Pareto fronts, desirability functions, and multi-objective test problems.
spotoptim supports multi-objective optimization through Pareto efficiency analysis, a library of standard test functions, and a scalarization mechanism that lets the surrogate-based optimizer handle vector-valued objectives.
Pareto Efficiency
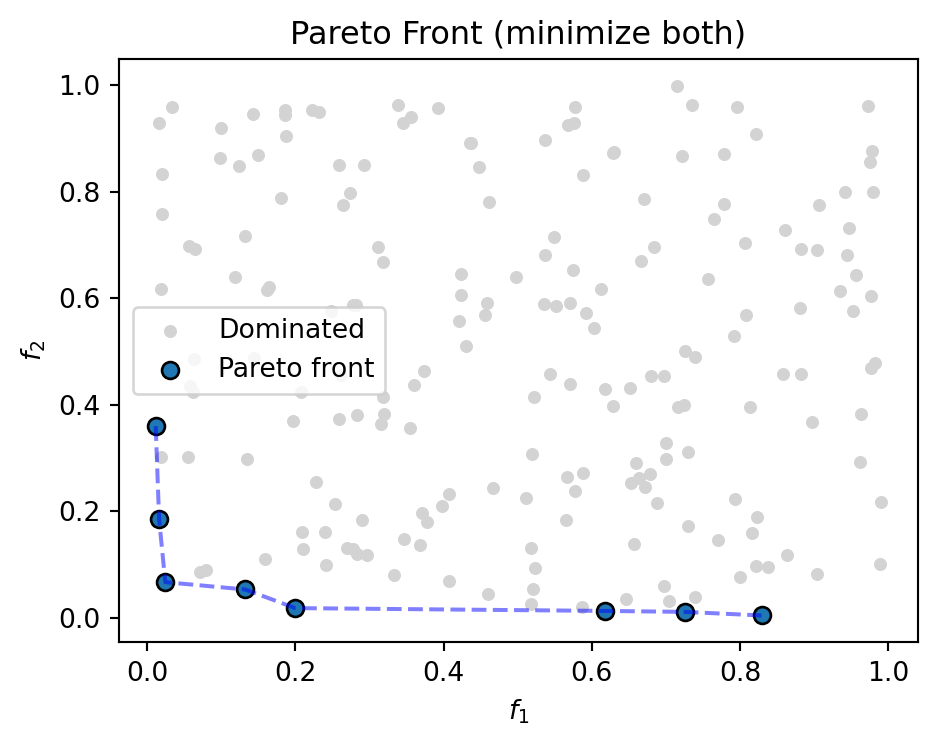
A solution is Pareto-efficient when no other solution improves one objective without worsening another. The is_pareto_efficient function accepts an \((N, M)\) cost array and returns a boolean mask identifying the non-dominated points.
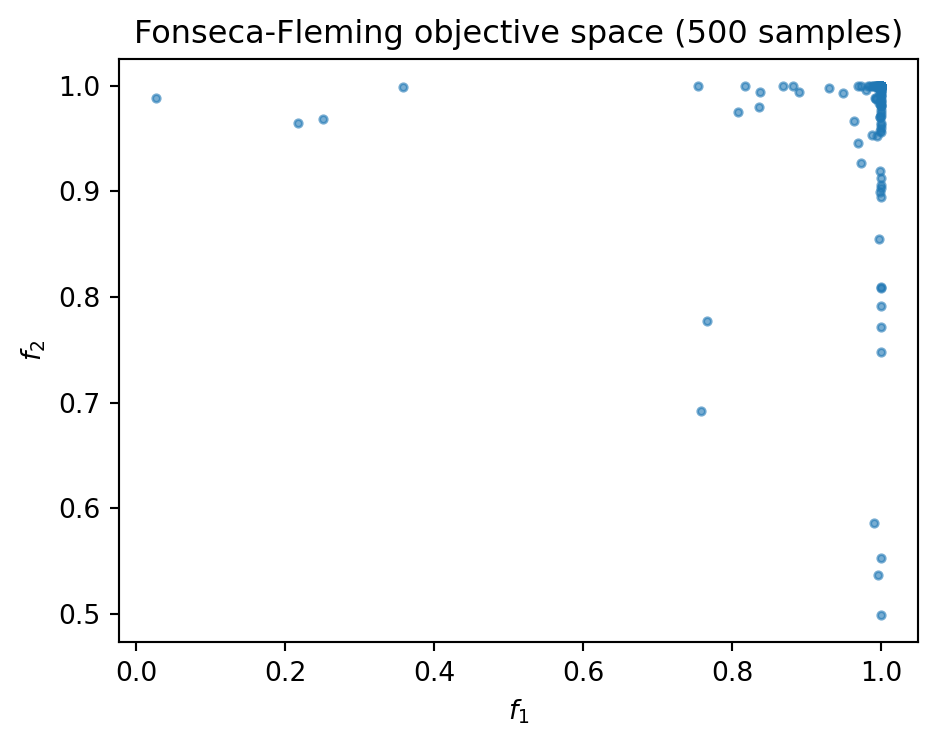
spotoptim ships with several classical bi-objective test functions in spotoptim.function. Each accepts an input array of shape \((n_\text{samples},\; n_\text{features})\) and returns objectives of shape \((n_\text{samples},\; 2)\).
SpotOptim optimizes a scalar surrogate internally. When the objective function returns multiple columns, the fun_mo2so parameter converts the \((n_\text{samples},\; n_\text{objectives})\) array into a single-objective \((n_\text{samples},)\) vector before fitting the surrogate.
If fun_mo2so is omitted the first column is used by default.
Weighted-sum scalarization
The simplest aggregation is a weighted sum. Here we optimize fonseca_fleming with equal weights:
Best x : [-0.67689129 -0.67698069]
Best scalarized: 0.490067
Evaluations : 30
Changing the weight vector traces different regions of the Pareto front. For example, np.array([0.8, 0.2]) emphasizes the first objective while np.array([0.2, 0.8]) emphasizes the second.
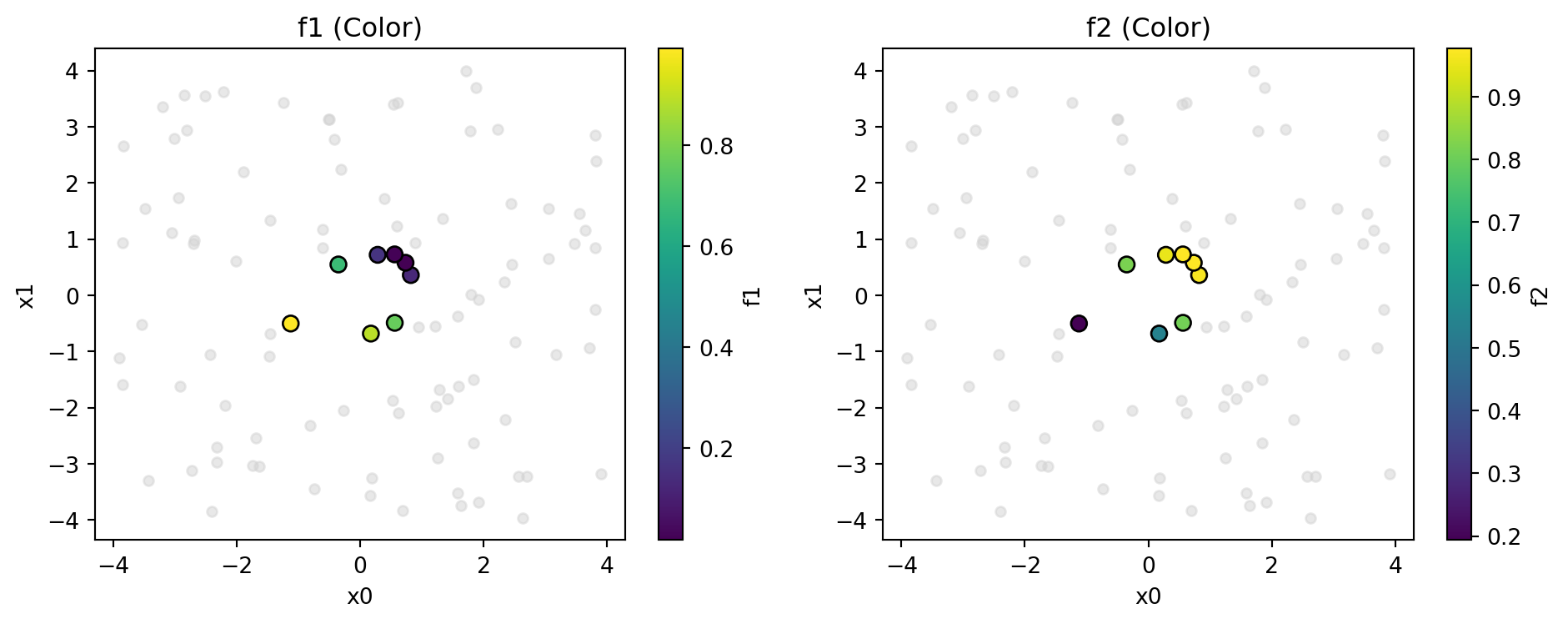
mo_pareto_optx_plot from spotoptim.mo.pareto visualizes Pareto-optimal points in the input space. For each pair of input variables \((x_i, x_j)\) and each objective \(f_k\), it produces a scatter plot where Pareto points are highlighted and colored by their objective value.
import numpy as npimport matplotlib.pyplot as pltfrom spotoptim.function import fonseca_flemingfrom spotoptim.mo.pareto import mo_pareto_optx_plotnp.random.seed(0)X = np.random.uniform(-4, 4, size=(100, 2))Y = fonseca_fleming(X)mo_pareto_optx_plot( X, Y, minimize=True, feature_names=["x0", "x1"], target_names=["f1", "f2"],)print("Pareto-optimal input-space visualization complete.")
The module also provides mo_xy_contour and mo_xy_surface for plotting surrogate predictions across objectives. Both accept a list of fitted models together with bounds and produce contour or 3-D surface grids.