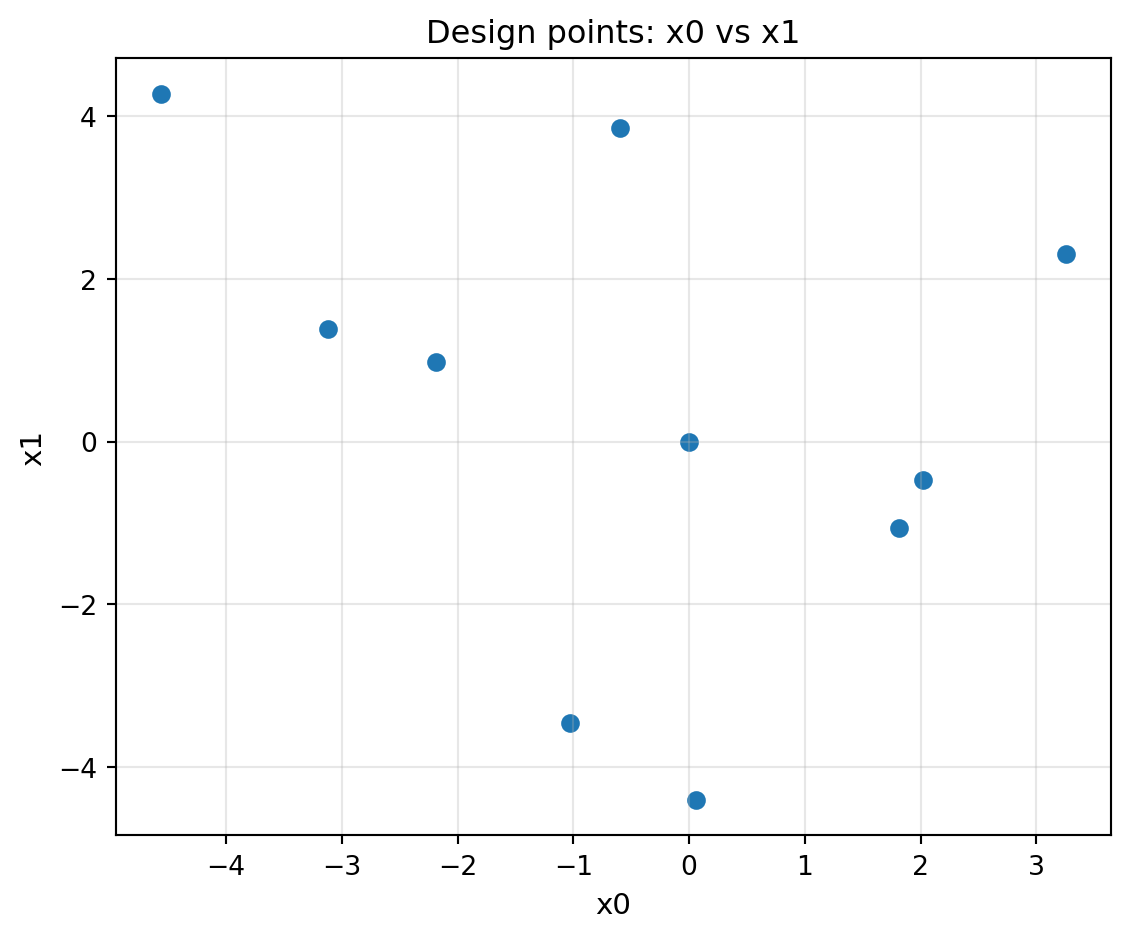
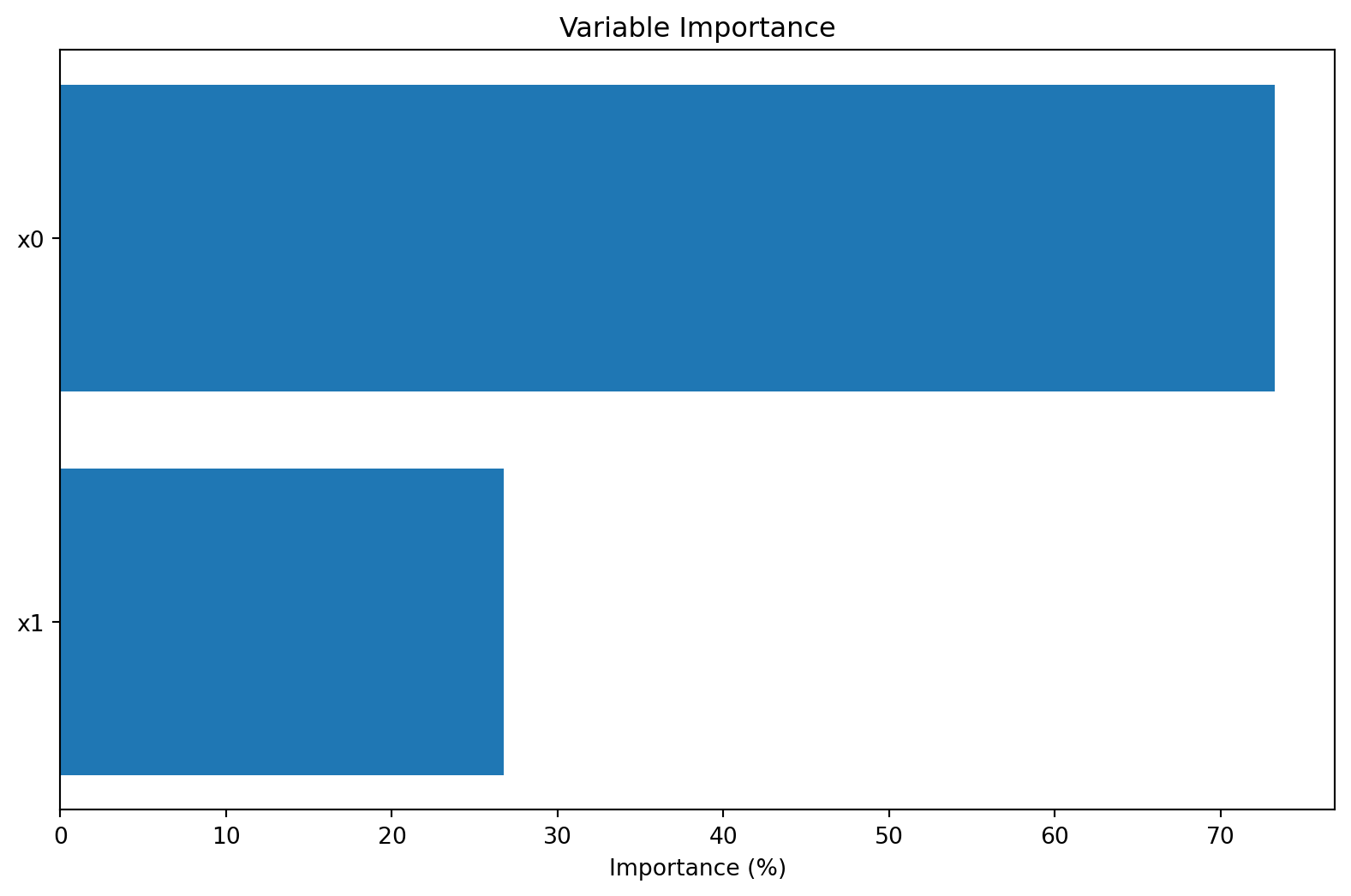
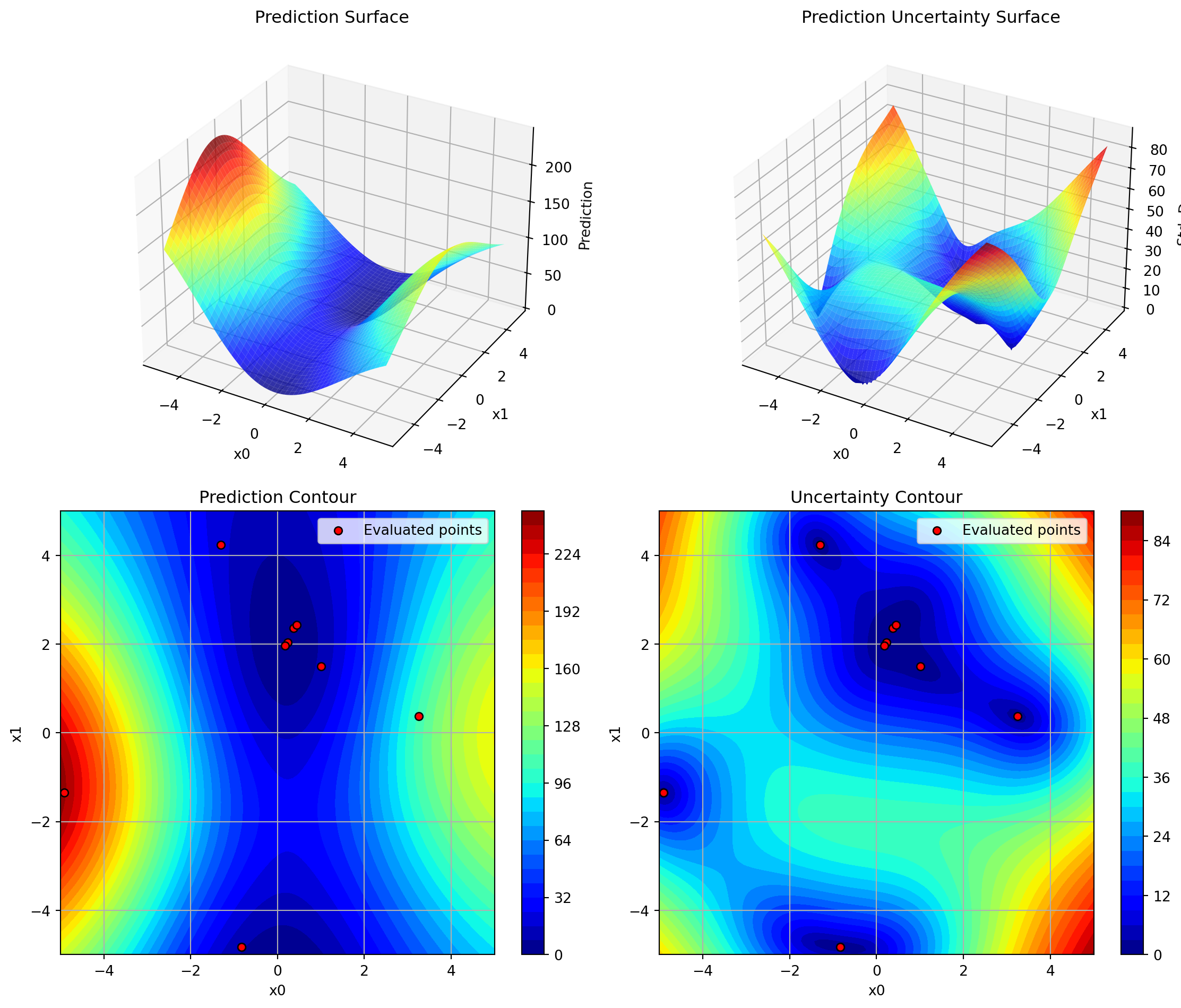
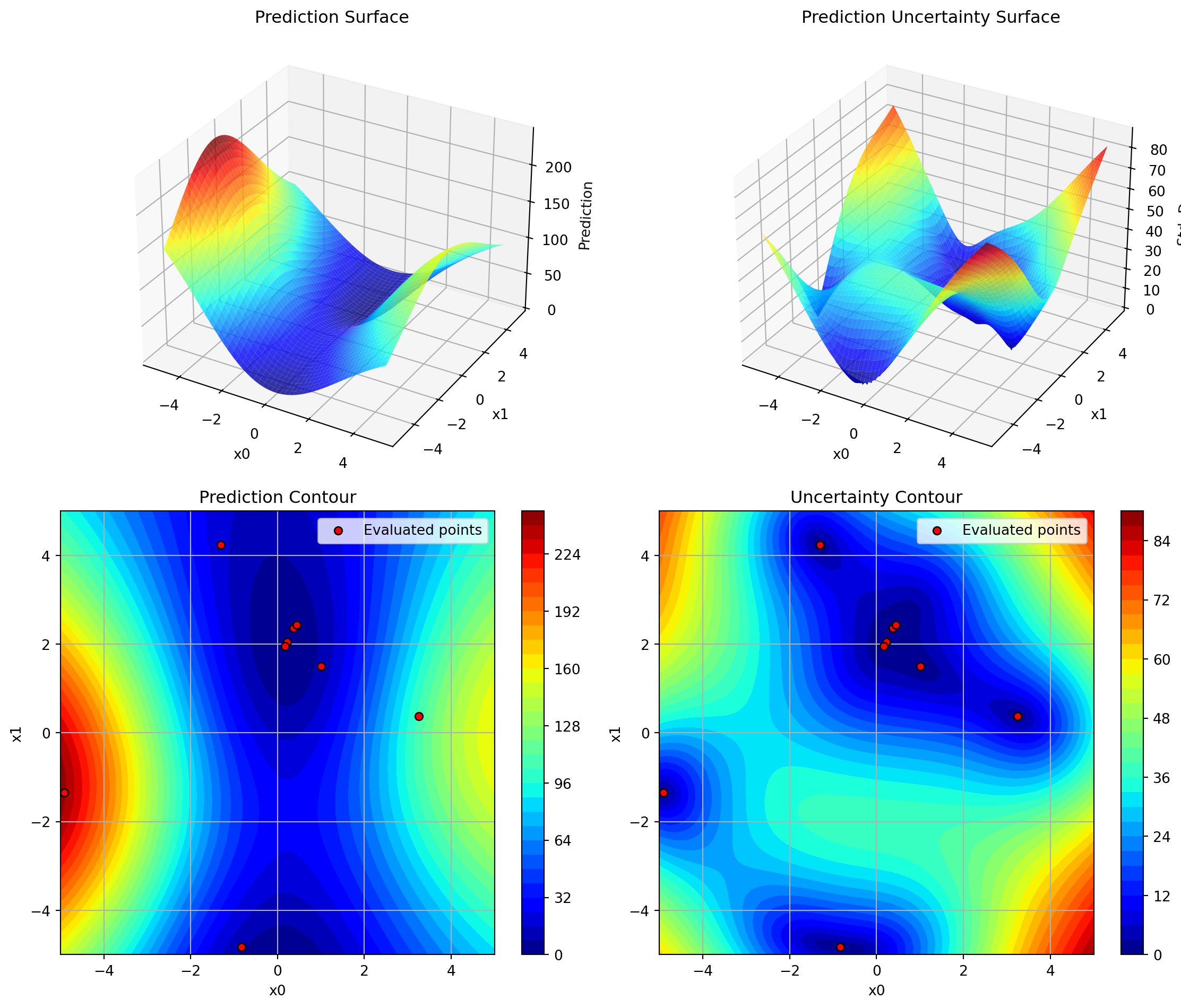
Maximum number of total function evaluations (including initial design). For example, max_iter=30 with n_initial=10 will perform 10 initial evaluations plus 20 sequential optimization iterations. Defaults to 20.
Number of initial design points. Defaults to 10. A UserWarning is raised when n_initial < 2 * n_dim: a cold-start design that small tends to under-sample the search space and gives the surrogate too little signal to model dimension interactions. The warning is guidance only (existing scripts with a deliberately small n_initial keep working unchanged); consider n_initial=max(10, 2 * n_dim) for cold starts.
Surrogate model with scikit-learn interface (fit/predict methods). If None, uses a Gaussian Process Regressor with Matern kernel. Default configuration:: * from sklearn.gaussian_process import GaussianProcessRegressor * from sklearn.gaussian_process.kernels import Matern, ConstantKernel * kernel = ConstantKernel(1.0, (1e-2, 1e12)) * Matern(length_scale=1.0, length_scale_bounds=(1e-4, 1e2), nu=2.5) * surrogate = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=100) Alternative surrogates can be provided, including SpotOptim’s Kriging model, Random Forests, or any scikit-learn compatible regressor. See Examples section. Defaults to None (uses default Gaussian Process configuration).
Acquisition function (‘ei’, ‘y’, ‘pi’). Defaults to ‘y’.
'y'
var_type
list of str
Variable types for each dimension. Supported types: * ‘float’: Python floats, continuous optimization (no rounding) * ‘int’: Python int, float values will be rounded to integers * ‘factor’: Unordered categorical data, internally mapped to int values (e.g., “red”->0, “green”->1, etc.) Defaults to None (which sets all dimensions to ‘float’).
None
var_name
list of str
Variable names for each dimension. If None, uses default names [‘x0’, ‘x1’, ‘x2’, …]. Defaults to None.
Minimum distance between points. Defaults to np.sqrt(np.spacing(1))
None
var_trans
list of str
Variable transformations for each dimension. Supported: It can be one of id, log10, log, ln, sqrt, exp, square, cube, inv, reciprocal, or None. Also supports dynamic strings like log(x), sqrt(x), pow(x, p). Defaults to None (no transformations).
Maximum runtime in minutes. If np.inf (default), no time limit. The optimization terminates when either max_iter evaluations are reached OR max_time minutes have elapsed, whichever comes first. Defaults to np.inf.
Number of times to evaluate each initial design point. Useful for noisy objective functions. If > 1, noise handling is activated and statistics (mean, variance) are tracked. Defaults to 1.
Number of times to evaluate each surrogate-suggested point. Useful for noisy objective functions. If > 1, noise handling is activated and statistics (mean, variance) are tracked. Defaults to 1.
Number of additional evaluations to allocate using Optimal Computing Budget Allocation (OCBA) when noise handling is active. OCBA determines which existing design points should be re-evaluated to best distinguish between alternatives. Only used when repeats_surrogate > 1 and ocba_delta > 0. Requires at least 3 design points with variance information. Defaults to 0 (no OCBA).
Enable TensorBoard logging. If True, optimization metrics and hyperparameters are logged to TensorBoard. View logs by running: tensorboard --logdir=<tensorboard_path> in a separate terminal. Defaults to False.
If True, removes old TensorBoard logs before starting optimization so every run begins with a fresh dashboard. With tensorboard_path set, the configured directory itself is removed (and re-created empty by the writer); without a path, all subdirectories of the default ‘runs’ folder are removed. Use with caution as this permanently deletes the affected log directories. Defaults to False.
Function to convert multi-objective values to single-objective. Takes an array of shape (n_samples, n_objectives) and returns array of shape (n_samples,). If None and objective function returns multi-objective values, uses first objective. Defaults to None.
Number of infill points to suggest at each iteration. Defaults to 1. If > 1, multiple distinct points are proposed using the optimizer and fallback strategies.
Maximum number of points to use for surrogate model fitting. If None, all points are used. If the number of evaluated points exceeds this limit, a subset is selected using the selection method. Defaults to 300 (covers typical budgets at full quality while bounding GP-fit cost; pass None for all points).
Method for selecting points when max_surrogate_points is exceeded. Options: ‘distant’ (Select points that are distant from each other via K-means clustering) or ‘best’ (Select all points from the cluster with the best mean objective value). Defaults to ‘distant’.
Penalty value to replace NaN/inf values in objective function evaluations. When the objective function returns NaN or inf, these values are replaced with penalty plus a small random noise (sampled from N(0, 0.1)) to avoid identical penalty values. This allows optimization to continue despite occasional function evaluation failures. Defaults to None.
Optimizer to use for maximizing acquisition function. Can be “differential_evolution” (default) or any method name supported by scipy.optimize.minimize (e.g., “Nelder-Mead”, “L-BFGS-B”). Can also be a callable with signature compatible with scipy.optimize.minimize (fun, x0, bounds, …). A specific version is “de_tricands”, which combines DE with Tricands. It can be parameterized with “prob_de_tricands” (probability of using DE). Defaults to “differential_evolution”.
Patience-based early-stopping threshold. When set to a non-negative integer N, the optimizer terminates after N consecutive restarts that fail to improve the best objective value. The returned :class:scipy.optimize.OptimizeResult has success=True and a message of the form "Optimization early stopped: no improvement for N consecutive restarts". This rule complements restart_after_n and mirrors the no_progress_loss pattern in Hyperopt and plateau-based stopping in Ray Tune and SMAC. None (default) disables the rule so the optimizer runs until max_iter or max_time is reached.
Starting point for optimization, shape (n_features,). If provided, this point will be evaluated first and included in the initial design. The point should be within the bounds and will be validated before use. Defaults to None (no starting point, uses only LHS design).
Probability of using differential evolution as an optimizer on the surrogate model. 1 - prob_de_tricands is the probability of using tricands. Defaults to 0.8.
import numpy as npfrom spotoptim import SpotOptimdef objective(X):return np.sum(X**2, axis=1)# Example 2: With custom variable namesoptimizer = SpotOptim( fun=objective, bounds=[(-5, 5), (-5, 5)], var_name=["param1", "param2"], max_iter=10, n_initial=5)result = optimizer.optimize()# Ensure we can use custom names in plotsoptimizer.plot_surrogate(show=False)
import numpy as npfrom spotoptim import SpotOptim# Example 3: Noisy function with repeated evaluationsdef noisy_objective(X): base = np.sum(X**2, axis=1) noise = np.random.normal(0, 0.1, size=base.shape)return base + noiseoptimizer = SpotOptim( fun=noisy_objective, bounds=[(-5, 5), (-5, 5)], max_iter=10, n_initial=5, repeats_initial=1, # Evaluate each initial point once repeats_surrogate=2, # Evaluate each new point twice seed=42, # For reproducibility verbose=True)result = optimizer.optimize()# Access noise statisticsprint("Unique design points:", optimizer.mean_X.shape[0])print("Best mean value:", optimizer.min_mean_y)print("Variance at best point:", optimizer.min_var_y)
TensorBoard logging disabled
Initial best: f(x) = 3.403652, mean best: f(x) = 3.403652
Iter 1 | Best: 3.279049 | Rate: 0.50 | Evals: 70.0% | Mean Best: 3.369717
Iter 2 | Best: 3.279049 | Curr: 3.392848 | Rate: 0.25 | Evals: 90.0% | Mean Curr: 3.454694
Iter 3 | Best: 1.563295 | Rate: 0.50 | Evals: 110.0% | Mean Best: 1.613594
Unique design points: 8
Best mean value: 1.6135937968531628
Variance at best point: 0.002529978015323257
import numpy as npfrom spotoptim import SpotOptimdef noisy_objective(X): base = np.sum(X**2, axis=1) noise = np.random.normal(0, 0.1, size=base.shape)return base + noise# Example 4: Noisy function with OCBA (Optimal Computing Budget Allocation)optimizer_ocba = SpotOptim( fun=noisy_objective, bounds=[(-5, 5), (-5, 5)], max_iter=20, n_initial=5, repeats_initial=2, # Initial repeats repeats_surrogate=1, # Surrogate repeats ocba_delta=3, # Allocate 3 additional evaluations per iteration seed=42, verbose=True)result = optimizer_ocba.optimize()# OCBA intelligently re-evaluates promising points to reduce uncertaintyprint("Total evaluations:", result.nfev)print("Unique design points:", optimizer_ocba.mean_X.shape[0])print("Best mean value:", optimizer_ocba.min_mean_y)print("Variance at best point:", optimizer_ocba.min_var_y)
TensorBoard logging disabled
Initial best: f(x) = 3.328092, mean best: f(x) = 3.368681
In get_ocba():
means: [25.90094202 19.61660056 23.96405211 3.36868097 10.79578138]
vars: [6.73858271e-13 2.56053422e-03 1.00799409e-03 1.64745915e-03
1.91555606e-03]
delta: 3
n_designs: 5
Ratios: [3.82210611e-11 2.79305049e-01 6.84325095e-02 9.58065217e-01
1.00000000e+00]
Best: 3, Second best: 4
OCBA: Adding 3 re-evaluation(s)
Iter 1 | Best: 3.103418 | Rate: 0.75 | Evals: 70.0% | Mean Best: 3.103418
Iter 2 | Best: 3.103418 | Curr: 3.354608 | Rate: 0.60 | Evals: 75.0% | Mean Curr: 3.354608
Iter 3 | Best: 1.613711 | Rate: 0.67 | Evals: 80.0% | Mean Best: 1.613711
Iter 4 | Best: 1.230192 | Rate: 0.71 | Evals: 85.0% | Mean Best: 1.230192
Iter 5 | Best: 0.449319 | Rate: 0.75 | Evals: 90.0% | Mean Best: 0.449319
Iter 6 | Best: 0.367160 | Rate: 0.78 | Evals: 95.0% | Mean Best: 0.367160
Iter 7 | Best: 0.367160 | Curr: 0.518353 | Rate: 0.70 | Evals: 100.0% | Mean Curr: 0.518353
Total evaluations: 20
Unique design points: 12
Best mean value: 0.36716033650977453
Variance at best point: 0.0
import numpy as npfrom spotoptim import SpotOptimfrom sklearn.ensemble import RandomForestRegressordef objective(X):return np.sum(X**2, axis=1)# Example 8: Using Random Forest as surrogaterf_model = RandomForestRegressor( n_estimators=100, max_depth=10, random_state=42)optimizer_rf = SpotOptim( fun=objective, bounds=[(-5, 5), (-5, 5)], surrogate=rf_model, max_iter=10, n_initial=5, seed=42)result = optimizer_rf.optimize()# Note: Random Forests don't provide uncertainty estimates,# so Expected Improvement (EI) may be less effective.# Consider using acquisition='y' for pure exploitation.
import numpy as npfrom spotoptim import SpotOptimfrom sklearn.gaussian_process import GaussianProcessRegressorfrom sklearn.gaussian_process.kernels import Matern, RationalQuadratic, ConstantKernel, RBFdef objective(X):return np.sum(X**2, axis=1)# Example 9: Comparing different kernels for Gaussian Process# Matern kernel with nu=1.5 (once differentiable)kernel_matern15 = ConstantKernel(1.0) * Matern(length_scale=1.0, nu=1.5)gp_matern15 = GaussianProcessRegressor(kernel=kernel_matern15, normalize_y=True)# Matern kernel with nu=2.5 (twice differentiable, DEFAULT)kernel_matern25 = ConstantKernel(1.0) * Matern(length_scale=1.0, nu=2.5)gp_matern25 = GaussianProcessRegressor(kernel=kernel_matern25, normalize_y=True)# RBF kernel (infinitely differentiable, smooth)kernel_rbf = ConstantKernel(1.0) * RBF(length_scale=1.0)gp_rbf = GaussianProcessRegressor(kernel=kernel_rbf, normalize_y=True)# Rational Quadratic kernel (mixture of RBF kernels)kernel_rq = ConstantKernel(1.0) * RationalQuadratic(length_scale=1.0, alpha=1.0)gp_rq = GaussianProcessRegressor(kernel=kernel_rq, normalize_y=True)# Use any of these as surrogateoptimizer_rbf = SpotOptim(fun=objective, bounds=[(-5, 5), (-5, 5)], surrogate=gp_rbf, max_iter=10, n_initial=5)result = optimizer_rbf.optimize()
Validate and process starting point x0. Called in __init__ and optimize.
aggregate_mean_var
SpotOptim.SpotOptim.aggregate_mean_var(X, y)
Aggregate X and y values to compute mean and variance per group. For repeated evaluations at the same design point, this method computes the mean function value and variance (using population variance, ddof=0).
A tuple containing: * X_agg (ndarray): Unique design points, shape (n_groups, n_features) * y_mean (ndarray): Mean y values per group, shape (n_groups,) * y_var (ndarray): Variance of y values per group, shape (n_groups,)
Apply Optimal Computing Budget Allocation for noisy functions.
apply_penalty_NA
SpotOptim.SpotOptim.apply_penalty_NA( y, y_history=None, penalty_value=None, sd=0.1,)
Replace NaN and infinite values with penalty plus random noise. Used in the optimize() method after function evaluations. This method follows the approach from spotpython.utils.repair.apply_penalty_NA, replacing NaN/inf values with a penalty value plus random noise to avoid identical penalty values.
Parameters
Name
Type
Description
Default
y
ndarray
Array of objective function values to be repaired.
required
y_history
ndarray
Historical objective function values used for computing penalty statistics. If None, uses y itself. Default is None.
Value to replace NaN/inf with. If None, computes penalty as: max(finite_y_history) + 3 * std(finite_y_history). If all values are NaN/inf or only one finite value exists, falls back to self.penalty_val. Default is None.
Array with NaN/inf replaced by penalty_value + random noise (normal distributed with mean 0 and standard deviation sd).
Examples
import numpy as npfrom spotoptim import SpotOptimopt = SpotOptim(fun=lambda X: np.sum(X**2, axis=1), bounds=[(-5, 5)])y_hist = np.array([1.0, 2.0, 3.0, 5.0])y_new = np.array([4.0, np.nan, np.inf])y_clean = opt.apply_penalty_NA(y_new, y_history=y_hist)print(f"np.all(np.isfinite(y_clean)): {np.all(np.isfinite(y_clean))}")print(f"y_clean: {y_clean}")# NaN/inf replaced with worst value from history + 3*std + noiseprint(f"y_clean[1] > 5.0: {y_clean[1] >5.0}") # Should be larger than max finite value in history
Validate that initial design has sufficient points for surrogate fitting.
Checks if the number of valid initial design points meets the minimum requirement for fitting a surrogate model. The minimum required is the smaller of: * (a) typical minimum for surrogate fitting (3 for multi-dimensional, 2 for 1D), or * (b) what the user requested (n_initial).
Parameters
Name
Type
Description
Default
y0
ndarray
Function values at initial design points (after filtering), shape (n_valid,).
Error: Insufficient valid initial design points: only 1 finite value(s) out of 10 evaluated. Need at least 3 points to fit surrogate model. Please check your objective function or increase n_initial.
TensorBoard logging disabled
Note: Initial design size (3) is smaller than requested (10) due to NaN/inf values
curate_initial_design
SpotOptim.SpotOptim.curate_initial_design(X0)
Remove duplicates and ensure sufficient unique points in initial design.
This method handles deduplication that can occur after rounding integer/factor variables. If duplicates are found, it generates additional points to reach the target n_initial unique points. Also handles repeating points when repeats_initial > 1.
Parameters
Name
Type
Description
Default
X0
ndarray
Initial design points in internal scale, shape (n_samples, n_features).
List of variable types (‘factor’ or ‘float’) for each dimension. Dimensions with factor mappings are assigned ‘factor’, others ‘float’.
Examples
from spotoptim import SpotOptim# Define a simple objective mapping names to values for demonstrationdef objective(X):# X has shape (n_samples, n_dimensions)return X[:, 0] + X[:, 1]# The first dimension has factor levels ('red', 'green', 'blue')# The second dimension is continuous bounds (0, 10)spot = SpotOptim(fun=objective, bounds=[('red', 'green', 'blue'), (0, 10)])print(spot.detect_var_type())
['factor', 'float']
/tmp/ipykernel_2589/1685966243.py:10: UserWarning: Factor variables detected (original bounds dimensions: [0]) but the active surrogate (GaussianProcessRegressor) does not support nominal (order-agnostic) factor metrics. Factor integer codes will be treated as ordinal numbers, which may mislead the surrogate. Consider using a factor-aware Kriging surrogate: Kriging(metric_factorial='hamming').
spot = SpotOptim(fun=objective, bounds=[('red', 'green', 'blue'), (0, 10)])
Determine termination reason for optimization. Checks the termination conditions and returns an appropriate message indicating why the optimization stopped. Three possible termination conditions are checked in order of priority: 1. Maximum number of evaluations reached 2. Maximum time limit exceeded 3. Successful completion (neither limit reached)
Optimization terminated: maximum evaluations (10) reached
# Case 2: Time limit exceededimport numpy as npimport timefrom spotoptim import SpotOptimopt.y_ = np.zeros(10) # Only 10 evaluationsstart_time = time.time() -700# Simulate 11.67 minutes elapsedmsg = opt.determine_termination(start_time)print(msg)
Optimization terminated: maximum evaluations (10) reached
# Case 3: Successful completionimport numpy as npimport timefrom spotoptim import SpotOptimopt.y_ = np.zeros(10) # Under max_iterstart_time = time.time() # Just startedmsg = opt.determine_termination(start_time)print(msg)
Optimization terminated: maximum evaluations (10) reached
evaluate_function
SpotOptim.SpotOptim.evaluate_function(X)
Evaluate objective function at points X. Used in the optimize() method to evaluate the objective function.
Input Space: X is expected in Transformed and Mapped Space (Internal scale, Reduced dimensions). Process as follows: 1. Expands X to Transformed Space (Full dimensions) if dimension reduction is active. 2. Inverse transforms X to Natural Space (Original scale). 3. Evaluates the user function with points in Natural Space.
If dimension reduction is active, expands X to full dimensions before evaluation. Supports both single-objective and multi-objective functions. For multi-objective functions, converts to single-objective using mo2so method.
Parameters
Name
Type
Description
Default
X
ndarray
Points to evaluate in Transformed and Mapped Space, shape (n_samples, n_reduced_features).
Fit surrogate model using appropriate data based on noise handling. This method selects the appropriate training data for surrogate fitting: * For noisy functions (repeats_surrogate > 1): Uses mean_X and mean_y (aggregated values) * For deterministic functions: Uses X_ and y_ (all evaluated points) The data is transformed to internal scale before fitting the surrogate.
SpotOptim.SpotOptim.fit_select_best_cluster(X, y, k)
Selects all points from the cluster with the smallest mean y value. This method performs K-means clustering and selects all points from the cluster whose center corresponds to the best (smallest) mean objective function value.
A tuple containing: * selected_X (ndarray): Selected design points from best cluster, shape (m, n_features). * selected_y (ndarray): Function values at selected points, shape (m,).
SpotOptim.SpotOptim.fit_select_distant_points(X, y, k)
Selects k points that are distant from each other using K-means clustering. This method performs K-means clustering to find k clusters, then selects the point closest to each cluster center. This ensures a space-filling subset of points for surrogate model training.
Dispatcher for selection methods. Depending on the value of self.selection_method, this method calls the appropriate selection function to choose a subset of points for surrogate model training when the total number of points exceeds self.max_surrogate_points.
Fit surrogate model to data. Used by fit_scheduler() to fit the surrogate model. If the number of points exceeds self.max_surrogate_points, a subset of points is selected using the selection dispatcher.
Parameters
Name
Type
Description
Default
X
ndarray
Design points, shape (n_samples, n_features).
required
y
ndarray
Function values at X, shape (n_samples,).
required
Returns
Name
Type
Description
None
None
Examples
>>>import numpy as np>>>from spotoptim import SpotOptim>>>from sklearn.gaussian_process import GaussianProcessRegressor>>>def sphere(X):... X = np.atleast_2d(X)... return np.sum(X**2, axis=1)>>> opt = SpotOptim(fun=sphere,... bounds=[(-5, 5), (-5, 5)],... max_surrogate_points=10,... surrogate=GaussianProcessRegressor())>>> X = np.random.rand(50, 2)>>> y = np.random.rand(50)>>> opt.fit_surrogate(X, y)>>># Surrogate is now fitted
Generate a table of the design or results. If optimization has been run (results available), returns the results table. Otherwise, returns the design table (search space configuration).
/tmp/ipykernel_2589/3444717442.py:8: UserWarning: n_initial (5) is below 2 * n_dim (6) for a 3-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
generate_initial_design
SpotOptim.SpotOptim.generate_initial_design()
Generate initial space-filling design using Latin Hypercube Sampling. Used in the optimize() method to create the initial set of design points.
/tmp/ipykernel_2589/2940672979.py:3: UserWarning: n_initial (3) is below 2 * n_dim (4) for a 2-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(fun=sphere,
Get the best hyperparameter configuration found during optimization. If noise handling is active (repeats_initial > 1 or OCBA), this returns the parameter configuration associated with the best mean objective value. Otherwise, it returns the configuration associated with the absolute best observed value.
Union[Dict[str, Any], np.ndarray, None]: The best hyperparameter configuration. Returns None if optimization hasn’t started (no data).
Examples
from spotoptim import SpotOptimfrom spotoptim.function import sphereopt = SpotOptim(fun=sphere, bounds=[(-5, 5), (0, 10)], n_initial=5, var_name=["x", "y"], verbose=True)opt.optimize()best_params = opt.get_best_hyperparameters()print(best_params['x']) # Should be close to 0
Determine and store the best point from initial design. Finds the best (minimum) function value in the initial design, stores the corresponding point and value in instance attributes, and optionally prints the results if verbose mode is enabled. For noisy functions, also reports the mean best value.
Note
This method assumes self.X_ and self.y_ have been initialized with the initial design evaluations.
Get a table string showing the search space design before optimization. This method generates a table displaying the variable names, types, bounds, and defaults without requiring an optimization run. Useful for inspecting and documenting the search space configuration.
/tmp/ipykernel_2589/1006789391.py:8: UserWarning: n_initial (5) is below 2 * n_dim (6) for a 3-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
Generate experiment filename with ’_exp.pkl’ suffix.
get_importance
SpotOptim.SpotOptim.get_importance()
Calculate variable importance scores. Importance is computed as the normalized sensitivity of each parameter based on the variation in objective values across the evaluated points. Higher scores indicate parameters that have more influence on the objective. The importance is calculated as: 1. For each dimension, compute the correlation between parameter values and objective values 2. Normalize to percentage scale (0-100) 3. Higher values indicate more important parameters
Generate or process initial design points. Ensures that design points are in internal (transformed and reduced) scale. Calls generate_initial_design() if X0 is None, otherwise processes user-provided X0. Handles three scenarios: * X0 is None: Generate space-filling design using LHS * X0 is None but starting point(s) x0 is provided: Generate LHS and include x0 as first point(s) * X0 is provided: Transform and prepare user-provided initial design
Parameters
Name
Type
Description
Default
X0
ndarray
User-provided initial design points in original scale, shape (n_initial, n_features). If None, generates space-filling design. Defaults to None.
Get a comprehensive table string of optimization results. This method generates a formatted table of the search space configuration, best values found, and optionally variable importance scores.
Whether to include importance scores. Importance is calculated as the normalized standard deviation of each parameter’s effect on the objective. Requires multiple evaluations. Defaults to False.
/tmp/ipykernel_2589/3820262429.py:8: UserWarning: n_initial (5) is below 2 * n_dim (6) for a 3-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
Handle default variable transformations. Does not perform any transformations, only sets var_trans to a list of None values if not specified, or normalizes transformation names by converting id, None, or None to None. Also validates that var_trans length matches the number of dimensions.
spot.var_trans (should be ['log10', 'None']): ['log10', None]
init_storage
SpotOptim.SpotOptim.init_storage(X0, y0)
Initialize storage for optimization. Sets up the initial data structures needed for optimization tracking: * X_: Evaluated design points (in original scale) * y_: Function values at evaluated points * n_iter_: Iteration counter Then updates statistics by calling update_stats().
Parameters
Name
Type
Description
Default
X0
ndarray
Initial design points in internal scale, shape (n_samples, n_features).
Initialize or configure the surrogate model for optimization. Handles three surrogate configurations: * List of surrogates: sets up multi-surrogate selection with probability weights and per-surrogate max_surrogate_points. * None (default): creates a GaussianProcessRegressor with a ConstantKernel * Matern(nu=2.5) kernel, 100 optimizer restarts, and normalize_y=True. * User-provided surrogate: accepted as-is; internal bookkeeping attributes (_max_surrogate_points_list, _active_max_surrogate_points) are still initialised. After this method returns the following attributes are set: * self.surrogate — the active surrogate model. * self._surrogates_list — list | None. * self._prob_surrogate — normalised selection probabilities or None. * self._max_surrogate_points_list — per-surrogate point caps or None. * self._active_max_surrogate_points — active cap.
Transform parameter array from internal to original scale. Converts from transformed space (full dimension) to natural space (original). Does NOT handle dimension expansion (un-mapping).
Parameters
Name
Type
Description
Default
X
ndarray
Array in Transformed Space, shape (n_samples, n_features)
Load complete optimization results from a pickle file.
map_to_factor_values
SpotOptim.SpotOptim.map_to_factor_values(X)
Map internal integer factor values back to string labels. For factor variables, converts integer indices back to original string values. Other variable types remain unchanged.
Parameters
Name
Type
Description
Default
X
ndarray
Design points with integer values for factors, shape (n_samples, n_features).
/tmp/ipykernel_2589/3819615918.py:4: UserWarning: Factor variables detected (original bounds dimensions: [0]) but the active surrogate (GaussianProcessRegressor) does not support nominal (order-agnostic) factor metrics. Factor integer codes will be treated as ordinal numbers, which may mislead the surrogate. Consider using a factor-aware Kriging surrogate: Kriging(metric_factorial='hamming').
spot = SpotOptim(
mo2so
SpotOptim.SpotOptim.mo2so(y_mo)
Convert multi-objective values to single-objective. Converts multi-objective values to a single-objective value by applying a user-defined function from fun_mo2so. If no user-defined function is given, the values in the first objective column are used.
This method is called after the objective function evaluation. It returns a 1D array with the single-objective values.
Parameters
Name
Type
Description
Default
y_mo
ndarray
If multi-objective, shape (n_samples, n_objectives). If single-objective, shape (n_samples,).
Modify bounds based on variable types. Adjusts bounds for each dimension according to its var_type: * ‘int’: Ensures bounds are integers (ceiling for lower, floor for upper) * ‘factor’: Bounds already set to (0, n_levels-1) by process_factor_bounds * ‘float’: Explicitly converts bounds to float
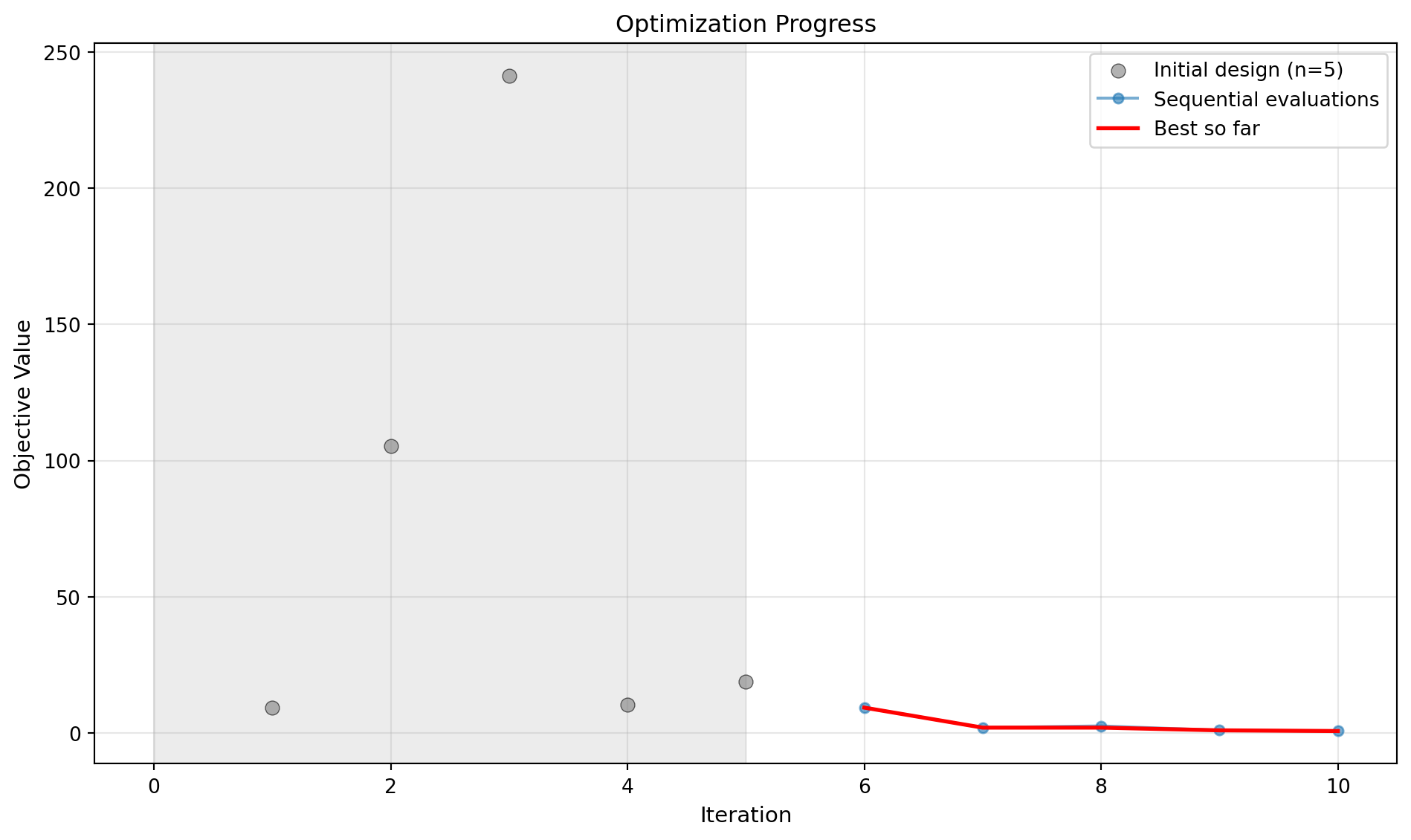
Run the optimization process. The optimization terminates when either the total function evaluations reach max_iter (including initial design), or the runtime exceeds max_time minutes. Input/Output spaces are * Input X0: Expected in Natural Space (original scale, physical units). * Output result.x: Returned in Natural Space. * Output result.X: Returned in Natural Space. * Internal Optimization: Performed in Transformed and Mapped Space.
Parameters
Name
Type
Description
Default
X0
ndarray
Initial design points in Natural Space, shape (n_initial, n_features). If None, generates space-filling design. Defaults to None.
None
Returns
Name
Type
Description
OptimizeResult
OptimizeResult
Optimization result with fields: * x: best point found in Natural Space * fun: best function value * nfev: number of function evaluations (including initial design) * nit: number of sequential optimization iterations (after initial design) * success: whether optimization succeeded * message: termination message indicating reason for stopping, including statistics (function value, iterations, evaluations) * X: all evaluated points in Natural Space * y: all function values * x_encoded: best point in full-dimension natural-NUMERIC encoding (factor dimensions as integer level indices) — the representation restart injection and validate_x0 consume * X_encoded: all evaluated points in the same numeric encoding (numeric dtype even when factor dimensions map to string labels in X)
The optimized point(s). If acquisition_fun_return_size == 1, returns 1D array of shape (n_features,). If acquisition_fun_return_size > 1, returns 2D array of shape (N, n_features), where N is min(acquisition_fun_return_size, population_size).
Examples
import numpy as npfrom spotoptim import SpotOptimdef sphere(X): X = np.atleast_2d(X)return np.sum(X**2, axis=1)opt = SpotOptim( fun=sphere, bounds=[(-5, 5), (-5, 5)], n_initial=5, max_iter=10, seed=0,)opt.optimize()x_next = opt.suggest_next_infill_point()print("Next point to evaluate:", x_next)
Perform a single sequential optimization run. Calls _initialize_run, rm_initial_design_NA_values, check_size_initial_design, init_storage, get_best_xy_initial_design, and _run_sequential_loop.
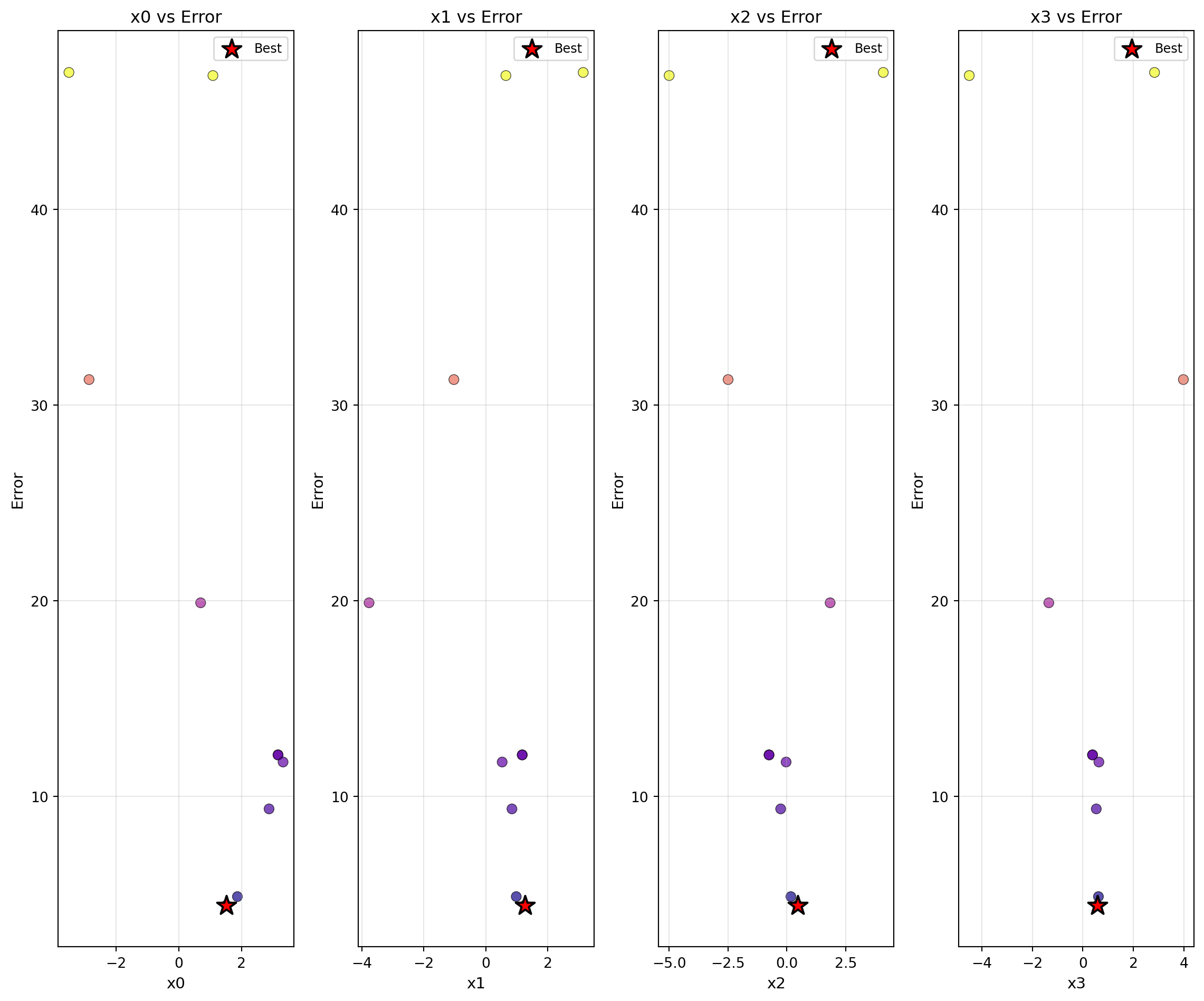
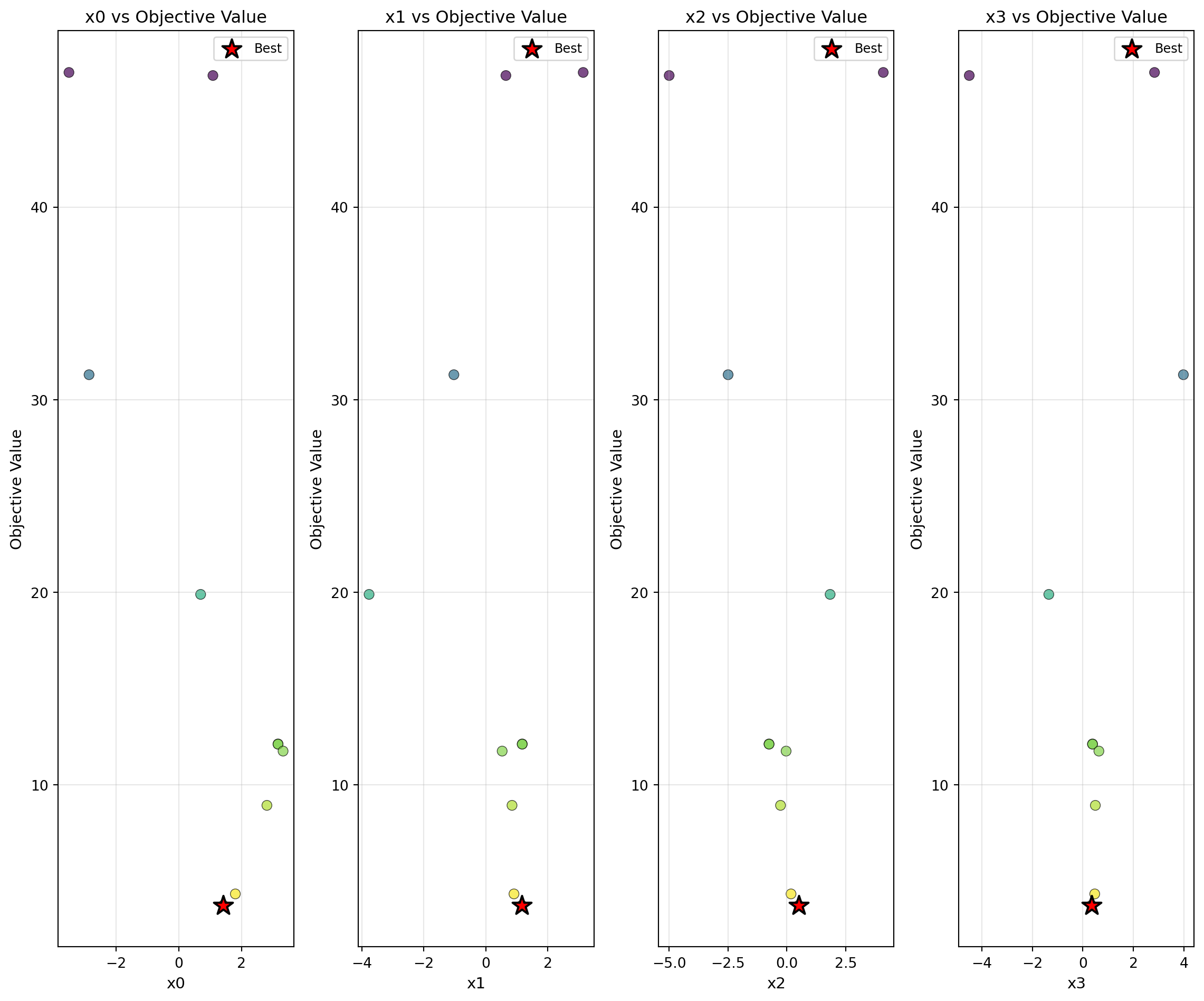
Plot parameter distributions showing relationship between each parameter and objective. Creates a grid of scatter plots, one for each parameter dimension, showing how the objective function value varies with each parameter. The best configuration is marked with a red star. Parameters with log-scale transformations (var_trans) are automatically displayed on a log x-axis. Optionally displays Spearman correlation coefficients in plot titles for sensitivity analysis. For factor (categorical) variables, correlation is not computed and they are displayed with discrete positions on the x-axis.
Parameters
Name
Type
Description
Default
result
OptimizeResult
Optimization result containing best parameters. If None, uses the best found values from self.best_x_ and self.best_y_.
/tmp/ipykernel_2589/1349348197.py:6: UserWarning: n_initial (5) is below 2 * n_dim (8) for a 4-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
Print the best solution found during optimization. This method displays the best hyperparameters and objective value in a formatted table. It supports custom transformations for parameters (e.g., converting log-scale values back to original scale).
Parameters
Name
Type
Description
Default
result
OptimizeResult
Optimization result object from optimize(). If None, uses the stored best values from the optimizer. Defaults to None.
None
transformations
list of callable
List of transformation functions to apply to each parameter. Each function takes a single value and returns the transformed value. Use None for parameters that don’t need transformation. Length must match number of dimensions. Example: [None, None, lambda x: 10**x] to convert the 3rd parameter from log10 scale. Defaults to None.
Alias for print(get_results_table()) for compatibility. Prints the table.
process_factor_bounds
SpotOptim.SpotOptim.process_factor_bounds()
Process bounds to handle factor variables. For dimensions with tuple bounds (factor variables), creates internal integer mappings and replaces bounds with (0, n_levels-1). Stores mappings in self._factor_maps: {dim_idx: {int_val: str_val}}
/tmp/ipykernel_2589/108329329.py:2: UserWarning: Factor variables detected (original bounds dimensions: [0]) but the active surrogate (GaussianProcessRegressor) does not support nominal (order-agnostic) factor metrics. Factor integer codes will be treated as ordinal numbers, which may mislead the surrogate. Consider using a factor-aware Kriging surrogate: Kriging(metric_factorial='hamming').
spot = SpotOptim(fun=lambda x: x, bounds=[('red', 'green', 'blue'), (0, 10)])
reinitialize_components
SpotOptim.SpotOptim.reinitialize_components()
Reinitialize components that were excluded during pickling.
remove_nan
SpotOptim.SpotOptim.remove_nan(X, y, stop_on_zero_return=True)
Remove rows where y contains NaN or inf values. Used in the optimize() method after function evaluations.
Enforce integrality and declared bounds in natural (original) space.
Integer dimensions are rounded to the nearest integer; integer dimensions with an active transform are additionally clipped to their declared natural bounds, because the inverse transform of a continuous internal proposal can land marginally outside them (issue #87). Float and factor dimensions pass through unchanged.
Parameters
Name
Type
Description
Default
X
ndarray
Points in natural scale, shape (n_samples, n_features) or (n_features,).
Round non-numeric values to integers based on variable type. This method applies rounding to variables that are not continuous: * ‘float’: No rounding (continuous values) * ‘int’: Rounded to integers * ‘factor’: Rounded to integers (representing categorical values)
Remove NaN/inf values from initial design evaluations. This method filters out design points that returned NaN or inf values during initial evaluation. Unlike the sequential optimization phase where penalties are applied, initial design points with invalid values are simply removed.
Parameters
Name
Type
Description
Default
X0
ndarray
Initial design points in internal scale, shape (n_samples, n_features).
Tuple[ndarray, ndarray, int]: Filtered (X0, y0) with only finite values and the original count before filtering. X0 has shape (n_valid, n_features), y0 has shape (n_valid,), and the int is the original size.
Compute and print Spearman correlation between parameters and objective values. This method analyzes the sensitivity of the objective function to each hyperparameter by computing Spearman rank correlations. For categorical (factor) variables, correlation is not computed as they require visual inspection instead. The method automatically handles different parameter types: * Integer/float parameters: Direct correlation with objective values * Log-transformed parameters (log10, log, ln): Correlation in log-space * Factor (categorical) parameters: Skipped with informative message Significance levels: * : p < 0.001 (highly significant) : p < 0.01 (significant) * *: p < 0.05 (marginally significant)
Examples
from spotoptim import SpotOptimimport numpy as npdef test_func(X):# x0 has strong effect, x1 has weak effect X = np.atleast_2d(X)return10* X[:, 0]**2+0.1* X[:, 1]**2opt = SpotOptim( fun=test_func, bounds=[(-5, 5), (-5, 5)], var_name=["x0", "x1"], max_iter=10, n_initial=5, seed=42)opt.optimize()opt.sensitivity_spearman()
Only meaningful after optimize() has been called with sufficient evaluations.
set_seed
SpotOptim.SpotOptim.set_seed()
Set global random seeds for reproducibility. Sets seeds for: * random * numpy.random * torch (cpu and cuda) Only performs actions if self.seed is not None.
Returns
Name
Type
Description
None
None
Examples
from spotoptim import SpotOptimimport numpy as npspot = SpotOptim(fun=lambda x: x, bounds=[(0, 1)], seed=42)spot.set_seed()np.random.rand() # Should be deterministic
0.3745401188473625
setup_dimension_reduction
SpotOptim.SpotOptim.setup_dimension_reduction()
Set up dimension reduction by identifying fixed dimensions. Identifies dimensions where lower and upper bounds are equal in Transformed Space. Reduces self.bounds, self.lower, self.upper, etc., to the Mapped Space (active variables only). The resulting self.bounds defines the Transformed and Mapped Space used for optimization. This method identifies variables that are fixed (constant) and excludes them from the optimization process. It stores: * Original bounds and metadata in all_* attributes * Boolean mask of fixed dimensions in ident * Reduced bounds, types, and names for optimization * red_dim flag indicating if reduction occurred
Store multi-objective values in self.y_mo. If multi-objective values are present (ndim==2), they are stored in self.y_mo. New values are appended to existing ones. For single-objective problems, self.y_mo remains None.
Parameters
Name
Type
Description
Default
y_mo
ndarray
If multi-objective, shape (n_samples, n_objectives). If single-objective, shape (n_samples,).
required
Examples
import numpy as npfrom spotoptim import SpotOptimopt = SpotOptim( fun=lambda X: np.column_stack([ np.sum(X**2, axis=1), np.sum((X-1)**2, axis=1) ]), bounds=[(-5, 5), (-5, 5)], max_iter=10, n_initial=5)y_mo_1 = np.array([[1.0, 2.0], [3.0, 4.0]])opt.store_mo(y_mo_1)print(f"y_mo after first call: {opt.y_mo}")y_mo_2 = np.array([[5.0, 6.0], [7.0, 8.0]])opt.store_mo(y_mo_2)print(f"y_mo after second call: {opt.y_mo}")
y_mo after first call: [[1. 2.]
[3. 4.]]
y_mo after second call: [[1. 2.]
[3. 4.]
[5. 6.]
[7. 8.]]
suggest_next_infill_point
SpotOptim.SpotOptim.suggest_next_infill_point()
Suggest next point to evaluate (dispatcher). Used in both sequential and parallel optimization loops. This method orchestrates the process of generating candidate points from the acquisition function optimizer, handling any failures in the acquisition process with a fallback strategy, and ensuring that the returned point(s) are valid and ready for evaluation. The returned point is in the Transformed and Mapped Space (Internal Optimization Space). This means: 1. Transformations (e.g., log, sqrt) have been applied. 2. Dimension reduction has been applied (fixed variables removed). Process: 1. Try candidates from acquisition function optimizer. 2. Handle acquisition failure (fallback). 3. Return last attempt if all fails.
import numpy as npfrom spotoptim import SpotOptimdef sphere(X): X = np.atleast_2d(X)return np.sum(X**2, axis=1)opt = SpotOptim( fun=sphere, bounds=[(-5, 5), (-5, 5)], n_initial=5, n_infill_points=2)# Need to initialize optimization state (X_, y_, surrogate)# Normally done inside optimize()np.random.seed(0)opt.X_ = np.random.rand(10, 2)opt.y_ = np.random.rand(10)opt.fit_surrogate(opt.X_, opt.y_)x_next = opt.suggest_next_infill_point()x_next.shape
(2, 2)
to_all_dim
SpotOptim.SpotOptim.to_all_dim(X_red)
Expand reduced-dimensional points to full-dimensional representation. This method restores points from the reduced optimization space to the full-dimensional space by inserting fixed values for constant dimensions.
Parameters
Name
Type
Description
Default
X_red
ndarray
Points in reduced space, shape (n_samples, n_reduced_dims).
Points in full space, shape (n_samples, n_original_dims).
Examples
import numpy as npfrom spotoptim import SpotOptimdef sphere(X): X = np.atleast_2d(X)return np.sum(X**2, axis=1)# Create problem with one fixed dimensionopt = SpotOptim( fun=sphere, bounds=[(-5, 5), (2, 2), (-5, 5)], # x1 is fixed at 2 max_iter=10, n_initial=3)X_red = np.array([[1.0, 3.0], [2.0, 4.0]]) # Only x0 and x2X_full = opt.to_all_dim(X_red)print(X_full.shape)print(X_full[:, 1])
(2, 3)
[2. 2.]
/tmp/ipykernel_2589/62356470.py:7: UserWarning: n_initial (3) is below 2 * n_dim (6) for a 3-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
to_red_dim
SpotOptim.SpotOptim.to_red_dim(X_full)
Reduce full-dimensional points to optimization space. This method removes fixed dimensions from full-dimensional points, extracting only the varying dimensions used in optimization.
Parameters
Name
Type
Description
Default
X_full
ndarray
Points in full space, shape (n_samples, n_original_dims).
Points in reduced space, shape (n_samples, n_reduced_dims).
Examples
import numpy as npfrom spotoptim import SpotOptimdef sphere(X): X = np.atleast_2d(X)return np.sum(X**2, axis=1)# Create problem with one fixed dimensionopt = SpotOptim( fun=sphere, bounds=[(-5, 5), (2, 2), (-5, 5)], # x1 is fixed at 2 max_iter=10, n_initial=3)X_full = np.array([[1.0, 2.0, 3.0], [4.0, 2.0, 5.0]])X_red = opt.to_red_dim(X_full)print(X_red.shape)print(np.array_equal(X_red, np.array([[1.0, 3.0], [4.0, 5.0]])))
(2, 2)
True
/tmp/ipykernel_2589/3053713305.py:7: UserWarning: n_initial (3) is below 2 * n_dim (6) for a 3-dimensional problem. Cold-start designs this small may under-sample the search space; consider n_initial=max(10, 2 * n_dim) = 10.
opt = SpotOptim(
transform_X
SpotOptim.SpotOptim.transform_X(X)
Transform parameter array from original (natural) to internal scale. Converts from natural space (Original) to transformed space (full dimension). Does NOT handle dimension reduction (mapping).
Parameters
Name
Type
Description
Default
X
ndarray
Array in Natural Space, shape (n_samples, n_features)
from spotoptim import SpotOptimimport numpy as npfrom spotoptim.function import spherespot = SpotOptim(fun=sphere, bounds=[(1, 10)], var_trans=['log10'])X_orig = np.array([[1], [10], [100]])spot.transform_X(X_orig)
array([[0],
[1],
[2]])
transform_bounds
SpotOptim.SpotOptim.transform_bounds()
Transform bounds from original to internal scale. Updates self.bounds (and self.lower, self.upper) from Natural Space to Transformed Space. Calls transform_value for each bound and converts numpy types to Python native types (int or float based on var_type). Handles also reversed bounds, e.g., as an effect of reciprocal transformation.
Returns
Name
Type
Description
None
None
Notes
Uses settings in self.var_trans. It can be one of id, log10, log, ln, sqrt, exp, square, cube, inv, reciprocal, or None. Also supports dynamic strings like log(x), sqrt(x), pow(x, p).
Examples
from spotoptim import SpotOptimfrom spotoptim.function import sphereimport numpy as npspot = SpotOptim(fun=sphere, bounds=[(1, 10), (0.1, 100)])spot.var_trans = ['log10', 'sqrt']spot.transform_bounds()print(f"spot.bounds: {spot.bounds}")
Transformation name. Can be one of id, log10, log, ln, sqrt, exp, square, cube, inv, reciprocal, or None. Also supports dynamic strings like log(x), sqrt(x), pow(x, p).
Repeat infill point for noisy function evaluation. Used in the sequential_loop. For noisy objective functions (repeats_surrogate > 1), creates multiple copies of the suggested point for repeated evaluation. Otherwise, returns the point in 2D array format.
Points to evaluate, shape (repeats_surrogate, n_features) or (1, n_features) if repeats_surrogate == 1.
Examples
import numpy as npfrom spotoptim import SpotOptimfrom spotoptim.function import sphere, noisy_sphere# Without repeatsopt = SpotOptim( fun=sphere, bounds=[(-5, 5), (-5, 5)], repeats_surrogate=1)x_next = np.array([1.0, 2.0])x_repeated = opt.update_repeats_infill_points(x_next)print(x_repeated.shape)# With repeats for noisy functionopt_noisy = SpotOptim( fun=noisy_sphere, bounds=[(-5, 5), (-5, 5)], repeats_surrogate=3)x_next = np.array([1.0, 2.0])x_repeated = opt_noisy.update_repeats_infill_points(x_next)print(x_repeated.shape)# All three copies should be identicalnp.all(x_repeated[0] == x_repeated[1])
(1, 2)
(3, 2)
np.True_
update_stats
SpotOptim.SpotOptim.update_stats()
Update optimization statistics. Updates various statistics related to the optimization progress: * min_y: Minimum y value found so far * min_X: X value corresponding to minimum y * counter: Total number of function evaluations
Notes
success_rate is updated separately via update_success_rate() method, which is called after each batch of function evaluations.
If “noise” is True (repeats_initial > 1 or repeats_surrogate > 1), additionally computes: * mean_X: Unique design points (aggregated from repeated evaluations) * mean_y: Mean y values per design point * var_y: Variance of y values per design point * min_mean_X: X value of the best mean y value * min_mean_y: Best mean y value * min_var_y: Variance of the best mean y value
Returns
Name
Type
Description
None
None
Examples
import numpy as npfrom spotoptim import SpotOptimfrom spotoptim.function import sphere# Without noiseopt = SpotOptim(fun=sphere, bounds=[(-5, 5), (-5, 5)], max_iter=10, n_initial=5)opt.optimize()print("SpotOptim stats without noise:")print(f"opt.X_: {opt.X_}")print(f"opt.y_: {opt.y_}")print(f"opt.min_y: {opt.min_y}")print(f"opt.min_X: {opt.min_X}")print(f"opt.counter: {opt.counter}")
Update storage (X_, y_) with new evaluation points. Appends new design points and their function values to the storage arrays. Points are converted from internal scale to original scale before storage.
Parameters
Name
Type
Description
Default
X_new
ndarray
New design points in internal scale, shape (n_new, n_features).
Update the rolling success rate of the optimization process. A success is counted only if the new value is better (smaller) than the best found y value so far. The success rate is calculated based on the last window_size successes. Important: This method should be called BEFORE updating self.y_ to correctly track improvements against the previous best value.
Parameters
Name
Type
Description
Default
y_new
ndarray
The new function values to consider for the success rate update.
Validate and process starting point x0. Called in __init__ and optimize. This method checks that x0: * Is a numpy array * Has the correct number of dimensions * Has values within bounds (in original scale) * Is properly transformed to internal scale