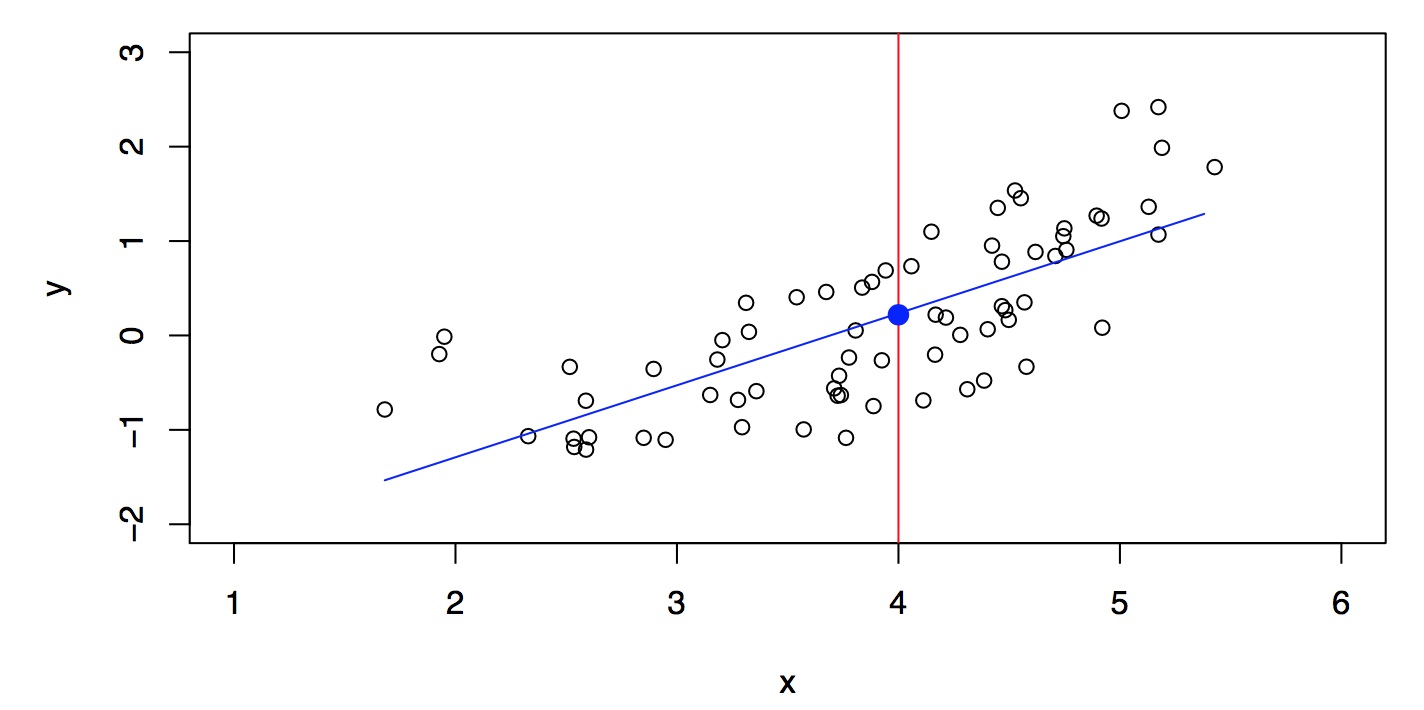
Figure 18.10: A linear model \(\hat{f}_L\) gives a reasonable fit. Taken from James et al. (2014)
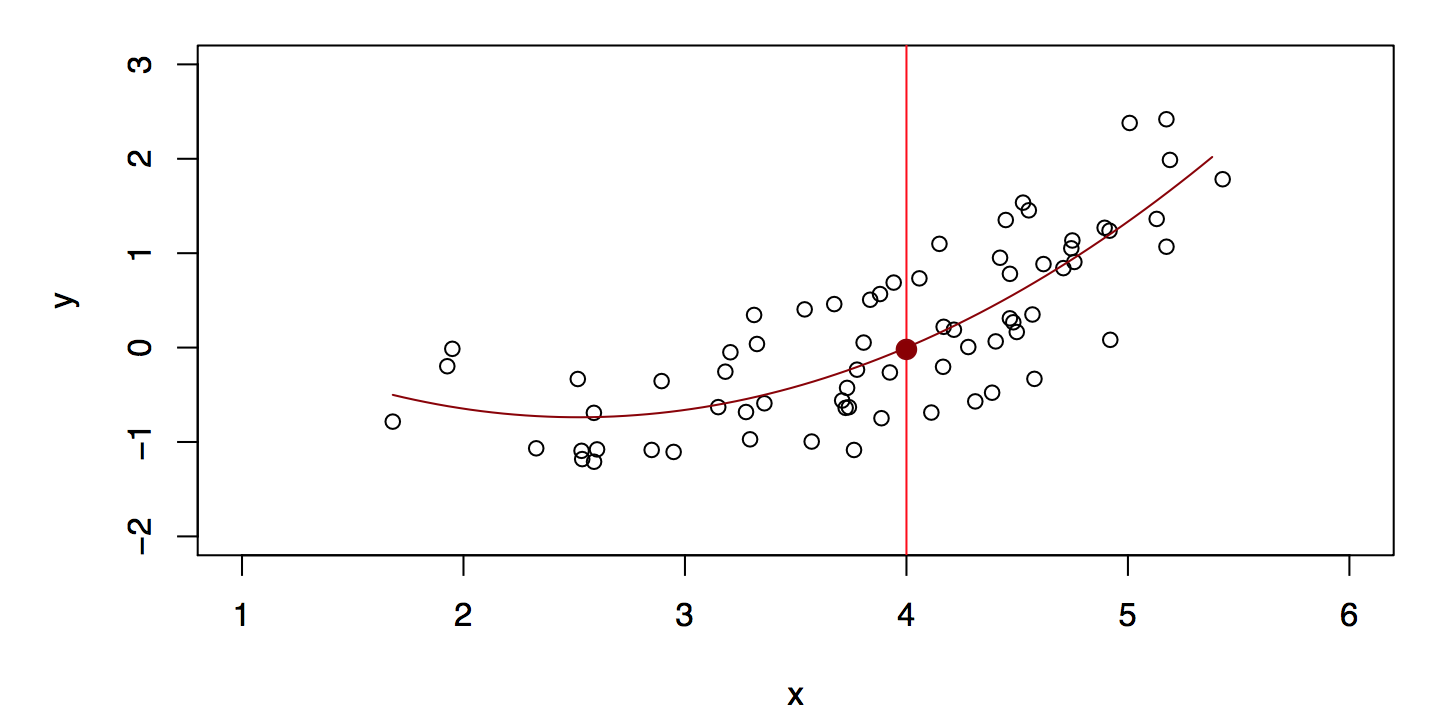
Figure 18.11: A quadratic model \(\hat{f}_Q\) fits slightly better. Taken from James et al. (2014)
A linear model \[
\hat{f}_L(X) = \hat{\beta}_0 + \hat{\beta}_1 X
\] gives a reasonable fit, see Figure 18.10. A quadratic model \[
\hat{f}_Q(X) = \hat{\beta}_0 + \hat{\beta}_1 X + \hat{\beta}_2 X^2
\] gives a slightly improved fit, see Figure 18.11.
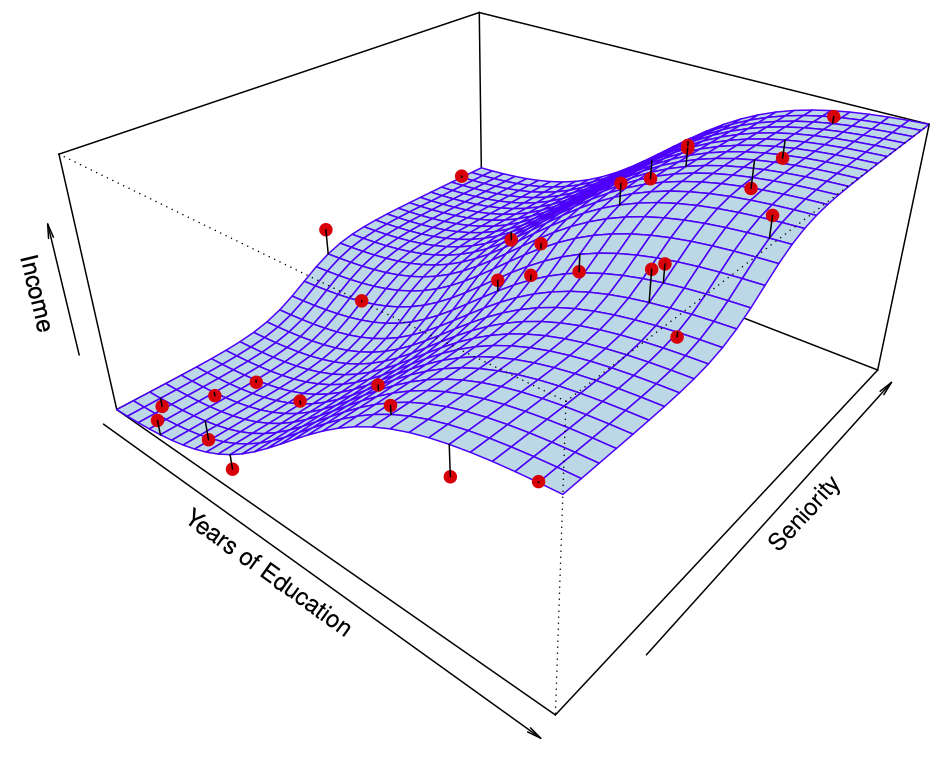
Figure 18.12 shows a simulated example. Red points are simulated values for income from the model \[
income = f(education, seniority) + \epsilon
\]\(f\) is the blue surface.
Figure 18.12: The true model. Red points are simulated values for income from the model, \(f\) is the blue surface. Taken from James et al. (2014)
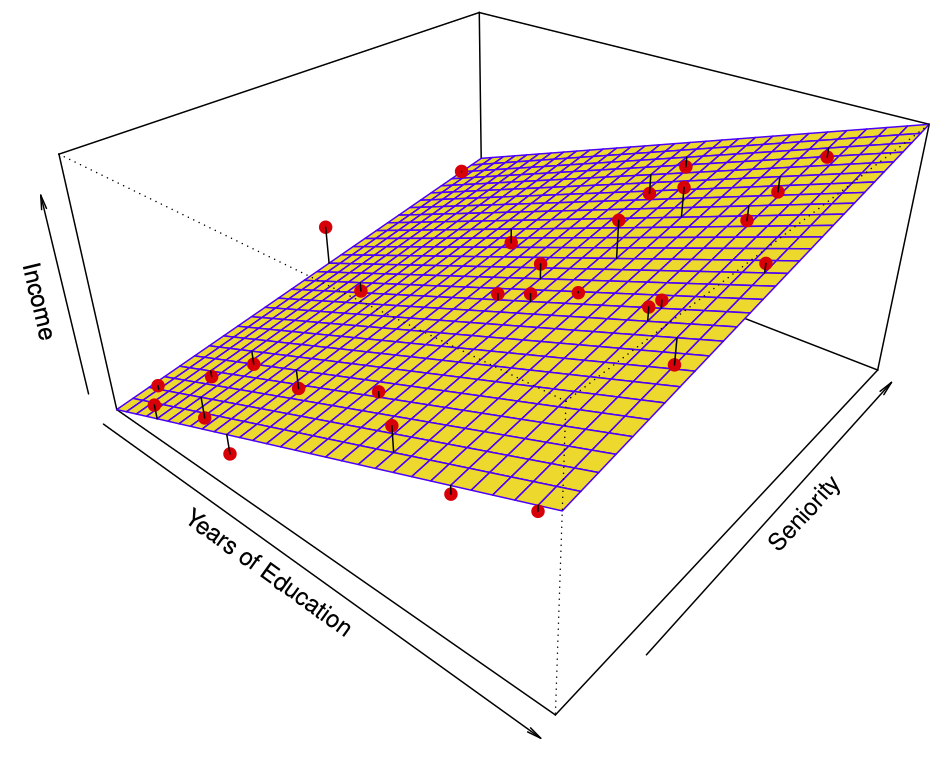
Figure 18.13: Linear regression fit to the simulated data (red points). Taken from James et al. (2014)
The linear regression model \[
\hat{f}(education, seniority) = \hat{\beta}_0 + \hat{\beta}_1 \times education +
\hat{\beta}_2 \times seniority
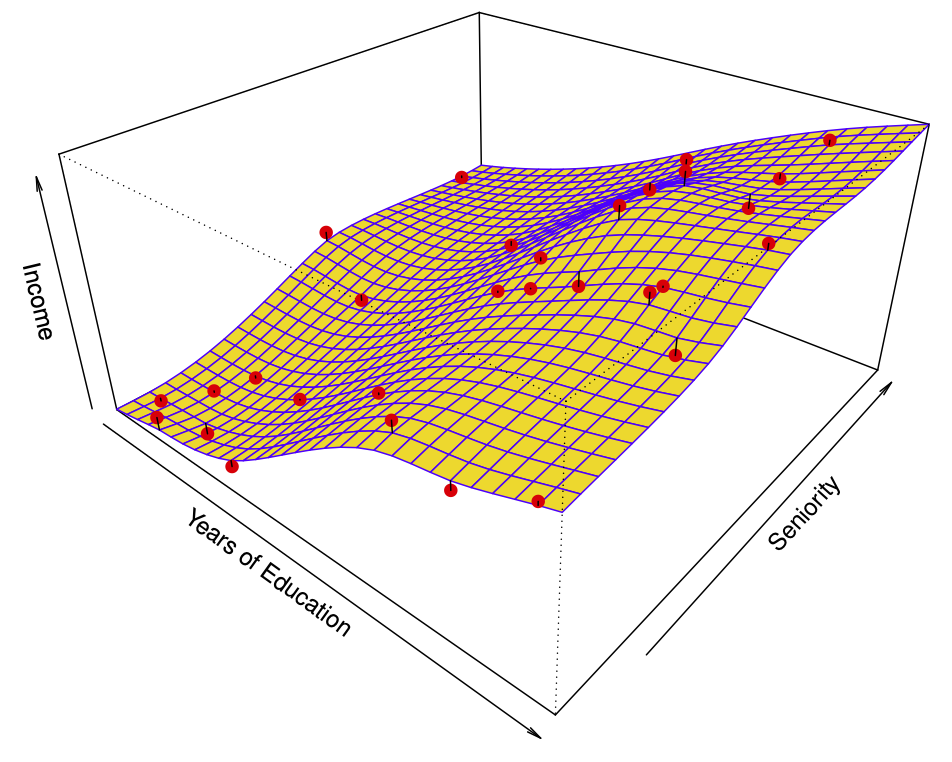
\] captures the important information. But it does not capture everything. More flexible regression model \[
\hat{f}_S (education, seniority)
\] fit to the simulated data. Here we use a technique called a thin-plate spline to fit a flexible surface. Even more flexible spline regression model \[
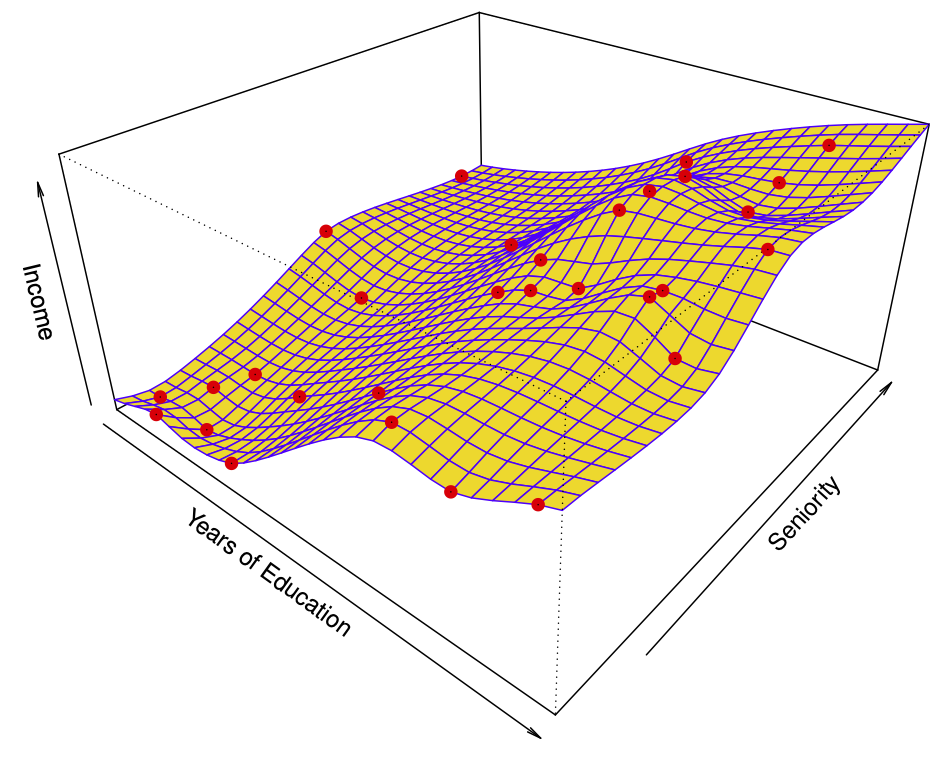
\hat{f}_S (education, seniority)
\] fit to the simulated data. Here the fitted model makes no errors on the training data! Also known as overfitting.
Figure 18.14: Thin-plate spline models \(\hat{f}_S (education, seniority)\) fitted to the model from Figure 18.12. Taken from James et al. (2014)
Figure 18.15: Thin-plate spline models \(\hat{f}_S (education, seniority)\) fitted to the model from Figure 18.12. The model makes no errors on the training data (overfitting). Taken from James et al. (2014)
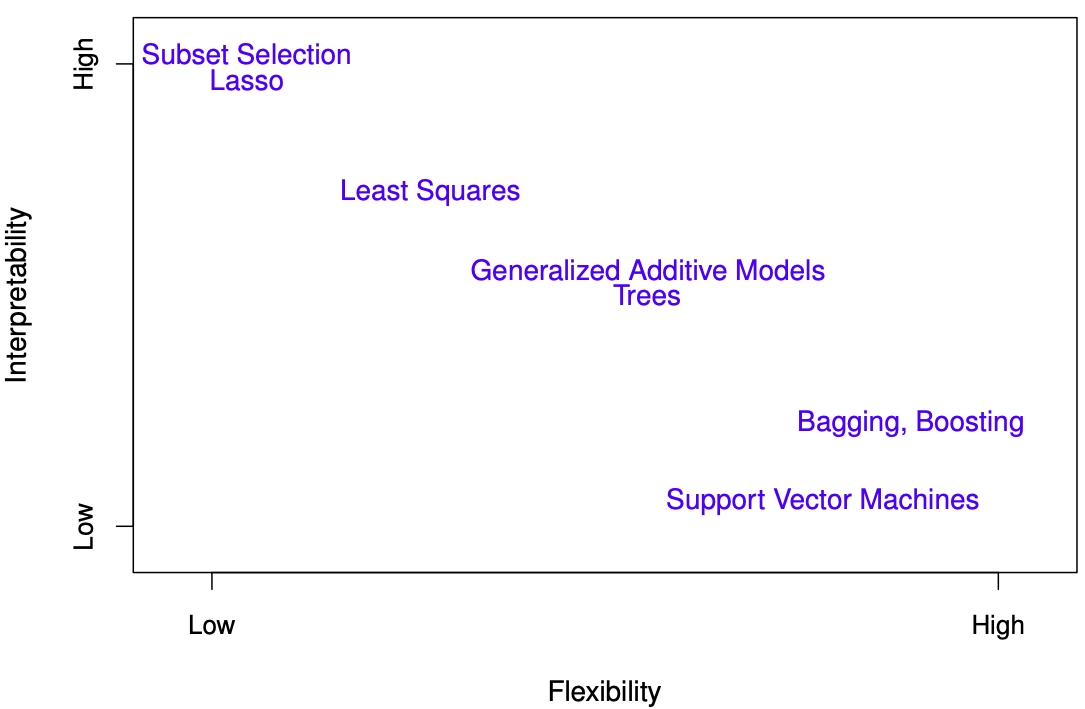
18.27.3.1 Trade-offs
Prediction accuracy versus interpretability: Linear models are easy to interpret; thin-plate splines are not.
Good fit versus over-fit or under-fit: How do we know when the fit is just right?
Parsimony (Occam’s razor) versus black-box: We often prefer a simpler model involving fewer variables over a black-box predictor involving them all.
Figure 18.16: Interpretability versus flexibility. Flexibility corresponds with the number of model parameters. Taken from James et al. (2014)
18.27.4 Assessing Model Accuracy and Bias-Variance Trade-off
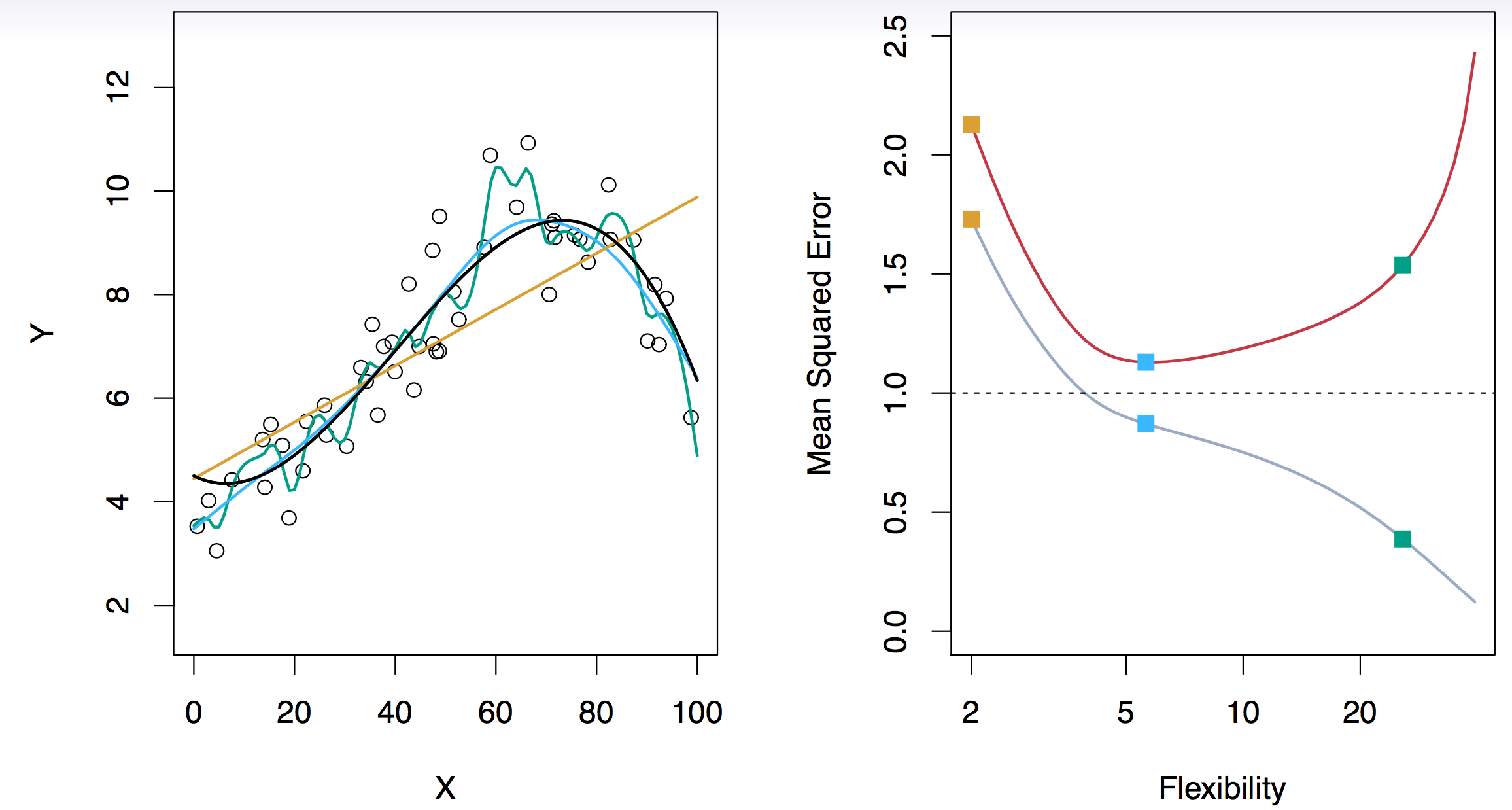
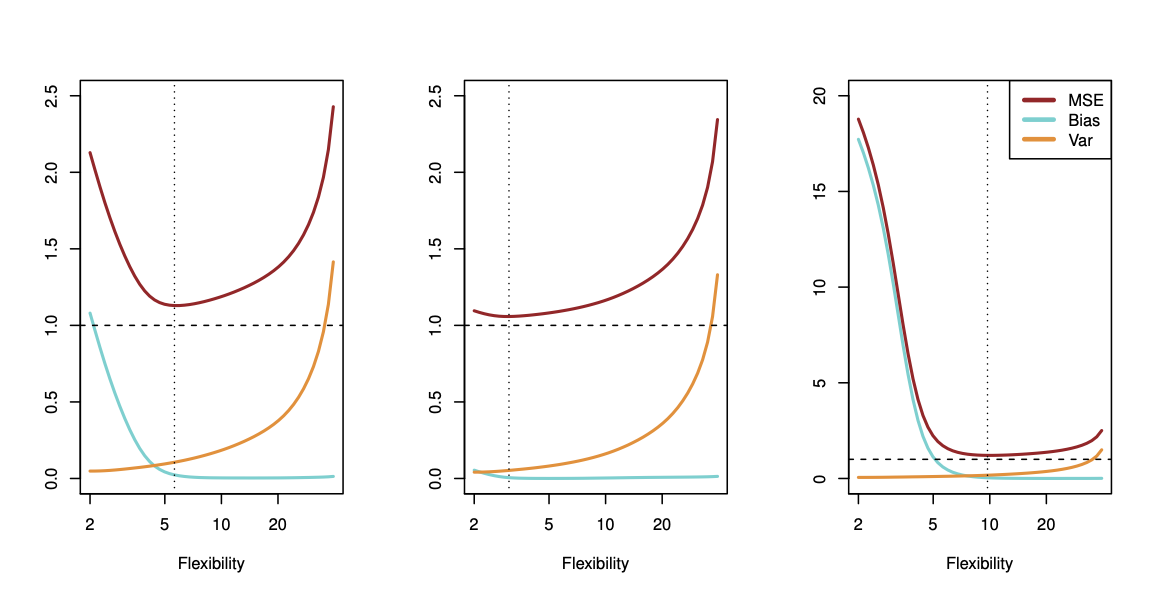
Figure 18.17: Black curve is truth. Red curve on right is \(MSETe\), grey curve is \(MSETr\). Orange, blue and green curves/squares correspond to fits of different flexibility. The dotted line represents the irreducible error, i.e., \(var(\epsilon)\). Taken from James et al. (2014)
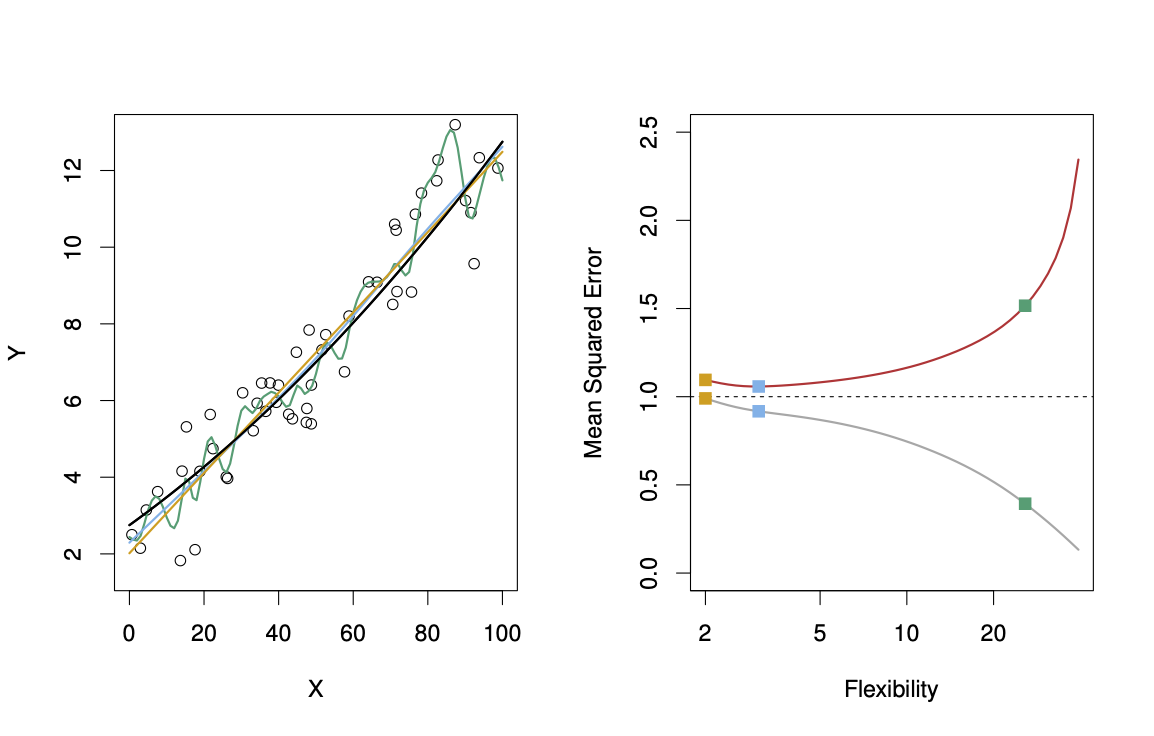
Figure 18.18: Here, the truth is smoother. Black curve is truth. Red curve on right is \(MSETe\), grey curve is \(MSETr\). Orange, blue and green curves/squares correspond to fits of different flexibility. The dotted line represents the irreducible error, i.e., \(var(\epsilon)\). Taken from James et al. (2014)
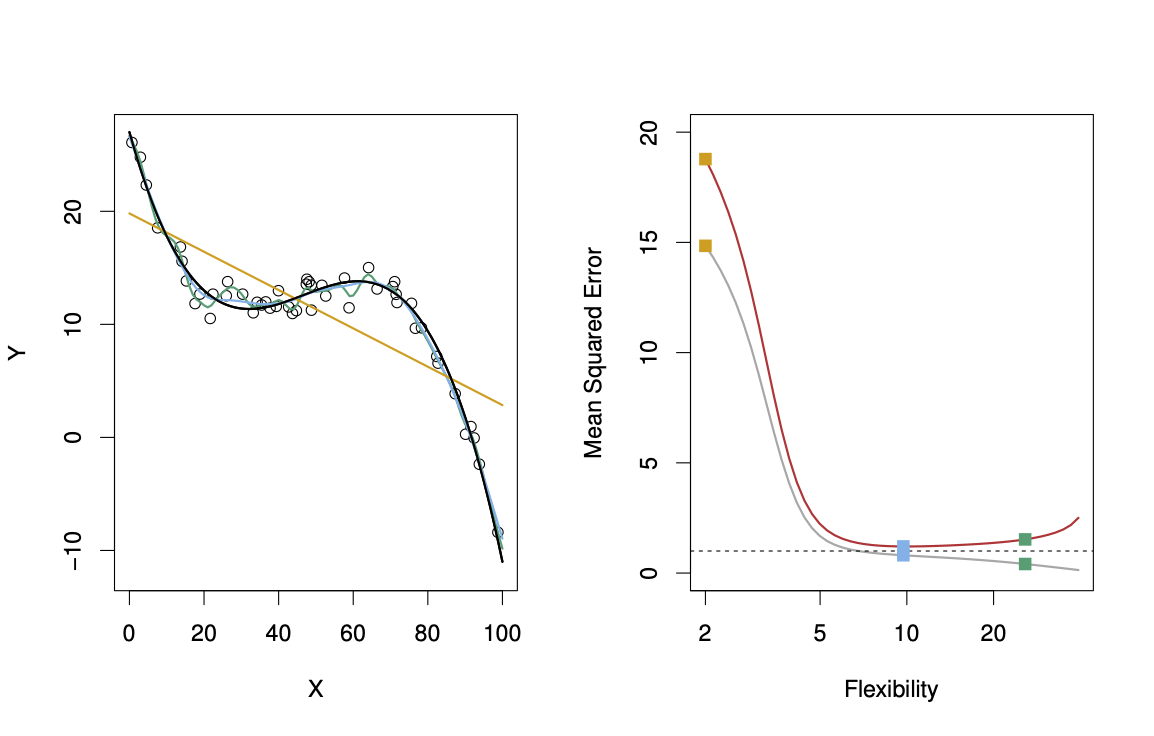
Figure 18.19: Here the truth is wiggly and the noise is low, so the more flexible fits do the best. Black curve is truth. Red curve on right is \(MSETe\), grey curve is \(MSETr\). Orange, blue and green curves/squares correspond to fits of different flexibility. The dotted line represents the irreducible error, i.e., \(var(\epsilon)\). Taken from James et al. (2014)
Suppose we fit a model \(f(x)\) to some training data \(Tr = \{x_i, y_i \}^N_1\), and we wish to see how well it performs. We could compute the average squared prediction error over \(Tr\): \[
MSE_{Tr} = Ave_{i \in Tr}[y_i - \hat{f}(x_i)]^2.
\] This may be biased toward more overfit models. Instead we should, if possible, compute it using fresh test data\(Te== \{x_i, y_i \}^N_1\): \[
MSE_{Te} = Ave_{i \in Te}[y_i - \hat{f}(x_i)]^2.
\] The red curve, which illustrated the test error, can be estimated by holding out some data to get the test-data set.
18.27.4.1 Bias-Variance Trade-off
Suppose we have fit a model \(f(x)\) to some training data \(Tr\), and let \((x_0, y_0)\) be a test observation drawn from the population. If the true model is \[
Y = f(X) + \epsilon \qquad \text{ with } f(x) = E(Y|X=x),
\] then \[
E \left( y_0 - \hat{f}(x_0) \right)^2 = \text{var} (\hat{f}(x_0)) + [Bias(\hat{f}(x_0))]^2 + \text{var}(\epsilon).
\tag{18.2}\]
Here, \(\text{var}(\epsilon)\) is the irreducible error. The reducible error consists of two components:
\(\text{var} (\hat{f}(x_0))\) is the variance that comes from different training sets. Different training sets result in different functions \(\hat{f}\).
The expectation averages over the variability of \(y_0\) as well as the variability in \(Tr\). Note that \[
Bias(\hat{f}(x_0)) = E[\hat{f}(x_0)] - f(x_0).
\] Typically as the flexibility of \(\hat{f}\) increases, its variance increases (because the fits differ from training set to trainig set), and its bias decreases. So choosing the flexibility based on average test error amounts to a bias-variance trade-off, see Figure 18.20.
Figure 18.20: Bias-variance trade-off for the three examples. Taken from James et al. (2014)
If we add the two components (reducible and irreducible error), we get the MSE in Figure 18.20 as can be seen in Equation 18.2.
18.27.5 Classification Problems and K-Nearest Neighbors
In classification we have a qualitative response variable.
Figure 18.21: Classification. Taken from James et al. (2014)
Here the response variable \(Y\) is qualitative, e.g., email is one of \(\cal{C} = (spam, ham)\), where ham is good email, digit class is one of \(\cal{C} = \{ 0, 1, \ldots, 9 \}\). Our goals are to:
Build a classifier \(C(X)\) that assigns a class label from \(\cal{C}\) to a future unlabeled observation \(X\).
Assess the uncertainty in each classification
Understand the roles of the different predictors among \(X = (X_1,X_2, \ldots, X_p)\).
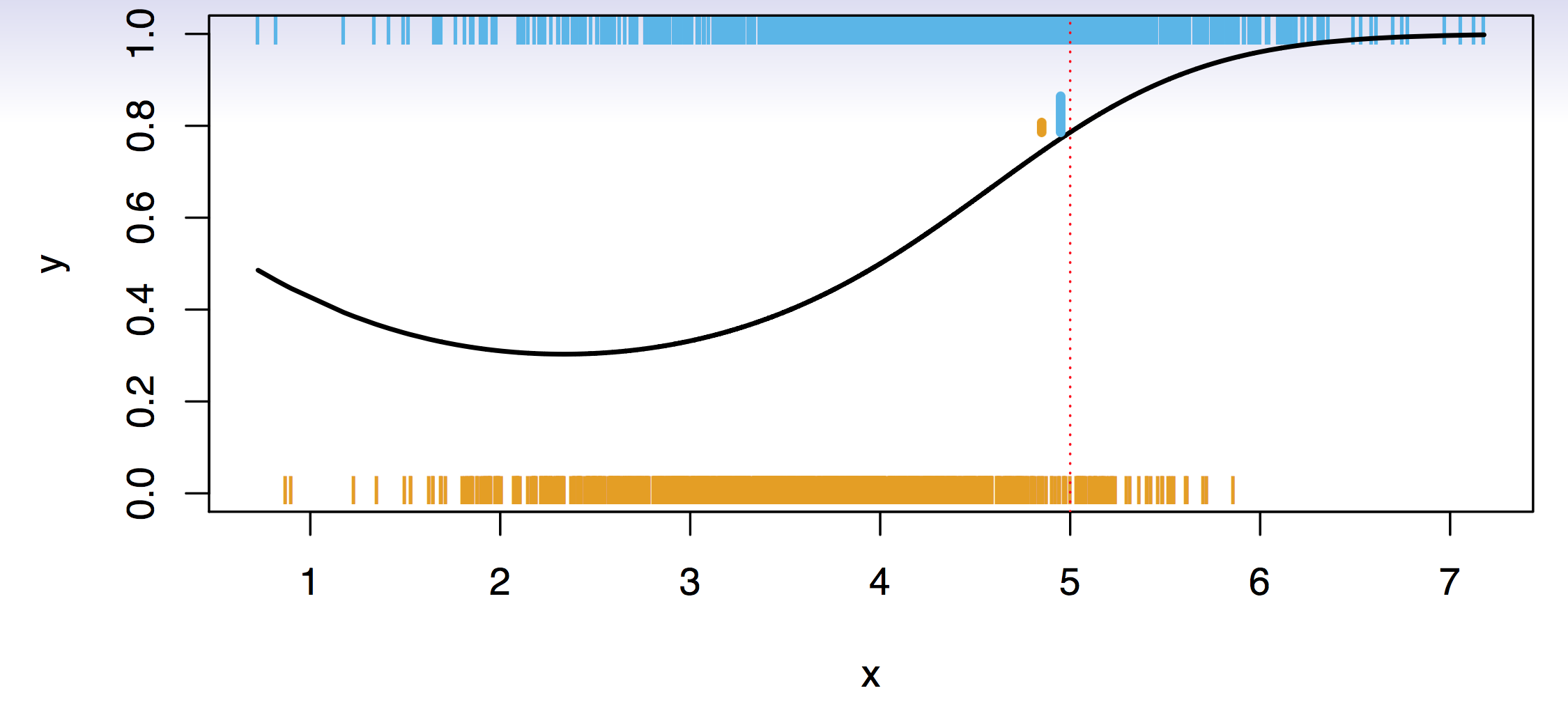
Simulation example depicted in@fig-0218a. \(Y\) takes two values, zero and one, and \(X\) has only one value. Big sample: each single vertical bar indicates an occurrance of a zero (orange) or one (blue) as a function of the \(X\)s. Black curve generated the data: it is the probability of generating a one. For high values of \(X\), the probability of ones is increasing. What is an ideal classifier \(C(X)\)?
Suppose the \(K\) elements in \(\cal{C}\) are numbered \(1,2,\ldots, K\). Let \[
p_k(x) = Pr(Y = k|X = x), k = 1,2,\ldots,K.
\]
These are the conditional class probabilities at \(x\); e.g. see little barplot at \(x = 5\). Then the Bayes optimal classifier at \(x\) is \[
C(x) = j \qquad \text{ if } p_j(x) = \max \{p_1(x),p_2(x),\ldots, p_K(x)\}.
\] At \(x=5\) there is an 80% probability of one, and an 20% probability of a zero. So, we classify this point to the class with the highest probability, the majority class.
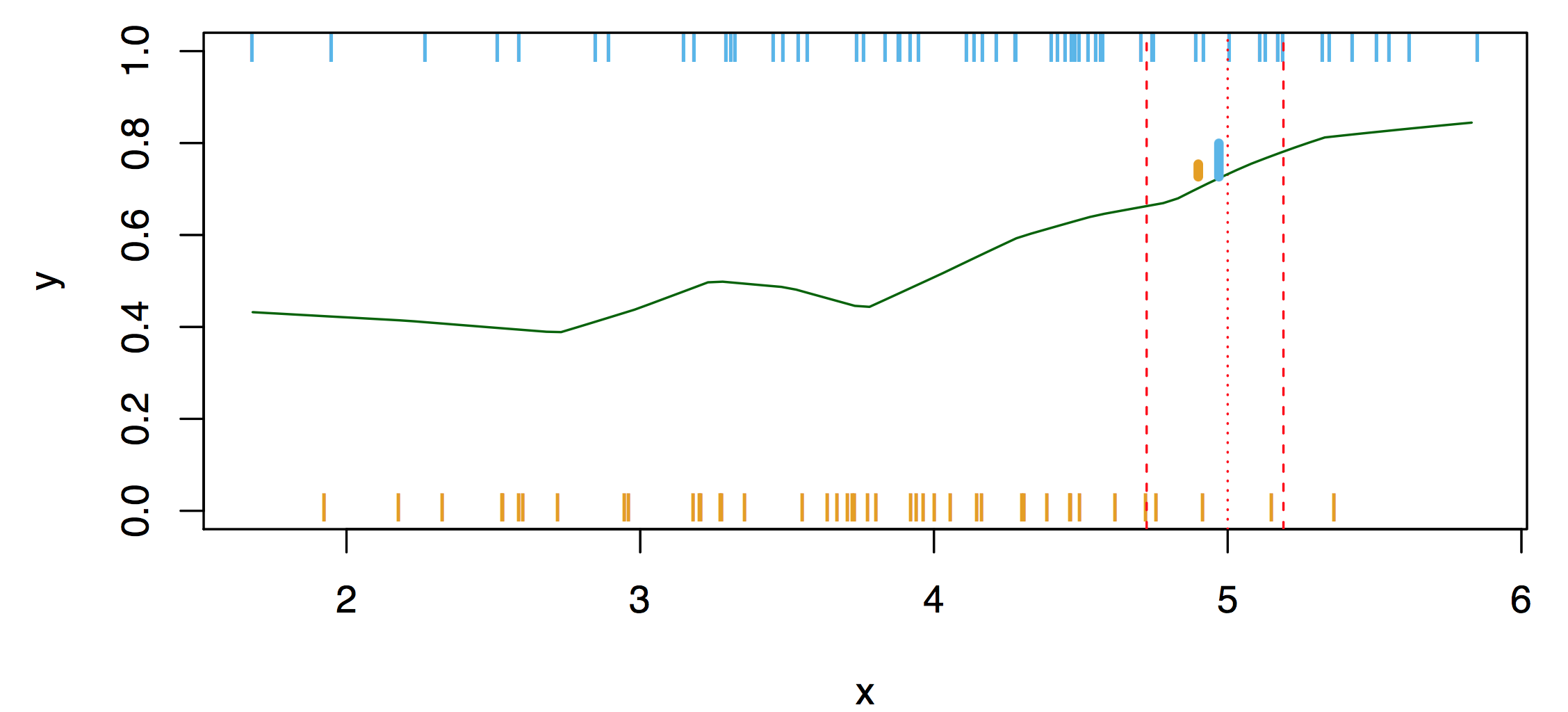
Nearest-neighbor averaging can be used as before. This is illustrated in Fig.~\(\ref{fig:0219a}\). Here, we consider 100 points only. Nearest-neighbor averaging also breaks down as dimension grows. However, the impact on \(\hat{C}(x)\) is less than on \(\hat{p}_k (x)\), \(k = 1, \ldots, K\).
Figure 18.22: Classification. Taken from James et al. (2014)
18.27.5.1 Classification: Some Details
Average number of errors made to measure the performance. Typically we measure the performance of \(\hat{C}(x)\) using the misclassification error rate: \[
Err_{Te} = Ave_{i\in Te} I[y_i \neq \hat{C} (x_i) ].
\] The Bayes classifier (using the true \(p_k(x)\)) has smallest error (in the population).
18.27.6 k-Nearest Neighbor Classification
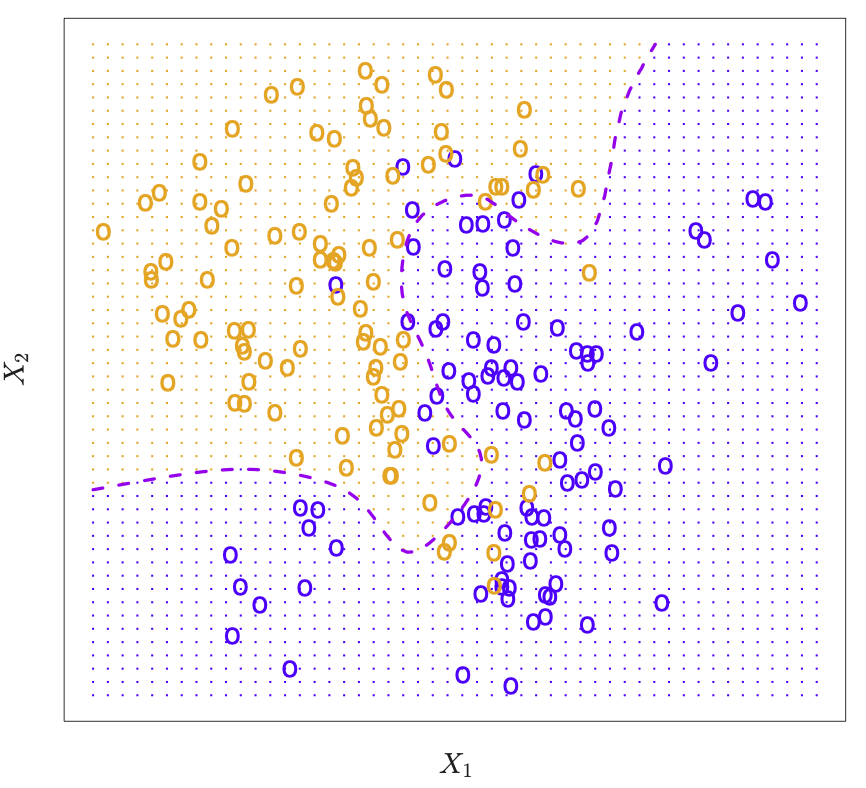
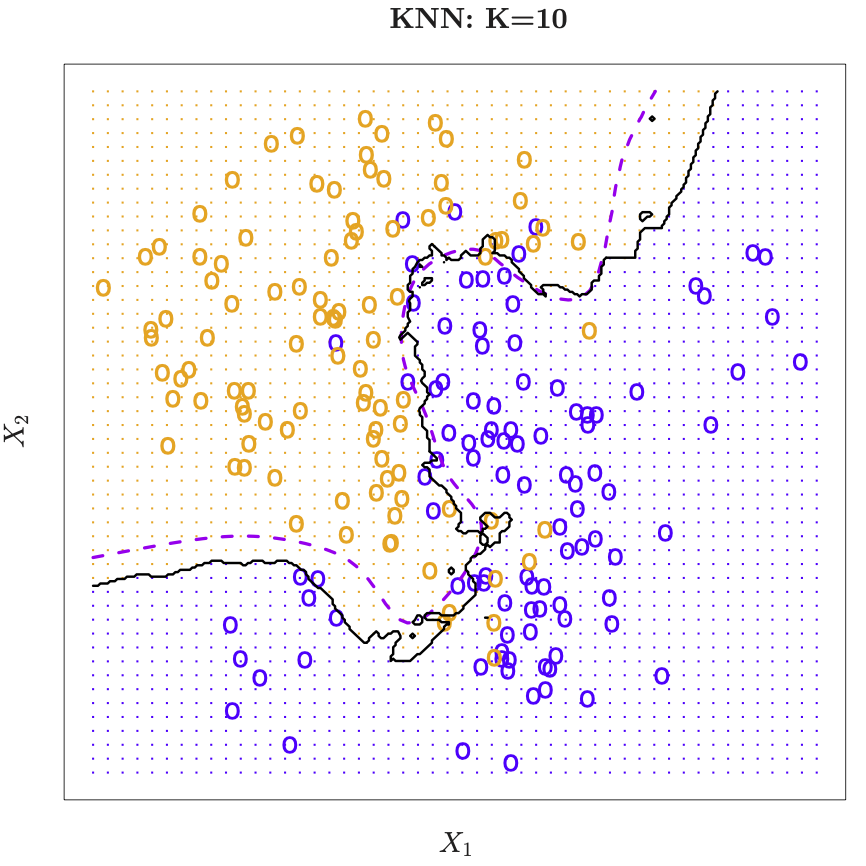
Consider k-nearest neighbors in two dimensions. Orange and blue dots label the true class memberships of the underlying points in the 2-dim plane. Dotted line is the decision boundary, that is the contour with equal probability for both classes.
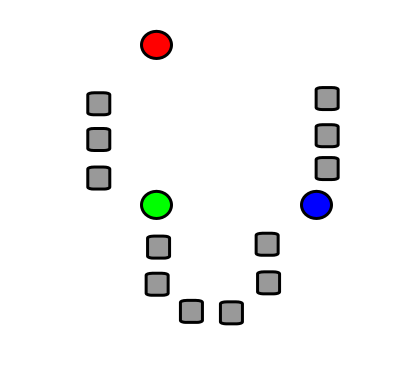
Nearest-neighbor averaging in 2-dim. At any given point we want to classify, we spread out a little neighborhood, say \(K=10\) points from the neighborhood and calulated the percentage of blue and orange. We assign the color with the highest probability to this point. If this is done for every point in the plane, we obtain the solid black curve as the esitmated decsion boundary.
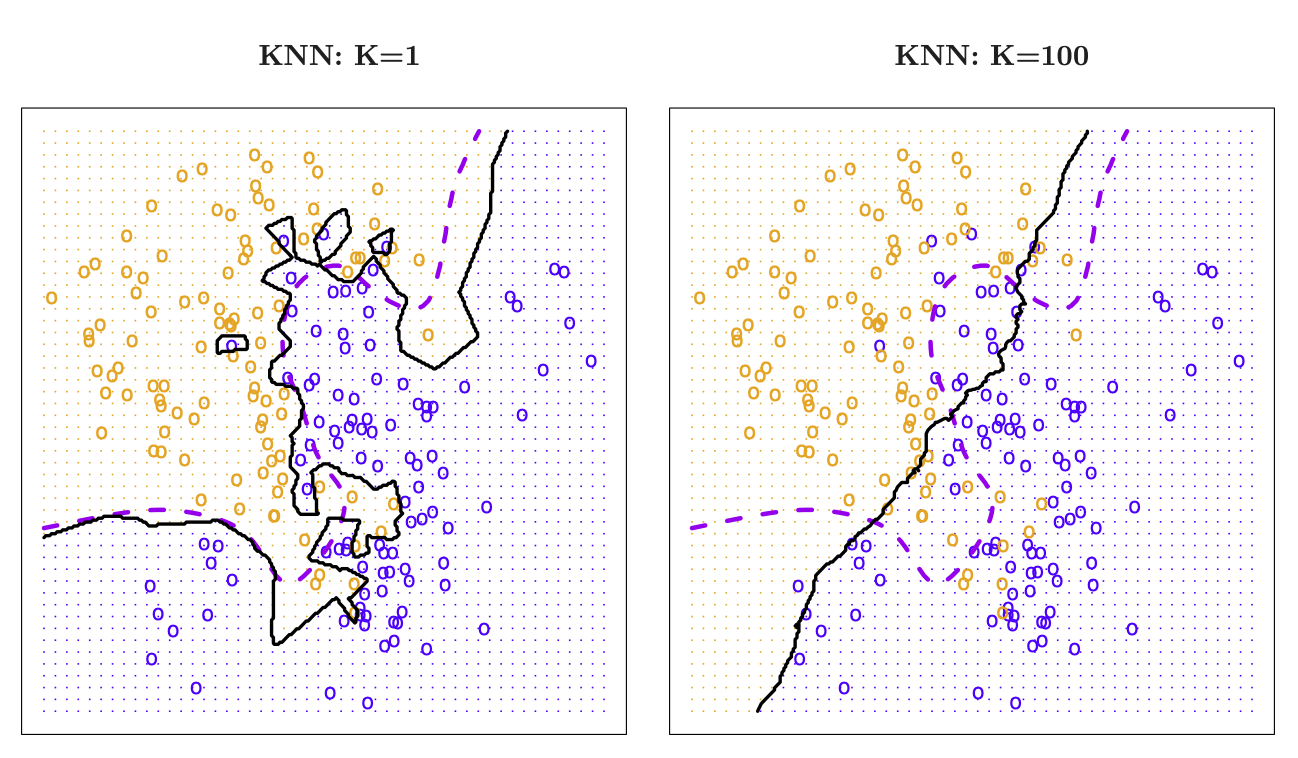
We can use \(K=1\). This is the nearest-neighbor classifier. The decision boundary is piecewise linear. Islands occur. Approximation is rather noisy.
\(K=100\) leads to a smooth decision boundary. But gets uninteresting.
Figure 18.23: K-nearest neighbors in two dimensions. Taken from James et al. (2014)
Figure 18.24: K-nearest neighbors in two dimensions. Taken from James et al. (2014)
Figure 18.25: K-nearest neighbors in two dimensions. Taken from James et al. (2014)
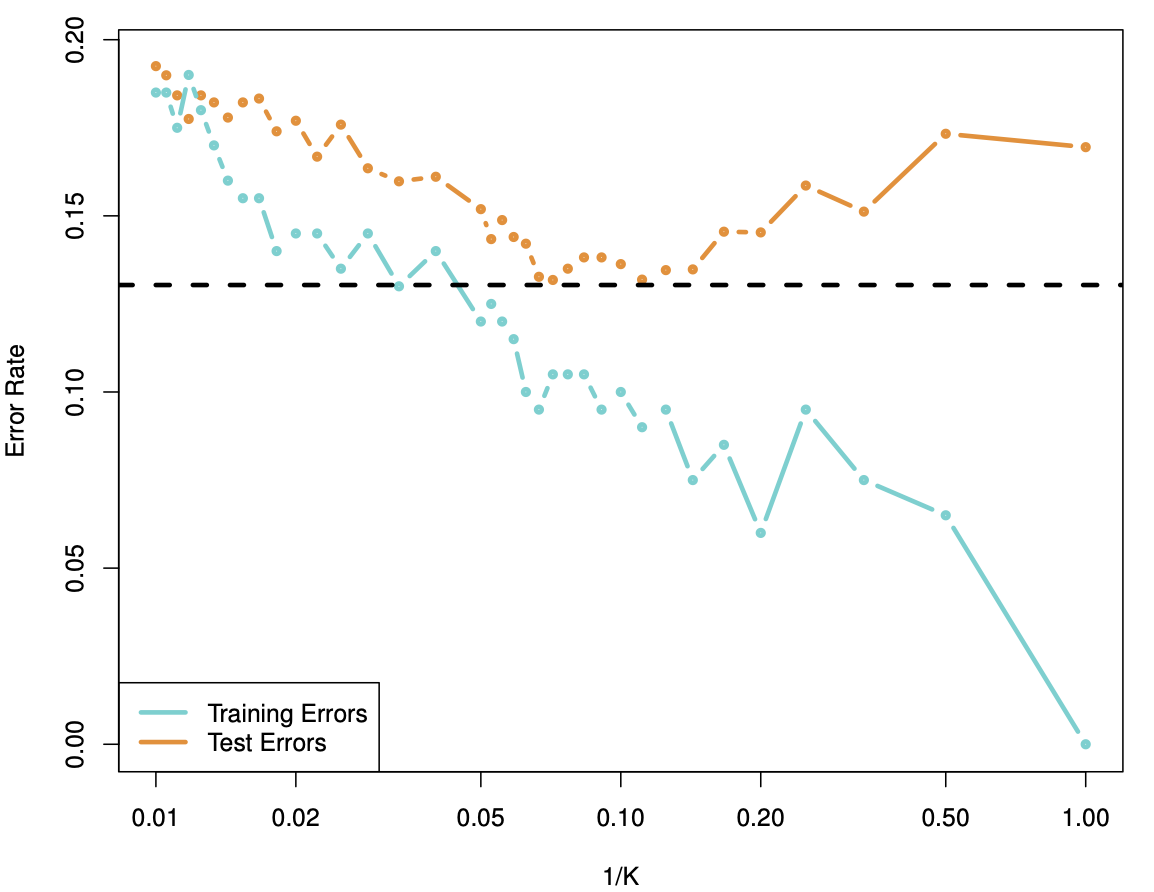
\(K\) large means higher bias, so \(1/K\) is chosen, because we go from low to high complexity on the \(x\)-error, see Figure 18.26. Horizontal dotted line is the base error.
Figure 18.26: K-nearest neighbors classification error. Taken from James et al. (2014)
18.27.7 Minkowski Distance
The Minkowski distance of order \(p\) (where \(p\) is an integer) between two points \(X=(x_1,x_2,\ldots,x_n)\text{ and }Y=(y_1,y_2,\ldots,y_n) \in \mathbb{R}^n\) is defined as: \[
D \left( X,Y \right) = \left( \sum_{i=1}^n |x_i-y_i|^p \right)^\frac{1}{p}.
\]
18.27.8 Unsuperivsed Learning: Classification
18.27.8.1 k-Means Algorithm
The \(k\)-means algorithm is an unsupervised learning algorithm that has a loose relationship to the \(k\)-nearest neighbor classifier. The \(k\)-means algorithm works as follows:
Step 1: Randomly choose \(k\) centers. Assign points to cluster.
Step 2: Determine the distances of each data point to the centroids and re-assign each point to the closest cluster centroid based upon minimum distance
Step 3: Calculate cluster centroids again
Step 4: Repeat steps 2 and 3 until we reach global optima where no improvements are possible and no switching of data points from one cluster to other.
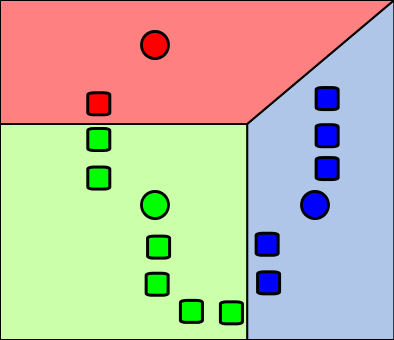
Figure 18.27: k-means algorithm. Step 1. Randomly choose \(k\) centers. Assign points to cluster. \(k\) initial means(in this case \(k=3\)) are randomly generated within the data domain (shown in color). Attribution: I, Weston.pace, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons
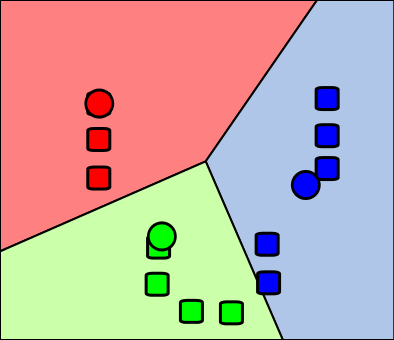
Figure 18.28: k-means algorithm. Step 2. \(k\) clusters are created by associating every observation with the nearest mean. The partitions here represent the Voronoi diagram generated by the means. Attribution: I, Weston.pace, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons
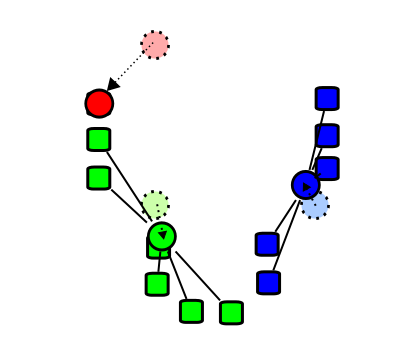
Figure 18.29: k-means algorithm. Step 3. The centroid of each of the \(k\) clusters becomes the new mean. Attribution: I, Weston.pace, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons
Figure 18.30: k-means algorithm. Step 4. Steps 2 and 3 are repeated until convergence has been reached. Attribution: I, Weston.pace, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons
Chollet, Francoise, and J. J. Allaire. 2018. Deep Learning with Python. Manning.
Hartung, Joachim, Bärbel Elpert, and Karl-Heinz Klösener. 1995. Statistik. Oldenbourg.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2014. An Introduction to Statistical Learning with Applications in R. 7th ed. Springer.