SpotOptim provides comprehensive save and load functionality for serializing optimization configurations and results. This enables distributed workflows where experiments are defined locally, executed remotely, and analyzed back on the local machine.
14.1 Key Concepts
14.1.1 Experiments vs Results
SpotOptim distinguishes between two types of saved data:
Experiment (*_exp.pkl): Configuration only, excluding the objective function and results. Used to transfer optimization setup to remote machines.
Result (*_res.pkl): Complete optimization state including configuration, all evaluations, and results. Used to save and analyze completed optimizations.
Table 14.1 shows what gets saved in each file type.
Table 14.1: Robust Function Saving
Component
Experiment
Result
Configuration (bounds, parameters)
x
x
Objective function
x
x
Evaluations (X, y)
x
Best solution
x
Surrogate model
Excluded*
x
TensorBoard writer
SpotOptim uses dill for serialization, which allows robust saving of objective functions, including lambda functions and locally defined functions.
14.2 Quick Start
import numpy as npfrom spotoptim import SpotOptimdef sphere(X):"""Simple sphere function"""return np.sum(X**2, axis=1)# Create and configure optimizeroptimizer = SpotOptim( fun=sphere, bounds=[(-5, 5), (-5, 5)], max_iter=20, n_initial=10, seed=42)# Run optimizationresult = optimizer.optimize()print(f"Best value: {result.fun:.6f}")# Save complete resultsoptimizer.save_result(prefix="sphere_opt")# Creates: sphere_opt_res.pkl# Later: load and analyze resultsloaded_opt = SpotOptim.load_result("sphere_opt_res.pkl")print(f"Loaded best value: {loaded_opt.best_y_:.6f}")print(f"Total evaluations: {loaded_opt.counter}")
Best value: 0.000000
Experiment saved to sphere_opt_res.pkl
Result saved to sphere_opt_res.pkl
Loaded result from sphere_opt_res.pkl
Loaded best value: 0.000000
Total evaluations: 20
14.3 Distributed Workflow
The save/load functionality enables a powerful workflow for distributed optimization:
14.3.1 Step 1: Define Experiment Locally
Generate the remote_job_001_exp.pkl file by running the following code:
from spotoptim import SpotOptimoptimizer = SpotOptim.load_result("remote_job_001_res.pkl")print(f"Best value found: {optimizer.best_y_:.6f}")print(f"Best point: {optimizer.best_x_}")print(f"Total evaluations: {optimizer.counter}")print(f"Number of iterations: {optimizer.n_iter_}")
Loaded result from remote_job_001_res.pkl
Best value found: 0.054879
Best point: [0.76577181 0.58600184]
Total evaluations: 50
Number of iterations: 40
All evaluated points shape: (50, 2)
All objective values shape: (50,)
14.4 Advanced Usage
14.4.1 Custom Filenames and Paths
import osfrom spotoptim import SpotOptimimport numpy as npdef objective(X):return np.sum(X**2, axis=1)optimizer = SpotOptim( fun=objective, bounds=[(-5, 5), (-5, 5)], max_iter=30, seed=42)# Save with custom filenameoptimizer.save_experiment( filename="custom_name.pkl", verbosity=1)# Save to specific directoryos.makedirs("experiments/batch_001", exist_ok=True)optimizer.save_experiment( prefix="exp_001", path="experiments/batch_001", verbosity=1)# Creates: experiments/batch_001/exp_001_exp.pkl
Experiment saved to custom_name.pkl
Experiment saved to experiments/batch_001/exp_001_exp.pkl
14.4.2 Overwrite Protection
from spotoptim import SpotOptimimport numpy as npdef sphere(X):return np.sum(X**2, axis=1)optimizer = SpotOptim(fun=sphere, bounds=[(-5, 5), (-5, 5)], max_iter=20)result = optimizer.optimize()# First saveoptimizer.save_result(prefix="my_result")# Try to save again - raises FileExistsError by defaulttry: optimizer.save_result(prefix="my_result")exceptFileExistsErroras e:print(f"File already exists: {e}")# Explicitly allow overwritingoptimizer.save_result(prefix="my_result", overwrite=True)print("File overwritten successfully")
Experiment saved to my_result_res.pkl
Result saved to my_result_res.pkl
Experiment saved to my_result_res.pkl
Result saved to my_result_res.pkl
Experiment saved to my_result_res.pkl
Result saved to my_result_res.pkl
File overwritten successfully
14.4.3 Loading and Continuing Optimization
from spotoptim import SpotOptimimport numpy as npdef objective(X):return np.sum(X**2, axis=1)# Initial optimizationopt1 = SpotOptim( fun=objective, bounds=[(-5, 5), (-5, 5)], max_iter=20, seed=42)result1 = opt1.optimize()opt1.save_result(prefix="checkpoint")print(f"Initial optimization: {result1.nfev} evaluations, best={result1.fun:.6f}")# Load and continueopt2 = SpotOptim.load_result("checkpoint_res.pkl")# No need to re-attach function as it is loaded with dillopt2.max_iter =25# Increase budget# Continue optimizationresult2 = opt2.optimize()print(f"After continuation: {result2.nfev} evaluations, best={result2.fun:.6f}")
Experiment saved to checkpoint_res.pkl
Result saved to checkpoint_res.pkl
Initial optimization: 20 evaluations, best=0.000000
Loaded result from checkpoint_res.pkl
After continuation: 25 evaluations, best=0.000000
14.5 Working with Noisy Functions
Save and load preserves noise statistics for reproducible analysis:
TensorBoard logging disabled
Initial best: f(x) = 3.784490, mean best: f(x) = 3.897231
Experiment saved to noisy_opt_res.pkl
Result saved to noisy_opt_res.pkl
Loaded result from noisy_opt_res.pkl
Repeats initial: 3
Repeats surrogate: 2
Best mean value: 3.784490
Mean values available: 10
Variance values available: 10
14.6 Working with Different Variable Types
Save and load preserves variable type information:
import numpy as npfrom spotoptim import SpotOptimdef mixed_objective(X):"""Objective with mixed variable types"""return np.sum(X**2, axis=1)# Create optimizer with mixed variable typesoptimizer = SpotOptim( fun=mixed_objective, bounds=[(-5, 5), (-5, 5), (-5, 5), (-5, 5)], var_type=["float", "int", "factor", "float"], var_name=["continuous", "integer", "categorical", "another_cont"], max_iter=20, n_initial=10, seed=42)result = optimizer.optimize()# Save resultsoptimizer.save_result(prefix="mixed_vars")# Load resultsloaded_opt = SpotOptim.load_result("mixed_vars_res.pkl")print("Variable types preserved:")print(f" var_type: {loaded_opt.var_type}")print(f" var_name: {loaded_opt.var_name}")# Verify integer variables are still integersprint(f"\nInteger variable (dim 1) values:")print(loaded_opt.X_[:5, 1]) # Should be integers
Experiment saved to mixed_vars_res.pkl
Result saved to mixed_vars_res.pkl
Loaded result from mixed_vars_res.pkl
Variable types preserved:
var_type: ['float', 'int', 'factor', 'float']
var_name: ['continuous', 'integer', 'categorical', 'another_cont']
Integer variable (dim 1) values:
[-1. 1. 2. 3. -4.]
14.7 Best Practices
14.7.1 1. Re-attaching the Objective Function (Optional)
Since dill is used for serialization, the objective function is automatically loaded. You only need to re-attach the function if:
You want to change the objective function (e.g., to a different implementation).
The function relies on external resources that cannot be serialized.
# Load experimentoptimizer = SpotOptim.load_experiment("experiment_exp.pkl")# OPTIONAL: Replace the function if needed# optimizer.fun = new_objective_function# Run optimizationresult = optimizer.optimize()
14.7.2 2. Use Meaningful Prefixes
Organize your experiments with descriptive prefixes:
# Good practice: descriptive prefixesoptimizer.save_experiment(prefix="sphere_d10_seed42")optimizer.save_experiment(prefix="rosenbrock_n100_lhs")optimizer.save_result(prefix="final_run_2024_11_15")# Avoid: generic namesoptimizer.save_experiment(prefix="exp1") # Not descriptiveoptimizer.save_result(prefix="result") # Hard to track
14.7.3 3. Save Experiments Before Remote Execution
# Define locallyoptimizer = SpotOptim(bounds=bounds, max_iter=20, seed=42)optimizer.save_experiment(prefix="remote_job")# Transfer file to remote machine# Execute remotely# Transfer results back# Analyze locally
import os# Create directory structureexp_dir ="experiments/batch_001"os.makedirs(exp_dir, exist_ok=True)# Save with full pathoptimizer.save_experiment( prefix="exp_001", path=exp_dir)# Load with full pathexp_file = os.path.join(exp_dir, "exp_001_exp.pkl")loaded_opt = SpotOptim.load_experiment(exp_file)
14.8 Complete Example: Multi-Machine Workflow
Here’s a complete example demonstrating the entire workflow:
14.8.1 Local Machine (Setup)
# setup_experiment.pyimport numpy as npfrom spotoptim import SpotOptimimport osDIRNAME ="experiments_compare_de_tricands_bfgs"# Placeholder function for experiment setupdef placeholder_func(X):return np.sum(X**2, axis=1)# Create experiments directoryos.makedirs(DIRNAME, exist_ok=True)# guarantee that the directory is emptyforfilein os.listdir(DIRNAME): os.remove(os.path.join(DIRNAME, file))# Define multiple experimentsexperiments = [ {"acquisition_optimizer": "differential_evolution", "max_iter": 20, "prefix": "exp_de"}, {"acquisition_optimizer": "tricands", "max_iter": 20, "prefix": "exp_tricands"}, {"acquisition_optimizer": "L-BFGS-B", "max_iter": 20, "prefix": "exp_bfgs"},]for exp_config in experiments: optimizer = SpotOptim( fun=placeholder_func, # Placeholder - will be replaced remotely bounds=[(-10, 10), (-10, 10), (-10, 10)], max_iter=exp_config["max_iter"], n_initial=10, seed=42, acquisition_optimizer=exp_config["acquisition_optimizer"], verbose=True ) optimizer.save_experiment( prefix=exp_config["prefix"], path=DIRNAME )print(f"Created: {DIRNAME}/{exp_config['prefix']}_exp.pkl")print("\nAll experiments created. Transfer '{DIRNAME}' folder to remote machine.")
TensorBoard logging disabled
Experiment saved to experiments_compare_de_tricands_bfgs/exp_de_exp.pkl
Created: experiments_compare_de_tricands_bfgs/exp_de_exp.pkl
TensorBoard logging disabled
Experiment saved to experiments_compare_de_tricands_bfgs/exp_tricands_exp.pkl
Created: experiments_compare_de_tricands_bfgs/exp_tricands_exp.pkl
TensorBoard logging disabled
Experiment saved to experiments_compare_de_tricands_bfgs/exp_bfgs_exp.pkl
Created: experiments_compare_de_tricands_bfgs/exp_bfgs_exp.pkl
All experiments created. Transfer '{DIRNAME}' folder to remote machine.
14.8.2 Remote Machine (Execution)
# run_experiments.pyimport numpy as npfrom spotoptim import SpotOptimimport osimport globdef complex_objective(X):"""Complex multimodal objective function""" term1 = np.sum(X**2, axis=1) term2 =10* np.sum(np.cos(2* np.pi * X), axis=1) term3 =0.1* np.sum(np.sin(5* np.pi * X), axis=1)return term1 - term2 + term3# Find all experiment filesexp_files = glob.glob(f"{DIRNAME}/*_exp.pkl")print(f"Found {len(exp_files)} experiments to run")# Run each experimentfor exp_file in exp_files:print(f"\nProcessing: {exp_file}")# Load experiment optimizer = SpotOptim.load_experiment(exp_file)# Attach objective optimizer.fun = complex_objective# Run optimization result = optimizer.optimize()print(f" Best value: {result.fun:.6f}")# Save result (same prefix, different suffix) prefix = os.path.basename(exp_file).replace("_exp.pkl", "") optimizer.save_result( prefix=prefix, path=DIRNAME )print(f" Saved: {DIRNAME}/{prefix}_res.pkl")print("\nAll experiments completed. Transfer results back to local machine.")
Found 3 experiments to run
Processing: experiments_compare_de_tricands_bfgs/exp_de_exp.pkl
Loaded experiment from experiments_compare_de_tricands_bfgs/exp_de_exp.pkl
Initial best: f(x) = 24.447486
Iter 1 | Best: 24.447486 | Curr: 46.009409 | Rate: 0.00 | Evals: 55.0%
Optimizer candidate 1/3 was duplicate/invalid.
Iter 2 | Best: 24.447486 | Curr: 86.823725 | Rate: 0.00 | Evals: 60.0%
Iter 3 | Best: 24.447486 | Curr: 32.303496 | Rate: 0.00 | Evals: 65.0%
Iter 4 | Best: 24.447486 | Curr: 32.699441 | Rate: 0.00 | Evals: 70.0%
Iter 5 | Best: 24.447486 | Curr: 25.589825 | Rate: 0.00 | Evals: 75.0%
Iter 6 | Best: 9.027734 | Rate: 0.17 | Evals: 80.0%
Iter 7 | Best: 9.027734 | Curr: 25.531014 | Rate: 0.14 | Evals: 85.0%
Iter 8 | Best: 9.027734 | Curr: 11.243210 | Rate: 0.12 | Evals: 90.0%
Iter 9 | Best: 6.618538 | Rate: 0.22 | Evals: 95.0%
Iter 10 | Best: 6.618538 | Curr: 16.111614 | Rate: 0.20 | Evals: 100.0%
Best value: 6.618538
Experiment saved to experiments_compare_de_tricands_bfgs/exp_de_res.pkl
Result saved to experiments_compare_de_tricands_bfgs/exp_de_res.pkl
Saved: experiments_compare_de_tricands_bfgs/exp_de_res.pkl
Processing: experiments_compare_de_tricands_bfgs/exp_bfgs_exp.pkl
Loaded experiment from experiments_compare_de_tricands_bfgs/exp_bfgs_exp.pkl
Initial best: f(x) = 24.447486
Iter 1 | Best: 24.447486 | Curr: 115.305737 | Rate: 0.00 | Evals: 55.0%
Iter 2 | Best: 24.447486 | Curr: 73.901317 | Rate: 0.00 | Evals: 60.0%
Iter 3 | Best: 24.447486 | Curr: 25.511124 | Rate: 0.00 | Evals: 65.0%
Iter 4 | Best: 24.447486 | Curr: 80.640861 | Rate: 0.00 | Evals: 70.0%
Iter 5 | Best: 24.447486 | Curr: 42.258181 | Rate: 0.00 | Evals: 75.0%
Iter 6 | Best: 24.447486 | Curr: 32.949358 | Rate: 0.00 | Evals: 80.0%
Iter 7 | Best: 15.174307 | Rate: 0.14 | Evals: 85.0%
Iter 8 | Best: 14.707912 | Rate: 0.25 | Evals: 90.0%
Iter 9 | Best: 14.707912 | Curr: 65.102882 | Rate: 0.22 | Evals: 95.0%
Iter 10 | Best: 14.707912 | Curr: 53.449070 | Rate: 0.20 | Evals: 100.0%
Best value: 14.707912
Experiment saved to experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl
Result saved to experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl
Saved: experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl
Processing: experiments_compare_de_tricands_bfgs/exp_tricands_exp.pkl
Loaded experiment from experiments_compare_de_tricands_bfgs/exp_tricands_exp.pkl
Initial best: f(x) = 24.447486
Iter 1 | Best: 24.447486 | Curr: 60.586280 | Rate: 0.00 | Evals: 55.0%
Iter 2 | Best: 20.457316 | Rate: 0.50 | Evals: 60.0%
Iter 3 | Best: 20.457316 | Curr: 44.287891 | Rate: 0.33 | Evals: 65.0%
Iter 4 | Best: 20.457316 | Curr: 54.350759 | Rate: 0.25 | Evals: 70.0%
Iter 5 | Best: 20.457316 | Curr: 29.059194 | Rate: 0.20 | Evals: 75.0%
Iter 6 | Best: 20.457316 | Curr: 38.314818 | Rate: 0.17 | Evals: 80.0%
Iter 7 | Best: 20.457316 | Curr: 22.880271 | Rate: 0.14 | Evals: 85.0%
Iter 8 | Best: 20.457316 | Curr: 47.526104 | Rate: 0.12 | Evals: 90.0%
Iter 9 | Best: 10.765448 | Rate: 0.22 | Evals: 95.0%
Iter 10 | Best: 10.765448 | Curr: 16.195813 | Rate: 0.20 | Evals: 100.0%
Best value: 10.765448
Experiment saved to experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl
Result saved to experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl
Saved: experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl
All experiments completed. Transfer results back to local machine.
14.8.3 Local Machine (Analysis)
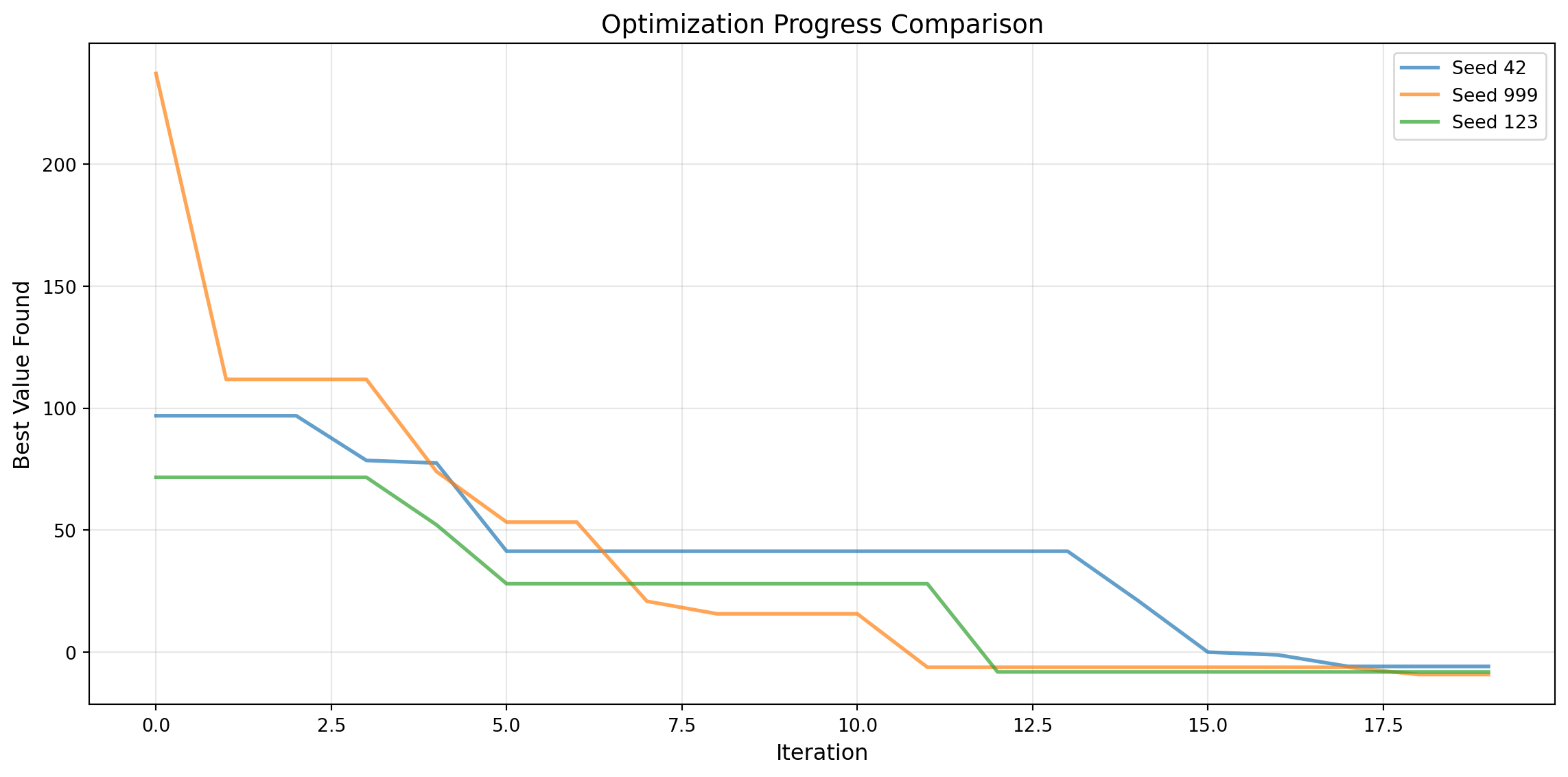
# analyze_results.pyimport numpy as npfrom spotoptim import SpotOptimimport globimport matplotlib.pyplot as plt# Find all result filesresult_files = glob.glob(f"{DIRNAME}/*_res.pkl")print(f"Found {len(result_files)} results to analyze")# Load and compare resultsresults = []for res_file in result_files: opt = SpotOptim.load_result(res_file) results.append({"file": res_file,"best_value": opt.best_y_,"best_point": opt.best_x_,"n_evals": opt.counter,"seed": opt.seed,"acquisition_optimizer": opt.acquisition_optimizer, })print(f"{res_file}: best={opt.best_y_:.6f}, evals={opt.counter}")# Find best overall resultbest =min(results, key=lambda x: x["best_value"])print(f"\nBest result:")print(f" File: {best['file']}")print(f" Value: {best['best_value']:.6f}")print(f" Point: {best['best_point']}")print(f" Seed: {best['seed']}")print(f" Acquisition optimizer: {best['acquisition_optimizer']}")# Plot convergence comparisonplt.figure(figsize=(12, 6))for res_file in result_files: opt = SpotOptim.load_result(res_file) seed = opt.seed acquisition_optimizer = opt.acquisition_optimizer cummin = [opt.y_[:i+1].min() for i inrange(len(opt.y_))] plt.plot(cummin, label=f"{acquisition_optimizer}", linewidth=2, alpha=0.7)plt.xlabel("Iteration", fontsize=12)plt.ylabel("Best Value Found", fontsize=12)plt.title("Optimization Progress Comparison", fontsize=14)plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.savefig(f"{DIRNAME}/convergence_comparison.png", dpi=150)print("\nConvergence plot saved to: {DIRNAME}/convergence_comparison.png")
Found 3 results to analyze
Loaded result from experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl
experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl: best=14.707912, evals=20
Loaded result from experiments_compare_de_tricands_bfgs/exp_de_res.pkl
experiments_compare_de_tricands_bfgs/exp_de_res.pkl: best=6.618538, evals=20
Loaded result from experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl
experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl: best=10.765448, evals=20
Best result:
File: experiments_compare_de_tricands_bfgs/exp_de_res.pkl
Value: 6.618538
Point: [-3.72183897 -1.94716806 1.86706201]
Seed: 42
Acquisition optimizer: differential_evolution
Loaded result from experiments_compare_de_tricands_bfgs/exp_bfgs_res.pkl
Loaded result from experiments_compare_de_tricands_bfgs/exp_de_res.pkl
Loaded result from experiments_compare_de_tricands_bfgs/exp_tricands_res.pkl
Convergence plot saved to: {DIRNAME}/convergence_comparison.png
14.9 Technical Details
14.9.1 Serialization Method
SpotOptim uses Python’s built-in pickle module for serialization. This provides:
Standard library: No additional dependencies required
Compatibility: Works with numpy arrays, sklearn models, scipy functions
Performance: Efficient serialization of large datasets
14.9.2 Component Reinitialization
When loading experiments, certain components are automatically recreated:
Surrogate model: Gaussian Process with default kernel
LHS sampler: Latin Hypercube Sampler with original seed
This ensures loaded experiments can continue optimization without manual configuration.
14.9.3 Excluded Components
Some components cannot be pickled and are automatically excluded:
Objective function (fun): Included (via dill) in both experiment and result files.
TensorBoard writer (tb_writer): File handles cannot be serialized
Surrogate model (experiments only): Recreated on load for experiments
14.9.4 File Format
Files are saved using pickle’s highest protocol:
withopen(filename, "wb") as handle: pickle.dump(optimizer_state, handle, protocol=pickle.HIGHEST_PROTOCOL)
14.10 Troubleshooting
14.10.1 Issue: “AttributeError: ‘SpotOptim’ object has no attribute ‘fun’”
This should not happen if dill is working correctly. If it does, your function might not be picklable. Try defining the function at the top level of your script or module. If all else fails, you can manually re-attach it:
Cause: Attempting to save over an existing file without overwrite=True.
Solution: Either use a different prefix or enable overwriting:
# Option 1: Use different prefixoptimizer.save_result(prefix="my_result_v2")# Option 2: Enable overwritingoptimizer.save_result(prefix="my_result", overwrite=True)
14.10.4 Issue: Results differ after loading
Cause: Random state not preserved or function behavior changed.
Solution: Ensure you’re using the same seed and function definition:
# When savingoptimizer = SpotOptim(..., seed=42) # Use fixed seed# When loading and continuingloaded_opt = SpotOptim.load_result("result_res.pkl")# loaded_opt.fun is already attached